Определение характера
Проблема характера в психологии личности является сравнительно малоисследованной областью. Термин характер был введен в науку древнегреческим ученым Теофастом (4 в. до н.э.). По-гречески характер — это черта, примета, признак, особенность. До Теофаста Аристотель для обозначения деятельной стороны личности использовал слово «этос» — что значит нрав, обычай. История учения о характере показывает разнообразие даже в исходных позициях при определении этой стороны личности.
Понятие характера можно представить в двух значениях: общем (широком) и более специальном.
В широком смысле характер — это индивидуальные ярко выраженные и качественно своеобразные психологические черты человека, влияющие на его поведение и поступки.
А. Ковалев и В. Мясищев определяют характер как индивидуально своеобразное сочетание существенных свойств личности. К.Платонов к характеру относит совокупность наиболее выраженных и относительно устойчивых черт личности, типичных для данного человека и постоянно проявляющихся в его действиях и поступках.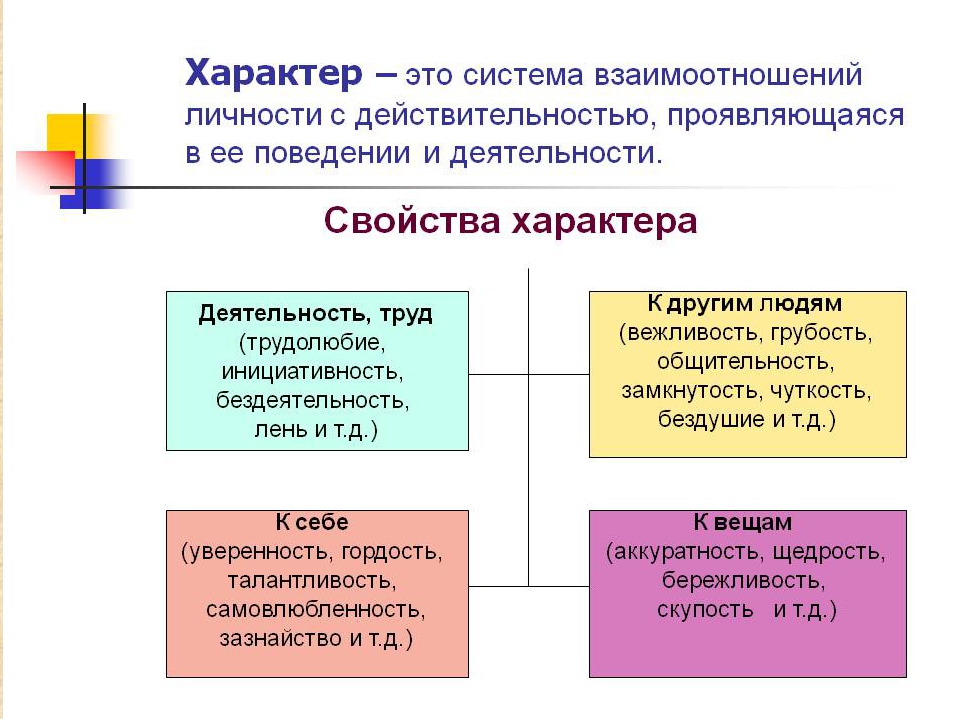
В более узком смысле характер определяется как психический склад личности человека, выраженный в её направленности и воле.
Б.Теплов считает, что характер проявляется как в целях, которые человек ставит, так и в средствах или способах, которыми он эти цели осуществляет. Характер определяется отношением человека к миру, к другим людям, к самому себе. Борис Ананьев к характеру относит те свойства личности, которые отражают основную направленность и проявляются в своеобразном для личности образе действий.
Необходимо различать понятия свойства личности и характера при их близости и иногда совпадении. Характер — это психологическое своеобразие человека, интеграл всех его свойств. В основном характер — это единство отношений и способов их осуществления в переживаниях и поступках человека.
Характер — это психологическое образование, заключающее в себе закрепившиеся эмоциональные отношения человека к типичным жизненным ситуациям и определенным образом связанные с ним стереотипы когнитивных и поведенческих «схем» реагирования на эти ситуации. Характер, как система определенных стереотипов эмоционального, когнитивного, поведенческого реагирования на типичные жизненные ситуации, формируется под сильным воздействием мировоззрения и направленности человека, но не перекрывает. Он определяет реактивное, а не инициативное поведение человека.
Задача изучения структуры характера заключается в выделении и систематизации черт характера и установлении их взаимосвязи.
Под чертами характера понимаются, достаточно показательные для человека и позволяющие с известной вероятностью предугадывать его поведение в том или ином конкретном случае.
Хотя каждая черта характера является чертой личности, далеко не каждая черта личности является чертой характера. Для того, чтобы иметь основания называться чертой характера, черта личности должна быть достаточно выражена, достаточно взаимосвязана с другими чертами характера в одно целое, чтобы систематически проявляется в обязательно различных видах деятельности. Надо отметить, что всякое целое не равно только сумме его элементов, так и характер в целом — это нечто большее, чем просто сумма отдельных черт характера. Характер представляет ту часть структуры личности, в которую входят только черты личности, достаточно выраженные и достаточно связанные друг с другом как целое, чтобы постоянно проявляться в различных видах деятельности.
Надо отметить, что всякое целое не равно только сумме его элементов, так и характер в целом — это нечто большее, чем просто сумма отдельных черт характера. Характер представляет ту часть структуры личности, в которую входят только черты личности, достаточно выраженные и достаточно связанные друг с другом как целое, чтобы постоянно проявляться в различных видах деятельности.
Гордон Олпорт отмечает, что характер и темперамент часто используются как синонимы, и отождествляют с понятием личность. Он указывал, что каждый из них отличается от собственно личности. Слово «характер» вызывает ассоциацию неким моральным стандартом или системой ценностей, в соответствии с которой поступает личность. Например, когда мы слышим, что у человека «хороший характер», то речь идет о том, что личностные качества социально или этически желательны. С точки зрения Олпорта характер — это понятие оценочное и оцененная личность, а личность носит не оценочный характер.
Темперамент, по Олпорту, напротив, является «первичным материалом» (наряду с интеллектом и конституцией), из которого строится личность. Представляя собой один из аспектов генетической данности, темперамент ограничивает развитие индивидуальности. По Олпорту «из свиного уха шелковый кошелек не сошьешь».
Представляя собой один из аспектов генетической данности, темперамент ограничивает развитие индивидуальности. По Олпорту «из свиного уха шелковый кошелек не сошьешь».
8 «плохих» черт характера, с которыми на самом деле не стоит бороться
Принять себя «как есть» — для многих недостижимая цель. Нам внушают, что нужно становиться лучше, избавляться от недостатков или хотя бы их скрывать. В книге «Рецепт счастья: принимайте себя три раза в день» Екатерина Сигитова, врач-психотерапевт с неизлечимым кожным заболеванием — ихтиозом, рассказывает, как научиться любить себя с любыми особенностями и проблемами. Публикуем отрывок о том, почему война с «плохими» чертами характера часто оказывается бесполезна и губительна.
В принятии своего характера важную роль играет валидация. Это подтверждение соответствия некоего выбора или эмоции реальному ходу вещей. Валидация не значит одобрение, попустительство или какие-либо индульгенции. Она, по сути, означает только одно: я признаю, что у тебя/ меня были на это веские причины и иначе было нельзя. Вот как она может работать с вашими «плохими» чертами.
Валидация не значит одобрение, попустительство или какие-либо индульгенции. Она, по сути, означает только одно: я признаю, что у тебя/ меня были на это веские причины и иначе было нельзя. Вот как она может работать с вашими «плохими» чертами.
1. Гиперчувствительность нервной системы
Быть слишком чувствительными — нормально. Мы живём в мире с огромным множеством сигналов, раздражителей и мигающих уведомлений. Мы вынуждены переваривать такое количество общения и нагрузки на органы чувств, какое наши предки не имели за всю свою жизнь. Неудивительно, что у некоторых людей с не очень большим ресурсом развивается своего рода внутренняя защита. Их нервная система довольно быстро начинает сигнализировать о перегрузках. Да и сами эти перегрузки — и эмоциональные, и нервные, и сенсорные — накапливаются в целом быстрее, чем у многих других. К сожалению, это приносит массу проблем «носителям» такой чувствительной нервной системы.
2. Депрессивность
Быть депрессивными — нормально. В последнее время выходит много исследований на тему возникновения депрессии и депрессивного характера. Есть разные теории, но большинство учёных сходятся в одном: никогда не бывает так, чтобы появилась одна-единственная причина и после неё всё пошло не так. Нет, всё сложнее. Люди рождаются с предрасположенностью к депрессии, люди становятся депрессивными из-за перенесённого опыта и особенностей семейного воспитания, люди перенимают ролевые модели своих близких, люди просто могут иметь такой характер.
3. Сложный характер
 д. По моему опыту (не проверяла, подтверждено ли это исследованиями), трудными для других часто бывают те, кому пришлось многое пережить. И у кого по каким-то причинам не вышло переработать и переварить этот тяжёлый опыт, поэтому он осел своеобразным камнем на шее и на всей личности. Чем раньше случились события, которые нужно было переваривать, тем больше на них ушло сил и тем выше вероятность развития «тяжёлого» характера. Он немного корректируется в психотерапии, но полностью другим человеком даже с помощью специалиста стать всё-таки непросто. Поэтому принятие может помочь — убрать хотя бы одну из сложностей, внутренний протест против себя.
д. По моему опыту (не проверяла, подтверждено ли это исследованиями), трудными для других часто бывают те, кому пришлось многое пережить. И у кого по каким-то причинам не вышло переработать и переварить этот тяжёлый опыт, поэтому он осел своеобразным камнем на шее и на всей личности. Чем раньше случились события, которые нужно было переваривать, тем больше на них ушло сил и тем выше вероятность развития «тяжёлого» характера. Он немного корректируется в психотерапии, но полностью другим человеком даже с помощью специалиста стать всё-таки непросто. Поэтому принятие может помочь — убрать хотя бы одну из сложностей, внутренний протест против себя.4. Желание внимания
Хотеть внимания — нормально. Потребность во внимании бывает свойственна людям, которым его в какой-то период жизни (в основном в детстве) не досталось сколько нужно, и этот опыт у них застрял, зафиксировался как основной способ поведения. Видимо, иначе не получилось бы выжить. Чья-то жажда внимания, как правило, сильно раздражает других людей. Есть теория, что раздражает только тех, кто и сам бы не прочь получить побольше, но почему-то не может себе позволить об этом прямо заявить или открыто пытаться привлекать взгляды других людей. Но это не так важно, важнее другое: те, кого чужая жажда раздражает, часто преподносят это как что-то стыдное. Но в этом нет ничего стыдного. Это такая же равноправная особенность личности, как и все другие, основанная на конкретном эмоциональном опыте и способах его в дальнейшем избегать.
Видимо, иначе не получилось бы выжить. Чья-то жажда внимания, как правило, сильно раздражает других людей. Есть теория, что раздражает только тех, кто и сам бы не прочь получить побольше, но почему-то не может себе позволить об этом прямо заявить или открыто пытаться привлекать взгляды других людей. Но это не так важно, важнее другое: те, кого чужая жажда раздражает, часто преподносят это как что-то стыдное. Но в этом нет ничего стыдного. Это такая же равноправная особенность личности, как и все другие, основанная на конкретном эмоциональном опыте и способах его в дальнейшем избегать.
5. Агрессивность, раздражительность, вспыльчивость
Быть агрессивными и вспыльчивыми — нормально. Всем живым существам это свойственно и необходимо для многого, в частности для адекватной защиты. Когда говорят об агрессивности как о личностной черте, обычно имеют в виду, что всего слишком много: человек избыточно обороняется, либо сам(а) нападает, либо у него/неё плохой контроль импульсов и т. п. Генетически обусловленная высокая агрессивность встречается нечасто. Гораздо чаще так ведут себя люди, у которых либо была подобная ролевая модель очень-очень близко в семье, либо (или в сочетании) неадекватная злоба была когда-то применена к ним самим, то есть они были жертвами насилия. Если есть опыт психологической травмы, связанной с насилием, и эта рана не была исцелена (в нашей культуре это нередкая ситуация, увы), то вероятность повышенной агрессии в поведении и в структуре личности пострадавшего человека весьма высокая. Только монстр может победить монстра, поэтому внутри у большинства жертв насилия такой монстр вырастает (увы, победить внешнее зло ему удаётся не всегда…). Понятное дело, потом этот монстр никуда не девается, выпрыгивает тут и там, не особо советуясь с «хозяином». Принятие, как ни странно, помогает лучше справляться со своими раздражительными выплесками, потому что освобождаются силы, которые раньше уходили на попытки отвержения.
п. Генетически обусловленная высокая агрессивность встречается нечасто. Гораздо чаще так ведут себя люди, у которых либо была подобная ролевая модель очень-очень близко в семье, либо (или в сочетании) неадекватная злоба была когда-то применена к ним самим, то есть они были жертвами насилия. Если есть опыт психологической травмы, связанной с насилием, и эта рана не была исцелена (в нашей культуре это нередкая ситуация, увы), то вероятность повышенной агрессии в поведении и в структуре личности пострадавшего человека весьма высокая. Только монстр может победить монстра, поэтому внутри у большинства жертв насилия такой монстр вырастает (увы, победить внешнее зло ему удаётся не всегда…). Понятное дело, потом этот монстр никуда не девается, выпрыгивает тут и там, не особо советуясь с «хозяином». Принятие, как ни странно, помогает лучше справляться со своими раздражительными выплесками, потому что освобождаются силы, которые раньше уходили на попытки отвержения.
6.
 Нечуткость к людям / избыточная эмпатия
Нечуткость к людям / избыточная эмпатияБыть избыточно чуткими, как и недостаточно чуткими, — нормально. Начнём с того, что всё-таки нет никакого эталона чуткости и эмпатичности, несмотря на широкое распространение опросников, это измеряющих, в которых даётся некий «нормальный» диапазон. Нет. Всё дело в адаптации к среде: если вас и ваших близких в основном устраивает ваша способность к эмпатии, то всё в порядке, какой бы балл вы ни заработали. Но в современном обществе, в котором, с одной стороны, модно и престижно иметь высокий эмоциональный интеллект, а с другой — каждый второй бравирует своей похожестью на людей с синдромом Аспергера, пройдя какой-нибудь тест, естественно, как нечуткие люди, так и чуткие имеют множество проблем. Обычно и то и другое родом из раннего детства, из опыта близкого эмоционального сопровождения ребёнка внимательным взрослым. Если что-то в этом сопровождении до 2–3 лет было не так, то это может здорово отразиться на способности чувствовать других людей как в сторону плюса, так и в сторону минуса. Учёные выяснили, что избыточную эмпатию почти совсем нельзя уменьшить, а вот недостаточную можно чуть-чуть отрастить, если, конечно, это не генетически унаследованная штука (так тоже бывает). И конечно же, исследования показывают, что принятие себя как есть помогает в обоих случаях.
Учёные выяснили, что избыточную эмпатию почти совсем нельзя уменьшить, а вот недостаточную можно чуть-чуть отрастить, если, конечно, это не генетически унаследованная штука (так тоже бывает). И конечно же, исследования показывают, что принятие себя как есть помогает в обоих случаях.
7. Завистливость
Завидовать — нормально. Моя коллега Полина Гавердовская блестяще определила здоровую зависть: «…Это чувство, которое при помощи боли показывает, чего тебе не хватает для счастья». В обществе считается, что завидовать плохо и стыдно. Поэтому многим людям трудно принимать это в себе. Но с психологической точки зрения завидовать нормально: это показывает либо уровень ваших притязаний (т. е. насколько многого вам не хватает), либо уровень вашей душевной зрелости (т. е. в состоянии ли вы переживать эту боль «отсутствия желаемого» без злости). Зависть бывает двух видов: зависть-восхищение с положительными эмоциями — «Круто! Вот бы мне так!» (её часто называют белой или зрелой) и зависть-ненависть — желание уничтожения объекта или разрушения того, чем он обладает (носит название чёрной или детской). Принятие этого чувства может помочь войти в контакт с его причинами — тем, чего не хватает, или каким-то личностным фоном, который перерабатывает чужие успехи именно этим способом. И станет легче, правда.
Принятие этого чувства может помочь войти в контакт с его причинами — тем, чего не хватает, или каким-то личностным фоном, который перерабатывает чужие успехи именно этим способом. И станет легче, правда.
8. Травмированность
Нести на себе следы перенесённой травмы — нормально. Травма — это по определению что-то такое, что не может не оставить отпечатка. Обычно под признаками травмированности понимают неадекватные реакции, перепады эмоций, ранимость, слабость и «позицию жертвы». Увы, всё это — естественные шрамы от травмирующего воздействия (т. е. непреодолимой на тот момент силы), и они иногда остаются даже у тех, кто прошёл лечение. Но общество не любит тех, кто требует особого подхода, поэтому в числе прочих уязвимых групп оно стыдит пострадавших за то, что по ним заметна их травма. Из-за этого и из-за стыда и вины, сопровождающих саму травму, невероятно трудно принимать в себе травмированность. Даже не то что трудно — совсем не хочется. Хотя принятие здесь поможет как нигде, потому что наш самовосстановительный процесс полностью зависит от того, насколько мы к себе добры, насколько мы себя принимаем.
Даже не то что трудно — совсем не хочется. Хотя принятие здесь поможет как нигде, потому что наш самовосстановительный процесс полностью зависит от того, насколько мы к себе добры, насколько мы себя принимаем.
Лайфхаки по принятию себя
Учитесь отделять ярлыки «плохой» и «хороший» от конкретных поступков и свойств характера. Когда мы не знаем о ценности каждой своей части, мы бессознательно склеиваемся с этими ярлыками и потом обрушиваемся сами же на себя всей мощью. Так что не поддавайтесь. Не «Я плохой/плохая, потому что я конфликтный/конфликтная», а «Я конфликтный/конфликтная, но всё равно я хороший/хорошая».
Разграничивайте вину и ответственность. За всё — за последствия ваших поступков и за особенности характера. Ответственность — это размер нашего вклада в ситуацию, а вина — его моральная оценка. Второе нужно не всегда! Отцепите этот вагон, и пусть он постоит где-нибудь на запасных путях.
Выращивайте в себе противовесы. Например, внутреннюю Добрую Бабушку, которая говорит про ваш характер всё только хорошее (и про «плохие» его черты тоже находит что сказать положительное!). Пусть противовес будет хотя бы размером с ладошку, а лучше побольше. Да, это возможно, хоть и занимает время.
Избавляйтесь от привычки ориентироваться «по самому хорошему дню», когда планируете свою занятость и пишите списки дел. Хорошие дни, в которые у вас много энергии и вы многое успеваете и не очень много проявляете свои «отрицательные» личностные качества, — исключение. Вместо этого ориентируйтесь по самому плохому дню, когда вы тупили, уставали, делали всё как обычно и ваше типичное свойство характера торчало во все стороны. Все другие дни — бонусы!
Юмор – лучшее лекарство. Ну, почти. Научитесь подшучивать над своими «негативными» личностными чертами. Делайте это по-доброму, но с таким знанием себя, которое только вы можете обеспечить, — и вам сразу станет легче жить. Можно искать шутки где-нибудь в интернете, можно сочинять их самим. Смеясь над собой, мы все немножечко освобождаемся. А этого очень не хватает.
Можно искать шутки где-нибудь в интернете, можно сочинять их самим. Смеясь над собой, мы все немножечко освобождаемся. А этого очень не хватает.
Отрывок предоставлен для публикации издательством «Альпина Паблишер».
«Сегодня был и характер, и настрой – это командная победа». Цитаты дня : Новости : Континентальная Хоккейная Лига (КХЛ)
Комментарии хоккеистов и тренеров по итогам матчей игрового дня регулярного чемпионата КХЛ.
«Металлург» — «Нефтехимик» 3:4
Вячеслав Буцаев, главный тренер «Нефтехимика»:
– Матч получился интересным, захватывающим. К середине второго периода ничего не предвещало сложностей. Сами себе их создали. Два ненужных удаления. Сильная сторона соперника – игра в большинстве. Хорошо, что в третьем периоде сумели хорошо сыграть не только по счёту, но и по игре. Такие матчи надо выигрывать, в одну шайбу, терпеливо – это очень хорошо. Победа за счёт характера? Наверное, в игре не бывает чего-то одного: мастерства, характера, везения. Сегодня был и характер, и настрой – это командная победа. Игра в меньшинстве? Я уже сказал – большинство – одна из сильных сторон соперника. Нужно уметь правильно и грамотно играть – просчитывать, предугадывать. Будем над этим работать. Бякин? Не для кого не открою Америки – знаете, что происходило в командах. Он набирал форму после болезни. Как стал готов, получил место в составе. Молодец, хорошо сыграл. Порядин? Жив. Здоров? Посмотрим – пока нет конкретной информации.
Такие матчи надо выигрывать, в одну шайбу, терпеливо – это очень хорошо. Победа за счёт характера? Наверное, в игре не бывает чего-то одного: мастерства, характера, везения. Сегодня был и характер, и настрой – это командная победа. Игра в меньшинстве? Я уже сказал – большинство – одна из сильных сторон соперника. Нужно уметь правильно и грамотно играть – просчитывать, предугадывать. Будем над этим работать. Бякин? Не для кого не открою Америки – знаете, что происходило в командах. Он набирал форму после болезни. Как стал готов, получил место в составе. Молодец, хорошо сыграл. Порядин? Жив. Здоров? Посмотрим – пока нет конкретной информации.
Фредрик Стиллман, и. о. главного тренера «Металлурга»:
– Мы хотим побеждать в каждой игре, но такова жизнь – не всегда получается. Сегодня мы были чуть медленными. В прошлых играх мы были быстрее. И сегодня не хватило скорости для победы. Плохой второй период – когда пропустили три гола подряд, но потом сумели выровнять игру. Много приложили усилий, чтобы отыграться. Жаль, что этого не было достаточно, чтобы выиграть. Кошечкин? Сложно объяснить. Все мы люди, бывает всякое. Понятно, что любой голкипер пытается поймать каждую шайбу. Но это не всегда получается. Сегодня было много потерь шайбы, неточных передач и других аспектов, в которых у нас не всё получалось. Не стану говорить, что вратарь виноват. Повторюсь, мы приложили немало усилий, чтобы отыграться , но многое не получилось в командных действиях. Но немного не повезло. Не было ли соблазна заменить Кошечкина, чтобы взбодрить игру? Такая мысль была, конечно. Я чувствовал, что могу дать Василию ещё шанс на реванш. И действительно после этого он был надёжен.
Много приложили усилий, чтобы отыграться. Жаль, что этого не было достаточно, чтобы выиграть. Кошечкин? Сложно объяснить. Все мы люди, бывает всякое. Понятно, что любой голкипер пытается поймать каждую шайбу. Но это не всегда получается. Сегодня было много потерь шайбы, неточных передач и других аспектов, в которых у нас не всё получалось. Не стану говорить, что вратарь виноват. Повторюсь, мы приложили немало усилий, чтобы отыграться , но многое не получилось в командных действиях. Но немного не повезло. Не было ли соблазна заменить Кошечкина, чтобы взбодрить игру? Такая мысль была, конечно. Я чувствовал, что могу дать Василию ещё шанс на реванш. И действительно после этого он был надёжен.
Михаил Бякин, нападающий «Нефтехимика»:
– Игру хорошо начали. У нас сразу было преимущество 4:1. Из-за ненужных удалений пропустили две шайбы за шесть минут. Игра сразу стала тяжелее. Но дотерпели, дожали и выиграли. Как адаптировался в КХЛ? До этого играл одну игру, но там мало играл. Здесь тренер доверил больше времени. Первые смены переживал. Но к третьей смене это прошло, почувствовал игру, вкатился, нормально. Фамилия помогает или мешает? Конечно, много, кто любит говорить, что играю из-за фамилии. Но я стараюсь не обращать внимания и показывать свою игру. Трудности, с которыми столкнулась команда? Я бы не сказал, что было тяжеловато психологически. Да, проигрывали. Но мы настроены только на победу. Забываем о поражениях и выходим только выигрывать. Сейчас набрали форму после болезней, думаю, всё будет хорошо. Дубль, которого в итоге не получилось? Не увидел, что Галузин подставлял, если честно. И он тоже промолчал. Но я не расстроился. Наоборот, когда объявили, что забил не я – появились эмоции повторить, забить ещё. И получилось!
Здесь тренер доверил больше времени. Первые смены переживал. Но к третьей смене это прошло, почувствовал игру, вкатился, нормально. Фамилия помогает или мешает? Конечно, много, кто любит говорить, что играю из-за фамилии. Но я стараюсь не обращать внимания и показывать свою игру. Трудности, с которыми столкнулась команда? Я бы не сказал, что было тяжеловато психологически. Да, проигрывали. Но мы настроены только на победу. Забываем о поражениях и выходим только выигрывать. Сейчас набрали форму после болезней, думаю, всё будет хорошо. Дубль, которого в итоге не получилось? Не увидел, что Галузин подставлял, если честно. И он тоже промолчал. Но я не расстроился. Наоборот, когда объявили, что забил не я – появились эмоции повторить, забить ещё. И получилось!
Михаил Пашнин, защитник «Металлурга»:
– Начало было хорошее, но второй период проиграли. Из-за этого и сложилось поражение. Как мы не включали характер, ноги-руки, догоняли – не получилось догнать. Надо было не совершать ошибок, которые привели к поражению. Поздно включились? В голове не было проблемы. Повторюсь: пропустили контратаки, и потом было поздно. Могли забить, но хоккей такая игра – если упустил свой шанс, редко появляется второй. Сложно ли перестраиваться под новые звенья атаки? Нам нисколько не трудно. Мы по ходу игры выходим с любой тройкой, играем по кругу. Сегодня немного сыграли не по заданию. За ошибки нас наказали. Сложный график? Это чувствуется. Потому что два месяца играем как в плей-офф. Но тренерский штаб нам даёт выходные между играми, не нагружает – тренеры понимают, что игр много, через день. Есть время восстановиться. С другой стороны, для болельщиков здорово, что много матчей, да и мы находимся в тонусе.
Поздно включились? В голове не было проблемы. Повторюсь: пропустили контратаки, и потом было поздно. Могли забить, но хоккей такая игра – если упустил свой шанс, редко появляется второй. Сложно ли перестраиваться под новые звенья атаки? Нам нисколько не трудно. Мы по ходу игры выходим с любой тройкой, играем по кругу. Сегодня немного сыграли не по заданию. За ошибки нас наказали. Сложный график? Это чувствуется. Потому что два месяца играем как в плей-офф. Но тренерский штаб нам даёт выходные между играми, не нагружает – тренеры понимают, что игр много, через день. Есть время восстановиться. С другой стороны, для болельщиков здорово, что много матчей, да и мы находимся в тонусе.
ЦСКА – СКА 3:1
Роман Ротенберг, и.о. главного тренера СКА:
— Мы сегодня не получили той энергии, на которую рассчитывали. Наше состояние пока не идеальное, не смогли показать высокие скорости. Где-то допустили невынужденные ошибки, не свойственные нам. Например, в матче с «Ак Барсом» мы совершили их куда меньше. Сопернику отдам должное: он хорошо сыграл тактически, был силён физически. Мы будем работать над ошибками, разочаровывает факт, что пропустили две шайбы в меньшинстве. У нас высокие задачи, нам надо подвести команду к чемпионской игре. Мы даём шанс многим игрокам, некоторые хоккеисты ещё восстанавливаются, ждём их. Обязательно будем давать шанс молодым при этом, мы видели, как они проявили себя в прошлых матчах. Ткачёв восстанавливается функционально, у нас много хоккеистов, которые получили очень много игрового времени на выезде. Мы смотрим по кондициям, кто готов выходить на лёд. Надо смотреть и разговаривать с медицинским штабом, кто вернётся к домашней серии. Мы постоянно мониторим ситуацию, на врачей легла огромная нагрузка в нынешней ситуации. Мы постоянно общаемся с Валерием Брагиным и надеемся на его скорейшее возвращение в строй.
Сопернику отдам должное: он хорошо сыграл тактически, был силён физически. Мы будем работать над ошибками, разочаровывает факт, что пропустили две шайбы в меньшинстве. У нас высокие задачи, нам надо подвести команду к чемпионской игре. Мы даём шанс многим игрокам, некоторые хоккеисты ещё восстанавливаются, ждём их. Обязательно будем давать шанс молодым при этом, мы видели, как они проявили себя в прошлых матчах. Ткачёв восстанавливается функционально, у нас много хоккеистов, которые получили очень много игрового времени на выезде. Мы смотрим по кондициям, кто готов выходить на лёд. Надо смотреть и разговаривать с медицинским штабом, кто вернётся к домашней серии. Мы постоянно мониторим ситуацию, на врачей легла огромная нагрузка в нынешней ситуации. Мы постоянно общаемся с Валерием Брагиным и надеемся на его скорейшее возвращение в строй.
Игорь Никитин, главный тренер ЦСКА:
— Поблагодарил ребят за хорошую игру. Качественный хоккей показали сегодня, соперник был непростой. Мы правильно отреагировали на два подряд поражения, готовимся к матчу с «Динамо». Вопрос к судьям, почему у нас было так много удалений. Парни сражались, не думаю, что мы были менее дисциплинированными, чем СКА. Отработали десять минут в меньшинстве, спецбригада — молодцы. Рождение ребёнка – особенно событие в жизни любого мужчины. Возможно, поэтому он сегодня играл так. Плюс он не выходил в Хельсинки, и мог быть свежее. У нас сейчас ситуация, как в плей-офф. Кто-то проводит по семь матчей подряд, кто-то три –четыре, а потом долго отдыхает. Нам надо использовать этот опыт.
Мы правильно отреагировали на два подряд поражения, готовимся к матчу с «Динамо». Вопрос к судьям, почему у нас было так много удалений. Парни сражались, не думаю, что мы были менее дисциплинированными, чем СКА. Отработали десять минут в меньшинстве, спецбригада — молодцы. Рождение ребёнка – особенно событие в жизни любого мужчины. Возможно, поэтому он сегодня играл так. Плюс он не выходил в Хельсинки, и мог быть свежее. У нас сейчас ситуация, как в плей-офф. Кто-то проводит по семь матчей подряд, кто-то три –четыре, а потом долго отдыхает. Нам надо использовать этот опыт.
Василий Подколзин, форвард СКА:
Мы бились и сражались. По желанию и самоотдаче нет претензий. Пропустили необязательный гол в начале. Будем работать дальше. Все работают на команду, кто-то зарабатывает удаления, кто-то выходит на большинство.
Евгений Тимкин, форвард СКА:
— Проиграли важный матч. Не получилось забить голы. Надо было переламывать ход игры, случился такой момент, что вступил в драку с Сергеем Андроновым. Оппонент так действовал, что не получилось провести удар, а пришлось бороться.
Оппонент так действовал, что не получилось провести удар, а пришлось бороться.
Константин Окулов, форвард ЦСКА:
— Очень хорошая игра, сильный соперник. Здорово сыграли, друг другу помогали, был хороший эмоциональный заряд. Это один из лучших матчей в сезоне. Ребята уже пошутили в раздевалке: если бы жена родила трёх, то сегодня сделал бы хет-трик. А жена написала, что счастлива из-за моих голов. Если серьёзно, то если появляются такие возможности, то надо их реализовывать. В третьем периоде был ещё один хороший момент, внутренний эгоизм сыграл, после этого извинился перед партнёром. Потом вылезал из-за ворот на пятачок – тоже хороший момент.
Сергей Андронов, форвард ЦСКА:
— Хорошая игра, хороший темп, здорово действовали в обороне. То, что выстояли втроём в конце первого периода – один из ключевых моментов матча, он завёл нас. Я ехал на смену, мы столкнулись с Тимкиным, а дальше получилось, как получилось. Особенно не было времени разбираться. Поздравили Костю с рождением детей, это важное событие. Но Окулов поздравил сегодня сам себя, забросив две шайбы.
Поздравили Костю с рождением детей, это важное событие. Но Окулов поздравил сегодня сам себя, забросив две шайбы.
«Динамо» Минск – «Локомотив» 0:1
Андрей Скабелка, главный тренер «Локомотива»:
— Очень тяжёлый матч, не очень зрелищный. У нас очень мало что получалось в атаке, это касается и большинства. Результатом мы довольны, ну а качеством…Мы передохнём после серии из шести матчей, перезагрузимся и пойдём дальше. Состав «Динамо» целиком из белорусских игроков? В одном отдельно взятом матче это здорово. Но в целом я думаю, что ушедшие на карантин игроки «Динамо» определяли лицо и результат команды, а белорусские ребята им здорово помогали. Сегодня эти ребята получили шанс проявить себя, но на длинной дистанции им будет сложно. Хотя для сборной Беларуси это плюс.
Крэйг Вудкрофт, главный тренер минского «Динамо»:
— Получилась тяжёлая игра. У нас было очень много молодых ребят, им было сложно из-за отсутствия сыгранности. Но хочу отметить наш хороший характер, мы дрались до конца игры, ребята выложились полностью. Мы играли с командой, у которой был полный состав, у нас была только четверть основного состава. Обидно получать такую шайбу — сутолока и гол. Такая была игра, с этим ничего не сделать. Мы свои моменты не забили, «Локомотив» свой шанс реализовал. Я очень доволен своими ребятами, они показали, на что способны.
Мы играли с командой, у которой был полный состав, у нас была только четверть основного состава. Обидно получать такую шайбу — сутолока и гол. Такая была игра, с этим ничего не сделать. Мы свои моменты не забили, «Локомотив» свой шанс реализовал. Я очень доволен своими ребятами, они показали, на что способны.
Дебют в КХЛ Игоря Ревенко и Виталия Пинчука? Парни хорошо влились в состав, хорошо себя проявили. Для Пинчука это большой шаг в карьере, попробовать себя в Континентальной хоккейной лиге. Мы знали, что у него получится. Ревенко очень умный игрок, профессионал. Мы понимали, что сможет помочь команде.
Толопило провёл отличный матч, он держал нас в игре. Я очень рад его выступлению. Никита может быть довольным своей игрой.
Меньшинство – процесс, который нам ещё предстоит изучить. Но сегодня ребята действовали отлично, блокировали все броски, не давали пройти нашу синюю линию. Я более чем доволен игрой молодых ребят.
Некоторые удаления сегодня вызывают интерес. Необычные решения судей. Но хоккей – игра, на которую все смотрят по-разному. Часть удалений была от неуверенности наших молодых ребят.
Необычные решения судей. Но хоккей – игра, на которую все смотрят по-разному. Часть удалений была от неуверенности наших молодых ребят.
Кто и когда из отсутствующих игроков вернётся в состав – это очень индивидуально. Мы разработали индивидуальные планы для каждого из заболевших хоккеистов, привезли им домой велосипеды и гантели, чтобы ребята поддерживали себя в форме. Самое важное – мы должны просто ждать и смотреть на ситуацию.
Илья Шинкевич, защитник минского «Динамо»:
— Нам немного не хватило жёсткости в своей зоне при переводе шайбы. В этом плане мы уступали. А так команда хорошо двигалась, были моменты, хорошо матч провели.
Игорь Ревенко, нападающий минского «Динамо»:
— Немного не хватило концентрации в моменте с пропущенной шайбой. По игре сказать – только положительные эмоции. Минимум на очко мы сегодня наиграли. Обидно уступать за две минуты до конца.
Виталий Пинчук, нападающий минского «Динамо»:
— Не хватило чуть-чуть удачи. Не смогли реализовать моменты, надо было поменьше удаляться. Точно могли забирать очко.
Не смогли реализовать моменты, надо было поменьше удаляться. Точно могли забирать очко.
«Торпедо» — «Автомобилист» 2:3 Б
Дэвид Немировски, главный тренер «Торпедо»:
— Равная игра. К сожалению, во втором периоде у нас было три меньшинства, которые мы выстояли. А потом допустили ошибки на синей линии, что привело к первому голу в наши ворота. Затем пропустили вторую шайбу… Надо уметь правильно играть при счёте 1:0. Перед третьим периодом сказали ребятам, что во втором периоде сами делали игру сложнее для себя и что надо вернуться к намеченному плану. В третьем периоде здорово сыграли, сравняли счёт и могли ещё забивать, но проиграли по буллитам. В целом доволен командой, будем готовиться к выездной серии. Изначально планировали сегодня поставить в ворота Андрея Тихомирова и он сыграл сильно. Артём Аляев пропустил игру из-за травмы.
Билл Питерс, главный тренер «Автомобилиста»:
— Сложная игра, в которой соперник нам создал много проблем. Мы сумели выровнять игру ближе к середине матча, реализовав свои моменты. Нелегко пришлось в конце игры. Дважды мы играли в меньшинстве, но смогли выстоять и добиться положительного результата. Если разбирать два наших нарушения численного состава, то в первом моменте действительно игрок выскочил раньше, а в овертайме шла атака «три в два» и наш игрок был без клюшки, поэтому другой хоккеист выскочил на лёд раньше времени. Такие моменты порой случаются. Не думаю, что это проблема с дисциплиной. Их надо разобрать и исключить в дальнейшем. Большое количество бросков нашей команды во втором периоде скорее всего связано с тем, что в первом периоде «Торпедо» играло в большинстве, а во втором уже мы имели несколько попыток реализации лишнего. Ну а в третьем периоде была равная борьба, в которой моменты были у обеих команд.
Мы сумели выровнять игру ближе к середине матча, реализовав свои моменты. Нелегко пришлось в конце игры. Дважды мы играли в меньшинстве, но смогли выстоять и добиться положительного результата. Если разбирать два наших нарушения численного состава, то в первом моменте действительно игрок выскочил раньше, а в овертайме шла атака «три в два» и наш игрок был без клюшки, поэтому другой хоккеист выскочил на лёд раньше времени. Такие моменты порой случаются. Не думаю, что это проблема с дисциплиной. Их надо разобрать и исключить в дальнейшем. Большое количество бросков нашей команды во втором периоде скорее всего связано с тем, что в первом периоде «Торпедо» играло в большинстве, а во втором уже мы имели несколько попыток реализации лишнего. Ну а в третьем периоде была равная борьба, в которой моменты были у обеих команд.
Антон Шенфельд, нападающий «Торпедо»:
— Как и Екатеринбурге, получилась тяжёлая упорная игра. Всё решили мелочи. В буллитах нам сегодня не повезло. Во втором периоде отдали инициативу сопернику. Был ряд спорных удалений, которые сломали нам игру. В третьем добавили в движении и агрессии, что и принесло свои плоды. Мы сыграли два упорных матча с лидером КХЛ и в очередной раз доказали, что играть можно с любой командой. С сильными соперниками играть всегда интереснее. Проверить себя и показать на что ты способен. Не знали перед игрой, что вышло постановление играть в Нижнем Новгороде без зрителей. Это очень грустно. От болельщиков всегда чувствуем поддержку. Это наш шестой полевой игрок. В Нижнем Новгороде всегда громко и горячо поддерживают команду. Нам будет очень не хватить их на играх.
Во втором периоде отдали инициативу сопернику. Был ряд спорных удалений, которые сломали нам игру. В третьем добавили в движении и агрессии, что и принесло свои плоды. Мы сыграли два упорных матча с лидером КХЛ и в очередной раз доказали, что играть можно с любой командой. С сильными соперниками играть всегда интереснее. Проверить себя и показать на что ты способен. Не знали перед игрой, что вышло постановление играть в Нижнем Новгороде без зрителей. Это очень грустно. От болельщиков всегда чувствуем поддержку. Это наш шестой полевой игрок. В Нижнем Новгороде всегда громко и горячо поддерживают команду. Нам будет очень не хватить их на играх.
Данил Воеводин, нападающий «Торпедо»:
— Хорошая игра с лидером КХЛ. Немного не хватило нам везения в буллитах. Во втором периоде немного подсели из-за удалений, а на третий период тренеры дали установку играть активнее. Когда убегал забивать гол, изначально хотел исполнить этот финт, который иногда делаю на тренировках.
Брэйди Остин, защитник «Торпедо»:
— У нас была возможность сегодня выиграть, играя в большинстве в овертайме. Мы старались, но чуть-чуть не получилось. Что касается моей игры, то когда вернулся после болезни, играл не самым лучшим образом. Сейчас с каждой игрой мне становится легче, и моя игра возвращается на прежний уровень.
Павел Дацюк, нападающий «Автомобилиста»:
— Два периода хорошо играли, было много моментов. Не знаю что случилось в третьем периоде. Начали откатываться, дали много пространства быстрым игрокам «Торпедо». Они почувствовали уверенность, начали наседать и вынудили нас удаляться. Из-за этого игра сломалась и изменилась. Здорово, что сумели перевести игру в овертайм и довести дело до буллитов. А буллиты — это лотерея. Считаю ли я хоккей искусством и себя артистом? Спасибо за сравнения, но на самом деле это не так легко даётся, как кажется. Но наша главная задача помимо победы и командой игры это болельщики. Главное, чтобы они уходили после матча и думали о том, как было бы замечательно отдать сына заниматься такой замечательной игрой как хоккей. Есть ли планы пойти по стопам Яромира Ягра и уехать на следующий сезон в НХЛ? Ягр легендарный игрок и поставил хороший рекорд, но у меня, слава Богу, есть дети, и я планирую заняться их воспитанием. Что касается присутствия болельщиков на трибунах – даже когда их 30 процентов, даже когда на выезде они болеют против тебя, их присутствие стимулирует играть и добавляет энергии. Отсутствие болельщиков на трибунах – большая потеря. Игроки и тренер говорят, что я постоянно подсказываю и даю советы? Да это так. Конечно, иногда эмоции захлёстывают, но я стараюсь всегда подсказывать в хорошем тоне, чтобы нам было легче и была польза для команды.
Есть ли планы пойти по стопам Яромира Ягра и уехать на следующий сезон в НХЛ? Ягр легендарный игрок и поставил хороший рекорд, но у меня, слава Богу, есть дети, и я планирую заняться их воспитанием. Что касается присутствия болельщиков на трибунах – даже когда их 30 процентов, даже когда на выезде они болеют против тебя, их присутствие стимулирует играть и добавляет энергии. Отсутствие болельщиков на трибунах – большая потеря. Игроки и тренер говорят, что я постоянно подсказываю и даю советы? Да это так. Конечно, иногда эмоции захлёстывают, но я стараюсь всегда подсказывать в хорошем тоне, чтобы нам было легче и была польза для команды.
Алексей Василевский, защитник «Автомобилиста»:
— Очень много удалений сегодня было с нашей стороны. Хорошо отыграли бригады меньшинства и Якуб Коварж, наш вратарь. Когда забивал гол, держал в уме свою ошибку в первом периоде и хотел исправить ситуацию. Не знаю получилось или нет. Но как бы то ни было мы сегодня выиграли.
«Сочи» — «Амур» — 3:4 Б
Сергей Светлов, главный тренер «Амура»:
— Сегодня была непростая игра, начало прошло не так как хотели. Проигрывали 0:2, второй гол подзавел команду. Скамейка ожила, стали активнее, агрессивнее, могли зацепиться за победу в основное время. Благодарен ребятам, что выстояли в меньшинстве в концовке и овертайме. Игрой доволен, едем домой с хорошим настроением.
Проигрывали 0:2, второй гол подзавел команду. Скамейка ожила, стали активнее, агрессивнее, могли зацепиться за победу в основное время. Благодарен ребятам, что выстояли в меньшинстве в концовке и овертайме. Игрой доволен, едем домой с хорошим настроением.
Евгений Ставровский, главный тренер «Сочи»:
— Удаления сломали нам игру, невынужденные ошибки. Самоотдача парней понравилась, работать будет легко, желание у них огромное. Все получится. Предложение возглавить «Сочи» стало неожиданностью – как снег на голову. Волнение присутствовало в начале матча, но потом вошёл в ритм. Плохо знаю ещё ребят, но в ближайшее время это исправим.
Денис Голубев, нападающий «Амура»:
— С ребятами и тренерами говорили о том, что нужна победа. Давно не побеждали, проехали выезд и два поражения, нужно в хорошем настроении вернуться домой. Выстояли в меньшинстве в конце игре, а по буллитам довело дело до победы.
Даниил Мироманов, защитник «Сочи»:
— Обидное поражение, должны были выигрывать. Подвела нас дисциплина, было хорошее начало, затем пропустили три гола, но смогли отыграться. Могли и должны были выигрывать в овертайме, но проиграли, к сожалению, по буллитам. Новый тренер сказал, чтобы играли проще, меньше ошибались на синих линиях, подкорректировали выход из зон, давление.
Подвела нас дисциплина, было хорошее начало, затем пропустили три гола, но смогли отыграться. Могли и должны были выигрывать в овертайме, но проиграли, к сожалению, по буллитам. Новый тренер сказал, чтобы играли проще, меньше ошибались на синих линиях, подкорректировали выход из зон, давление.
«Ак Барс» — «Барыс» — 0:1 ОТ
Юрий Михайлис, главный тренер «Барыса»:
— Команда была готова к тяжёлой борьбе, она и получилась в матче, особенно во втором периоде, когда соперник закрыл нас в зоне. В одном из моментов около двух минут не могли поменяться. Но на характере и силе воли мы выстояли, в третьем периоде шла равная игра с моментами как у нас, так и у «Ак Барса». В овертайме мастерство Дица и Старченко решили исход матча.
— Три победы подряд в овертайме – стечение обстоятельств?
— Почему? Команда нашла свой ритм, физически готова, есть характер, удалось подтянуть дисциплину, игроки думают на льду, больше атакуют. Так что здесь я бы говорил о закономерности.
Дмитрий Квартальнов, главный тренер «Ак Барса»:
— Хорошая игра, хорошее движение, но не забили. Вратарь «Барыса» оставил свою команду в игре. Но ноль голов… Надо забивать. Моменты были, и по движению из последних домашних это была самая интересная игра. Да, я понимаю, мы недобираем очки, но сегодняшняя игра была близка к той, которую хотим видеть. Есть состав, который выходит, бьётся. Многие ребята отсутствуют, с этим ничего не поделаешь. Большая нагрузка на лидеров, но, полагаю, надо им сыграть побольше времени в большинстве, чтобы с них можно было спрашивать. Тяжёлый календарь, но мы принимаем его таким, какой он есть, и работаем дальше.
Джастин Азеведо, нападающий «Ак Барса»:
— Думаю, мы сыграли неплохо, много владели шайбой, в том числе и в зоне «Барыса», но вратарь соперника провёл отличный матч, не дав нам отличиться.
Александр Бурмистров, нападающий «Ак Барса»:
— Наверное, это самое обидное поражение за долгое время, за несколько сезонов. Доминировали на протяжении всего матча, но где-то не получилось сделать то, что хотели. Но не смогли забить и допустили ошибку в овертайме. Почему не удалось забить? Сейчас трудно сказать, но забивать мы были обязаны. Может быть, мало накатывались на ворота. «Барыс» играл впятером перед своими воротами, соперники пытались поймать шайбу на себя, и вратарь сыграл неплохо. Но не стоит оценивать чужую игру, надо оценивать свою.
Доминировали на протяжении всего матча, но где-то не получилось сделать то, что хотели. Но не смогли забить и допустили ошибку в овертайме. Почему не удалось забить? Сейчас трудно сказать, но забивать мы были обязаны. Может быть, мало накатывались на ворота. «Барыс» играл впятером перед своими воротами, соперники пытались поймать шайбу на себя, и вратарь сыграл неплохо. Но не стоит оценивать чужую игру, надо оценивать свою.
Амир Мифтахов, вратарь «Ак Барса»:
— Даже несмотря на то, что заброшена в матче была лишь одна шайба, игру не назовёшь скучной. Хорошие моменты были у обеих команд. Так получилось, что дошло до овертайма, где удача улыбнулась сопернику.
Этот кризис носит прежде всего гуманитарный характер, который требует солидарности
Мы стоим перед лицом невиданного за всю 75-летнюю историю существования Организации Объединенных Наций глобального кризиса в области здравоохранения — кризиса, который множит человеческие страдания, заражает глобальную экономику и в корне меняет жизнь людей.
Можно практически с полной уверенностью сказать, что во всем мире наступит спад, масштабы которого, вполне вероятно, будут беспрецедентными.
Международная организация труда только что сообщила, что к концу текущего года сокращение доходов работников во всех странах мира может составить до 3,4 трлн долл. США.
Этот кризис носит прежде всего гуманитарный характер, который требует солидарности.
Наша человеческая семья находится в состоянии стресса, когда рвется ткань общественных отношений. Люди заболевают, страдают и испытывают страх.
Принимаемые в настоящее время странами меры реагирования не учитывают глобальные масштабы и сложный характер кризиса.
Сейчас от ведущих экономик мира требуются скоординированные, решительные и новаторские действия в области политики. Мы должны признать, что больше всего пострадают беднейшие страны и наиболее уязвимые группы населения, особенно женщины.
Я приветствую решение лидеров «Группы двадцати» созвать на следующей неделе чрезвычайный саммит для выработки ответа на эпохальные вызовы, связанные с пандемией COVID-19, и с интересом жду возможности принять в нем участие.
Я считаю очевидным, что мы находимся в беспрецедентной ситуации, в которой обычные правила не действуют. В такие необычные времена мы не можем использовать обычные средства.
Уникальный характер кризиса требует творческого подхода к реагированию, а его масштабы требуют столь же масштабных ответных мер.
Наш мир столкнулся с общим врагом. Мы находимся в состоянии войны с вирусом.
Инфекция COVID-19 убивает людей, а также подтачивает основу основ реальной экономики — торговлю, цепочки снабжения, предприятия, рабочие места. Блокированы целые страны и города. Закрываются границы. Компании борются за то, чтобы не разориться, а семьи просто борются за то, чтобы выжить.
Одновременно с этим преодоление этого кризиса открывает перед нами уникальную возможность.
Правильная постановка дела даст нам возможность направить процесс восстановления по более устойчивому и всеохватному пути. В то же время проведение несогласованной политики чревато закреплением или даже усилением и без того неприемлемого неравенства, вследствие чего будут обращены вспять с таким трудом завоеванные достижения в области развития и сокращение масштабов нищеты.
Я призываю мировых лидеров объединиться и предложить срочные и скоординированные меры реагирования на этот глобальный кризис.
Я вижу три важнейшие области для действий:
ВО-ПЕРВЫХ, НЕОБХОДИМО ЗАНЯТЬСЯ ЧРЕЗВЫЧАЙНОЙ СИТУАЦИЕЙ В ОБЛАСТИ ЗДРАВООХРАНЕНИЯ.Возможности по уходу в специализированных медицинских учреждениях даже за пациентами с легкой формой болезни во многих странах оказались превышены, причем многие из них оказались не в состоянии удовлетворять огромные потребности пожилых людей.
Мы видим, что даже в самых богатых странах возможности систем здравоохранения напряжены до предела.
Для удовлетворения неотложных потребностей и резко возросшего спроса необходимо срочно увеличить расходы на здравоохранение, что позволит расширить тестирование, укрепить учреждения, поддержать медицинских работников и обеспечить адекватное снабжение, в полной мере соблюдая права человека и не подвергая людей стигматизации.
Есть доказательства того, что распространению вируса можно положить конец. Значит, мы должны положить ему конец.
Если мы не ограничим безудержное распространение вируса, особенно в наиболее уязвимых регионах мира, погибнут миллионы людей.
Кроме того, необходимо немедленно отказаться от подхода, при котором каждая страна осуществляет собственные стратегии в области здравоохранения, и взять на вооружение такой подход, при котором в условиях полной прозрачности обеспечивается скоординированное принятие ответных мер в общемировом масштабе, включая оказание помощи странам, которые в меньшей степени подготовлены к преодолению этого кризиса.
Правительства должны оказывать самую решительную поддержку многосторонним усилиям по борьбе с этим вирусом под руководством Всемирной организации здравоохранения, призывы которой должны быть полностью удовлетворены.
Нынешнее катастрофическое положение в области здравоохранения ясно показывает, что наши возможности ограничиваются возможностями самой слабой системы здравоохранения.
Глобальная солидарность не только является моральным долгом, но и отвечает интересам всех и каждого.
ВО-ВТОРЫХ, НЕОБХОДИМО СОСРЕДОТОЧИТЬ ВНИМАНИЕ НА СОЦИАЛЬНЫХ ПОСЛЕДСТВИЯХ И НА ЭКОНОМИЧЕСКИХ МЕРАХ РЕАГИРОВАНИЯ И ВОССТАНОВЛЕНИИ ЭКОНОМИКИ.В отличие от финансового кризиса 2008 года одного лишь вливания капитала в финансовый сектор будет недостаточно. Нынешний кризис не является кризисом банковской системы, не говоря уже о том, что банки должны стать частью решения проблемы.
Нынешний кризис не является кризисом банковской системы, не говоря уже о том, что банки должны стать частью решения проблемы.
И в этом смысле его нельзя рассматривать как обычное рассогласование спроса и предложения; он вызывает рассогласование функционирования общества в целом.
Необходимо гарантировать ликвидность финансовой системы, и банкам следует использовать свою способность противостоять потрясениям для того, чтобы оказать поддержку клиентам.
Вместе с тем не будем забывать, что это, по сути, гуманитарный кризис.
Самое главное, следует сосредоточить внимание на людях — низкооплачиваемых работниках, малых и средних предприятиях, наиболее уязвимых представителях общества.
Речь идет о поддержке заработка, страховании, социальной защите, предотвращении банкротства и потери работы.
Речь также идет о разработке фискальных и денежно-кредитных мер реагирования, призванных обеспечить, чтобы бремя не легло на тех, кто в наименьшей степени может себе это позволить.
Необходимо сделать так, чтобы восстановление осуществлялось не за счет беднейших, поскольку мы не можем допустить, чтобы возник целый сонм новых бедняков.
Мы должны предоставить ресурсы непосредственно людям. Некоторые страны приступают к осуществлению таких инициатив в области социальной защиты, которые основаны на денежных переводах и концепции всеобщего дохода.
Нам необходимо выйти на более высокий уровень, с тем чтобы обеспечить поступление помощи лицам, полностью зависящим от неформальной экономики, и странам, располагающим меньшими возможностями в плане реагирования.
Спасительной помощью в развивающихся странах — особенно сегодня — являются денежные переводы. Страны уже взяли на себя обязательство снизить комиссию за денежные переводы до 3 процентов, что значительно ниже текущего среднего уровня. Кризис требует, чтобы мы пошли дальше и, по возможности, приблизили эту ставку к нулевому значению.
Лидеры Группы двадцати также предпринимают шаги по защите собственных граждан и экономики, отказываясь от выплаты процентов. Мы должны применить ту же логику к наиболее уязвимым странам в нашей «глобальной деревне» и облегчить их долговое бремя.
Нам нужна повсеместная приверженность делу обеспечения достаточных финансовых ресурсов для оказания поддержки странам, находящимся в трудном положении. И здесь одну из ведущих ролей играют МВФ, Всемирный банк и другие международные финансовые учреждения. Существенно важную роль в поиске творческих инвестиционных решений и сохранении рабочих мест призван сыграть частный сектор.
Существенно важную роль в поиске творческих инвестиционных решений и сохранении рабочих мест призван сыграть частный сектор.
Мы должны воздерживаться от искушения прибегнуть к протекционизму. Настало время демонтировать торговые барьеры и восстановить цепочки поставок.
Если взглянуть на ситуацию более широко, то разрушение связей имеет самые серьезные последствия для общества.
Нам необходимо принимать меры по устранению воздействия этого кризиса на положение женщин. Женщины мира в непропорционально большей степени несут это бремя дома и в экономике в целом.
Дети тоже платят высокую цену. В настоящее время более 800 миллионов детей не посещают школу, при этом для многих из них школьный обед является единственным приемом пищи. Мы должны обеспечить, чтобы все дети имели доступ к продовольствию и равный доступ к обучению — это позволит преодолеть цифровой разрыв и уменьшить стоимость услуг по подключению к средствам связи.
Мы должны обеспечить, чтобы все дети имели доступ к продовольствию и равный доступ к обучению — это позволит преодолеть цифровой разрыв и уменьшить стоимость услуг по подключению к средствам связи.
На фоне того, как привычный уклад жизни людей нарушается, вводится режим изоляции и происходит изменение повседневной реальности, наша задача заключается в том, чтобы предотвратить превращение этой пандемии в кризис психического здоровья. При этом наибольшему риску будут подвергаться молодые люди.
Мир должен продолжать оказывать основную поддержку программам в интересах наиболее уязвимых слоев населения, в том числе через координируемые Организацией Объединенных Наций планы гуманитарного реагирования и оказания помощи беженцам. Гуманитарная помощь не должна политизироваться.
В-ТРЕТЬИХ, НАКОНЕЦ, МЫ НЕСЕМ ОТВЕТСТВЕННОСТЬ ЗА «УСКОРЕННОЕ ВОССТАНОВЛЕНИЕ».
Финансовый кризис 2008 года наглядно продемонстрировал, что страны с надежными системами социальной защиты меньше всего пострадали и быстрее всех оправились от его последствий.
Мы должны принять меры к тому, чтобы из этого были извлечены уроки и чтобы этот кризис стал переломным моментом для мер готовности к чрезвычайным ситуациям в области здравоохранения и для инвестиций в критически важные общественные услуги XXI века и в усилия по эффективному обеспечению благосостояния народов мира.
У нас есть рамочная программа действий — Программа устойчивого развития на период до 2030 года и Парижское соглашение об изменении климата. Мы должны выполнить обещания, данные нами народам и планете.
Организация Объединенных Наций — и наша глобальная сеть страновых отделений — будет оказывать всем правительствам поддержку, с тем чтобы глобальная экономика и народы, которым мы служим, вышли из этого кризиса еще более сильными. Такова логика Десятилетия действий по достижению целей в области устойчивого развития.
Такова логика Десятилетия действий по достижению целей в области устойчивого развития.
Сегодня, как никогда ранее, нам необходимы солидарность, надежда и политическая воля, чтобы вместе преодолеть этот кризис.
| Подготовка научно-исследовательской работыПодготовка тезисов Подготовка презентации научно-исследовательской работыСжатие изображений | Что такое научно-исследовательская работа Научно-исследовательская работа – это работа научного характера, связанная с научным поиском, проведением исследований, экспериментами в целях расширения имеющихся и получения новых знаний, проверки научных гипотез, установления закономерностей, научных обобщений и обоснований.  Научно-исследовательская работа представляет собой самостоятельное, а зачастую, совместное с научным руководителем, исследование обучающегося, раскрывающее его знания и умение их применять для решения конкретных практических задач. Работа должна носить логически завершенный характер и демонстрировать способность обучающегося ясно излагать свои мысли, аргументировать предложения и грамотно пользоваться терминологией. Конечно, эта работа гораздо проще, чем работы настоящих ученых. Но по структуре, применяемым методам, системе планирования – это настоящее исследование. Исследовательская работа – это не реферат и не статья одного из специалистов, скачанная из интернета. Это возможность провести самостоятельное исследование и применить научный подход для получения результата, применить практические навыки или приобрести новые для решения поставленных задач, проявить навыки планирования своей работы и анализа полученных результатов. Знания, полученные в ходе исследования, полученные своим трудом, запоминаются гораздо лучше. Согласно ФГОС (Федеральный государственный образовательный стандарт) исследовательская работа является обязательной частью подготовки выпускника. В результате этой работы обучающийся должен показать умение планировать свою деятельность, проявлять инициативу, придерживаться поставленного исследовательского вопроса, анализировать ход своей работы и оценивать полученные результаты, применять специализированную терминологию, отражать результаты своего (индивидуального) исследования.Этапы научно-исследовательской работы Этапы исследовательской деятельности: 1. Выбор направления исследования 2. Выбор темы исследования 3. Формулирование гипотезы 4. Планирование этапов работы 5.  Сбор данных о предмете исследования Сбор данных о предмете исследования6. Проведение исследования 7. Оценка полученных результатов 8. Оформление работы Выбор направления исследования и выбор темы исследованияРабота над исследованием начинается с желания заниматься этим вопросом. Необходимо понять, о чем будет исследование, осознать свои сильные стороны как исследователя в выбранном направлении, принесет ли это пользу в будущей деятельности. Хорошая тема для научно-исследовательской работы – это та тема, которая интересна именно вам и вашему научному руководителю. Сформулируйте тему правильно. Тема должна быть корректной, узкой, ясной. Для обучающихся в образовательных организациях общего образования успешным учебным исследованием может считаться повторение чьего-либо эксперимента, анализ определенной методики, применение метода в новых условиях, сравнение методик различных специалистов и пр. совместно с глубоким анализом литературы по выбранной теме. Для обучающихся в образовательных организациях среднего профессионального образования и высшего образования важным фактором является новизна исследования, его актуальность. Формулирование гипотезыСформулируйте научное предположение, требующее проверки и теоретического обоснования или подтверждения. Ключевая исследовательская гипотеза должна вытекать из формулировки темы исследования. Планирование этапов работыСоставьте развернутый и структурированный план своей работы для последовательного движения к цели исследования. Это поможет организовать свою работу и придать ей более целеустремленный характер. Кроме того, это дисциплинирует и заставляет работать в определенном ритме. Сбор данных о предмете исследованияОпределите, как вы будете получать данные. Существует два метода – эмпирический и исследование по вторичным источникам. Эмпирический – получение данных через наблюдения и эксперименты. Исследование по вторичным источникам – умозрительное заключение, обзор и глубокий анализ литературы. Проведение исследованияПриступайте к проведению исследования в соответствии с выбранным методом исследования.  На этом этапе работы собирают необходимые эмпирические данные для проверки выдвинутой гипотезы. На этом этапе работы собирают необходимые эмпирические данные для проверки выдвинутой гипотезы.Оценка полученных результатовОкончание работы над исследованием. Вы получили знания о том, как устроен объект исследования, что из себя представляет, чем отличается от чего-то другого, что не доисследовано, какое может быть продолжение. Основным критерием результативности проделанной работы для обучающихся в образовательных организациях общего образования является уровень освоения навыков исследовательской деятельности. Для обучающихся в образовательных организациях среднего профессионального образования и высшего образования таким критерием таким критерием является научная новизна и практическая значимость. Написание текста работыДля написания текста можно воспользоваться законами художественного творчества из статьи Марка Твена «Литературные грехи Фенимора Купера»: «Автор обязан: Структура работы может быть представлена следующим образом: 1. Титульный лист 2. Аннотация (что сделано, что нового получено) 3. Содержание (название глав и параграфов с указанием страниц) 4. Введение (обозначение проблемы, актуальность, практическая значимость исследования; определяются объект и предмет исследования; цель и задачи исследования; коротко перечисляются методы работы) 5. Главы основной части, в том числе и исследовательская часть (анализ научной литературы; выбор определенных методов и конкретных методик исследования; процедура исследования и ее этапы) 6. Выводы (интерпретация полученных результатов) 7. Заключение (краткий обзор выполненного исследования) 8.  Список литературы Список литературы9. Приложения (таблицы, графики, справочники и др.)Защита работы и текст выступления Защита исследовательских работ осуществляется на тематических конференциях. Обычно на выступление отводится 10 минут, поэтому необходимо проговорить свое выступление с часами в руках. Но проговаривать рекомендуется в слух, а не про себя. Это помогает структурировать текст и понять, что в речи не досказано. Текст выступления не должен затрагивать подробности. За 10 минут вы никогда никаких подробностей рассказать не сможете. Надо изложить основные результаты. Все, что вы говорите, должно быть пояснено, но не надо касаться вещей, которые и так все знают. Будьте готовы ответить на вопросы экспертного жюри и других участников конференции. |
 Метод, когда ученик и учитель ставят перед собой вопросы, которые ставили первооткрыватели законов в различных науках, и совместно ищут ответы – больше увлекает учеников и формирует желание в дальнейшем заниматься научной деятельностью.
Метод, когда ученик и учитель ставят перед собой вопросы, которые ставили первооткрыватели законов в различных науках, и совместно ищут ответы – больше увлекает учеников и формирует желание в дальнейшем заниматься научной деятельностью.
 найти нужное слово, а не его троюродного брата,
найти нужное слово, а не его троюродного брата,Вот это характер! | Газета Предгорье
Светлана Баранова себя никогда не жалела и не считала инвалидом. Шла по жизни с гордо поднятой головой. Откуда такая стойкость, такой поистине «железный» характер, такая самоотдача, разбиралась наш корреспондент.

Светлана Баранова успешно преподаёт музыку в Псебайской школе искусств.
Слово «инвалиды», как ни крути, несёт в себе отрицательный смысл. Сейчас его заменили на более мягкое сочетание — «люди с ограниченными возможностями здоровья», но суть осталась та же — это граждане, которые, как правило, нуждаются в помощи общества, государства. К Светлане Барановой это точно не относится. Она самодостаточный, красивый внешне и внутренне, интеллигентный, добрый, готовый прийти на помощь всем нуждающимся человек. Несмотря на проблему со здоровьем (инвалид с детства), она всегда больше отдавала людям, чем брала.
Железная кнопка
— Я в детстве была заводилой — бегала по крышам, прыгала в сугробы, каталась на лыжах и коньках, — вспоминает Светлана Всеволодовна. — Когда мы с мамой поехали в Житомир к врачу и мама сказала ей, что я катаюсь на коньках — та не поверила…. Я даже не знала, что в школе было освобождение от физкультуры, но вместе со всеми метала гранату, бросала диск, ползала по канату, играла в волейбол.
— А как же ножка больная? — задала я мучивший меня вопрос.
— Я жила нормальной жизнью, не знала, что я какая-то не такая! Мне это пришло в голову, когда я повзрослела — мальчишки обращали на мою ногу внимание… Я везде успевала: драмкружок, кружок по фото… Я дралась со всеми, у меня было обострённое чувство справедливости. Жила как все дети, тепличным растением точно не была.
— Светлана Всеволодовна, знаю таких ребят с инвалидностью, они учились в обычных школах, со здоровыми ребятами, но за этим всем стояла огромная работа, забота родителей…
— В моём случае не было огромной заботы родителей, они просто мне не мешали…
Думаю, тут без всепоглощающей, безусловной родительской любви не обошлось. Дети, которых любят и понимают в семье, как правило, успешны в жизни. Ну, а бойцовский характер, судя по всему, бонус если не от родителей, то от Господа Бога.
— Не знаю, в кого я, — размышляет наша героиня. — Моя мама кроткая была. Добрая, понимающая. У моих родителей трудная судьба…
Угнали в Германию
Приграничная Житомирская область была оккупирована фашистами в начале Великой Отечественной войны. Семья Всеволода Ивановича и Татьяны Никифоровны Бочановских жила в маленьком городке Олевске. Отец Светланы происходил из большой семьи священника, где все дети получили образование, в том числе и Всеволод, но он очень любил лошадей и работал на фарфоровом заводе конюхом. Несмотря на постоянные облавы, помогал вместе со своими родственниками партизанам — выпекали и отправляли им хлеб, медикаменты, снабжали информацией.
Семья Всеволода Ивановича и Татьяны Никифоровны Бочановских жила в маленьком городке Олевске. Отец Светланы происходил из большой семьи священника, где все дети получили образование, в том числе и Всеволод, но он очень любил лошадей и работал на фарфоровом заводе конюхом. Несмотря на постоянные облавы, помогал вместе со своими родственниками партизанам — выпекали и отправляли им хлеб, медикаменты, снабжали информацией.
А потом всю семью Бочановских с пятилетней дочерью Раисой угнали на работы в Германию. Родители работали на заводе, дочка находилась при них. Питание было очень скудное, организм ребёнка ослаб на такой еде. И когда Татьяна Никифоровна с дочкой вернулась на родину (отец после освобождения ушёл на фронт), Раечка заболела сухим туберкулёзом и в возрасте 22 лет умерла от этой болезни.
Родившаяся после войны Светлана тоже болела туберкулёзом, постоянно находилась то в больнице, то в санатории, и когда девочка пошла во второй класс, болезнь наконец отступила.
— Я осталась одна у родителей, и мне всё позволялось, правда, в пределах разумного, — отметила Светлана Всеволодовна. — С раннего детства я очень любила петь, обожала музыку. Когда увидела объявление на Доме культуры, что набирают детей в музыкальный кружок, я сразу пошла и записалась. Не представляю, как можно жить без музыки!
— С раннего детства я очень любила петь, обожала музыку. Когда увидела объявление на Доме культуры, что набирают детей в музыкальный кружок, я сразу пошла и записалась. Не представляю, как можно жить без музыки!
Любовь с первого взгляда
Светлана поступила в музыкальное училище, не имея за плечами музыкальной школы, готовилась сама. После его окончания стала в родном Олевске работать преподавателем. На работу всегда шла с радостью, дети любили её, со многими у неё до сих пор сохранились добрые отношения.
Ничто не предвещало крутых перемен, и всё же они случились — в тридцать лет она вышла замуж за молодого парня Александра Баранова из Нижнего Новгорода. Он был значительно младше Светланы, и она не строила никаких планов. Но Саша влюбился с первого взгляда и — навсегда. Познакомившись случайно в ресторане в Олевске, где солдат был в армейской командировке, они год переписывались, а потом он приехал и попросил её руки у родителей. Бочановские растерялись — почему так быстро? Но были рады за дочь.
На свадьбу приехала Сашина мама с сестрой, она собиралась отговорить Сашу от женитьбы. Женщина ожидала чего угодно, но только не этого: сын женится на девушке-инвалиде, которая к тому же старше него. Но, поняв всю серьёзность намерений сына, проявила мудрость и отговаривать не стала. Пожив с молодыми и их родителями, свекровь перед отъездом сказала: «Саша, береги её. Хорошую девушку ты встретил».
Урок Чернобыля
В 1986-м грянул Чернобыль. Олевск находился в девяноста километрах от Чернобыля. У Барановых уже было трое детей — тринадцатилетняя Наташа, погодки Таня и Аннушка восьми и семи лет. Врачи сказали Светлане: «Хотите жить — уезжайте». И они решились на переезд в Краснодарский край, Выбрали Псебай, потому, что в музыкальной школе нашлась вакансия для супруги.
— Я с детьми ехала на поезде, а муж с моим отцом — на машинах, — вспоминает моя собеседница. — Государство полностью оплатило переезд. Приехали в Псебай, встали на учёт как чернобыльцы. Нам дали деньги на стройматериалы, и мы стали расширяться, достраивать купленный дом. Семья-то большая, дедушка с нами жил. Огород — 25 соток, пахали, держали свиней, овец… Кого мы только не держали, чтобы в девяностые выжить! Муж брался за любую работу. У меня-то была постоянная работа, пусть и не всегда за неё вовремя платили. Так, за счёт своего хозяйства, детей подняли и выучили.
Нам дали деньги на стройматериалы, и мы стали расширяться, достраивать купленный дом. Семья-то большая, дедушка с нами жил. Огород — 25 соток, пахали, держали свиней, овец… Кого мы только не держали, чтобы в девяностые выжить! Муж брался за любую работу. У меня-то была постоянная работа, пусть и не всегда за неё вовремя платили. Так, за счёт своего хозяйства, детей подняли и выучили.
— Как же вы справлялись и с работой, и с детьми, и с общественными обязанностями? — спросила я.
— Мне все помогали: муж, отец, дети. А я работала наравне со всеми — в огороде, на сенокосе, корову доила… Муж — большой помощник. Когда дети родились — он купал их, гулял с ними. Девочки стали старше — ходили вместе в лес, катались на лыжах. Мне повезло с мужем. Говорят, жизнь удалась, если утром с радостью идёшь на работу, а вечером с радостью возвращаешься домой. Это обо мне.
Зачем учиться музыке?
Дочери выросли и уехали учиться в Нижний Новгород, где тогда жила бабушка, мама Александра. И Наталья, и Татьяна окончили музыкальное училище, затем консерваторию и сейчас преподают — одна в Дзержинске, другая в Володарске. Младшая Анна — тоже педагог, окончила Армавирский педагогический по специальности «логопед-дефектолог». Вышла замуж за кавказского парня, трудится в Псебае.
И Наталья, и Татьяна окончили музыкальное училище, затем консерваторию и сейчас преподают — одна в Дзержинске, другая в Володарске. Младшая Анна — тоже педагог, окончила Армавирский педагогический по специальности «логопед-дефектолог». Вышла замуж за кавказского парня, трудится в Псебае.
Думается, Светлана Всеволодовна может гордиться тем, что дочери Наташа и Таня пошли по её стопам, причём выбрали мамины специальности — они теоретики музыки, а также преподают фортепиано.
— Да, я учила своих дочек, мы выезжали на олимпиады, где они занимали хорошие места, — делится наша героиня. — Много способных учеников было, правда, не все пошли по музыкальной стезе. У меня есть ученик, который, закончив ДШИ, сказал маме: «Ты хотела, чтобы я закончил музыкалку? Я это сделал, но музыкантом не стану». Потом парень идёт в армию, попадает в Морфлот и в первом же письме пишет: «Мама, спасибо тебе, что ты настояла, чтобы я окончил музыкальную школу! Азбуку Морзе я лучше всех знаю». Он плавал, работал на Дальнем Востоке, сейчас живёт в Новороссийске, накупил синтезаторов и сочиняет музыку, присылает мне свои «горячие блинчики». Да, он любитель, не профессионал, но в жизни музыка ему очень пригодилась…
Да, он любитель, не профессионал, но в жизни музыка ему очень пригодилась…
Требовательная любовь
Дочка Светланы Харченко шесть лет занимается у Светланы Барановой. Вот что она рассказала: «Светлана Всеволодовна — человек старой закалки, но она чутко откликается на вызовы времени. Детей педагог любит, но её любовь — требовательная. Это не предвзятая требовательность, а желание научить детей, привить любовь к музыке. У нас сложилась такая ситуация, что не было транспорта, мы живём в Шедке, и дочь могла оставить учёбу, но Светлана Всеволодовна пошла нам навстречу, договорилась с другими педагогами, и мы приезжаем заниматься в любую свободную минутку. К сожалению, людей такой порядочности, образованности, культуры не так много в наше время».
— Светлана Всеволодовна уже тридцать лет преподаёт в нашей школе теоретические дисциплины и фортепиано, — говорит директор Псебайской ДШИ Наталья Казуль. — У неё высшая квалификационная категория, качество преподавания — на самом высоком уровне. Если педагог берётся за подготовку детей на конкурс — это всегда первые-вторые места, причём на краевом уровне. У неё прекрасные отношения со всеми коллегами, взаимопонимание с детьми и родителями.
Если педагог берётся за подготовку детей на конкурс — это всегда первые-вторые места, причём на краевом уровне. У неё прекрасные отношения со всеми коллегами, взаимопонимание с детьми и родителями.
— Светлана и Александр Барановы — очень дружная семья, позитивные люди, с которыми приятно общаться, — считает вахтёр ДШИ Любовь Хлапова. — Они всегда придут на помощь. Светлана старается больше дать людям, чем взять от них, уж такой она человек — щедрой души, и слово «инвалид» — это не про неё. Вы знаете, что она вместе с мужем моржует?!
Как выяснилось, в Малой Лабе зимой купается Александр Владимирович вместе с другом, а Светлана Всеволодовна занимается закаливанием. Хотя какая разница — то и другое укрепляет здоровье и отодвигает старость. Да Светлана Баранова и не выглядит на свои 70 с хвостиком. Когда душа молода, тело стремится ей соответствовать!
— Я обожаю классику, самые мои любимые композиторы — Бетховен и Чайковский. Бетховен дух поднимает, а Чайковский лирик, он затрагивает самые сокровенные струны души. Не понимаю, как можно жить без музыки, пения, звучания родного языка. Мы учили дочек не только русскому, но и украинскому языку. Теперь смысл нашей жизни во внуках. Болит душа за Россию, Украину, Белоруссию. Надо любить родину, помогать ей тем, что хорошо учишься и хорошо делаешь своё дело — так учу детей.
Не понимаю, как можно жить без музыки, пения, звучания родного языка. Мы учили дочек не только русскому, но и украинскому языку. Теперь смысл нашей жизни во внуках. Болит душа за Россию, Украину, Белоруссию. Надо любить родину, помогать ей тем, что хорошо учишься и хорошо делаешь своё дело — так учу детей.
С большим удовольствием пообщавшись со Светланой Барановой, я вспомнила слова чилийского поэта Пабло Неруды: «Медленно умирает тот, кто не переворачивает столы, тот, кто не отбивает удары судьбы, когда он несчастлив в работе или в любви». Ведь Светлана Всеволодовна никогда не шла на поводу у судьбы и держала её в ежовых рукавицах.
Лариса Торопова, фото автора и из архива семьи Барановых.
Опубликовано 4 дек 2020 | 644 просмотров
Вот это характер!
«Спартак» — «Локомотив» — 2:1 (2:0)
Москва. Стадион «Открытие Арена». 02.12. 25 006 зрителей.
Судья: С. Карасёв (Москва).
«Спартак»: Ребров, Рассказов, Кутепов, Джикия, Комбаров, Мельгарехо (Ломовицкий, 66), Фернандо (Тимофеев, 42), Глушаков (к), Ханни (Петкович, 72), Луис Адриано, Зе Луиш.
Запасные: Максименко, Селихов, Попов, Ананидзе, Самедов, Игнатов, Ташаев, Мелкадзе, Педро Роша.
«Локомотив»: Гилерме, Игнатьев, Кверквелия, Чорлука (Фернандеш, 63), Рыбус, Фарфан, Денисов (к) (Баринов, 46), Крыховяк, Ант. Миранчук (Эдер, 77), Ал. Миранчук, Смолов.
Запасные: Коченков, Идову, Хёведес, Ротенберг, Маргасов, Лысов, Тарасов, Тугарев, Жемалетдинов.
Голы: 1:0 Глушаков (5, Ханни), 2:0 Луис Адриано (37, Ханни). 2:1 Фарфан (80)
Предупреждения: Денисов (14), Чорлука (45), Баринов (58), Глушаков (62), Кверквелия (90+2).
Удаление: Рассказов (67).
Незабитый пенальти: Смолов (69, штанга).В преддверии матча с «Локомотивом» спартаковцы попали в сложное положение. Во-первых, у команд был разный эмоциональный фон, с которым они подошли к этой игре. Наши обидно уступили в четверг на последней минуте «Рапиду», железнодорожники же, напротив, одержали в среду свою первую победу в нынешней Лиге чемпионов — над «Галатасараем». Во-вторых, подопечные Юрия Сёмина имели преимущество в плане «физики»: на восстановление у них было на сутки больше, что в конце года при плотном календаре приобретает немалое значение. Словом, многое было против нас. И по ходу матча тоже. Тем ценнее эта победа, которую подопечные Олега Кононова добыли, продемонстрировав в драматическом поединке запредельную самоотдачу и характер!
Словом, многое было против нас. И по ходу матча тоже. Тем ценнее эта победа, которую подопечные Олега Кононова добыли, продемонстрировав в драматическом поединке запредельную самоотдачу и характер!
В стартовом составе «Спартака» (а наши игроки вышли на поле в специальных футболках в поддержку травмированных Романа Зобнина и Самуэля Жиго) по сравнению с матчем против австрийцев произошли два изменения: вместо Тимофеева в опорную зону вернулся Фернандо, а травмированного Ещенко на правом краю обороны заменил Рассказов.
Первая половина первого тайма была всецело за красно-белыми. Уже на 5-й минуте мы провели успешную контратаку: Ханни прорвался по левому краю и сделал подачу в центр, где после небольшого рикошета Глушаков в падении головой поразил цель. Вскоре у нас прошла хорошая комбинация, которую завершал плотным ударом с лета Комбаров, — Гилерме оказался начеку. Было еще несколько хороших атак, но в их концовках нас, увы, подводил последний неточный пас.
Сердце спартаковских болельщиков замерло, когда на 29-й минуте на газоне оказался Джикия. Слава богу, обошлось без травмы. После этого красно-белые трибуны выдохнули второй раз, когда Смолов из убойной позиции послал мяч выше ворот. Но инициатива на минут десять перешла к гостям.
Слава богу, обошлось без травмы. После этого красно-белые трибуны выдохнули второй раз, когда Смолов из убойной позиции послал мяч выше ворот. Но инициатива на минут десять перешла к гостям.
К огромному сожалению, перед самым перерывом мы потеряли из-за травмы Фернандо.
В начале второго тайма опасный удар после дриблинга нанес Ханни, но Гилерме не сплоховал, поймав мяч намертво. Сёмин пошел ва-банк: вместо защитника Чорлуки выпустил атакующего хавбека Фернандеша. В одном из эпизодов партнеров выручил Джикия, ликвидировавший в отчаянном подкате прорыв Смолова. «Локо» нас поджал, а тут еще Карасёв удалил Рассказова с поля и назначил пенальти. Благо Смолов пробил в штангу. Но спартаковцы остались вдесятером.
Какое-то жуткое невезение нас преследует в домашних матчах с «Локомотивом». Когда Фарфан забивал нам гол, травму получил Ребров. Замен к тому времени у нас не осталось, и мужественный Артём доигрывал матч с повязкой на голове. Хотя было видно, как ему плохо.
Когда Фарфан забивал нам гол, травму получил Ребров. Замен к тому времени у нас не осталось, и мужественный Артём доигрывал матч с повязкой на голове. Хотя было видно, как ему плохо.
На первой добавленной минуте Ломовицкий упал в чужой штрафной, но судья пенальти не дал. В концовке мы защищались всей командой, показав недюжинную волю к победе и несгибаемый характер. Как же нужны такие победы, «Спартак»!
Имена персонажей | Какой символ и знак называется
Ниже приводится обзор 85 часто используемых символов, знаков препинания или знаков, которые включены в большинство шрифтов. К ним относятся знаки препинания и другие символы, используемые в типографике. Технически эти формы символов называются глифами. Рядом с каждым именем глифа перечислены объекты Unicode и HTML, а также код ASCII и объект HTML, если они доступны. Я также перечислил сочетание клавиш Windows ALT или эквивалент для Mac, которое можно использовать для вставки символа в текст.
В большинстве примеров используется шрифт Arial Bold. Маленькие линии указывают базовую линию, высоту по оси x, а также высоту восходящего и нижнего выносных элементов.
Маленькие линии указывают базовую линию, высоту по оси x, а также высоту восходящего и нижнего выносных элементов.
лигатуры AE — æ и Æ
Строчная ae Строчные буквы ae
Юникод: U + 000E6
HTML-объект: & aelig; — HTML-код: & # 230;
Нажатие клавиши ПК: ALT + 0230
Прописные буквы ae
Юникод: U + 000C8
HTML-объект: & AElig; — HTML-код: & # 198;
Нажатие клавиши ПК: ALT + 0198
Почти равно — ≈
Почти равно Unicode: U + 02248
HTML-объект: & asymp; — HTML-код: & # 8776;
Также называемый приблизительно равен , асимптотика или двойной тильде . Тильда (~), приблизительно равно () и , асимптотически равное (≃), — это другие знаки, используемые для обозначения приближения в зависимости от контекста.
Амперсанд — &
Амперсанд Юникод: U + 00026 — ASCII: 38
HTML-объект: & amp; — HTML-код: & # 38;
Логограмма, образованная от букв и — латинское слово «и»
Нажатие клавиши ПК: обычно находится в верхнем ряду
Ангстрем —
Å Ангстрем Unicode: U + 0212B
HTML-код: & # 8491;
Буква шведского алфавита, которая используется для обозначения единицы длины, равной 0.1 нанометр (10 −10 м)
Апостроф — ‘
Апостроф Unicode: U + 00027 — ASCII: 39
HTML-объект: & apos; — HTML-код: & # 39;
Также называется закрывающей одинарной кавычкой
Нажатие клавиши ПК: ALT + 39 или ALT + 0027
Примерно равно —
≅ Примерно равно Unicode: U + 02245
HTML-объект: & cong; — HTML-код: & # 8773;
Звездочка — *
Звездочка Unicode: U + 0002A — ASCII: 42
HTML-объект: & ast; — HTML-код: & # 42;
Нажатие клавиши ПК: ALT + 42
Под знаком — @
В Unicode: U + 00040 — ASCII: 64
HTML-объект: & commat; — HTML-код: & # 64;
В Unicode это называется рекламным роликом с символом . Карет
Карет
Unicode: U + 0005E — ASCII: 94
HTML-объект: & Hat; — HTML-код: & # 94;
Также называется шляпа , крыша или дом знак.C) или для обозначения отсутствия содержимого. Не путать с акцентом с циркумфлексом, который используется над символами (например, â)
Седилья
Седиль Unicode: U + 000B8
HTML-объект: & ccedil; для строчной буквы c с седилем
Обычно добавляется под другими глифами, например ç или Ȩ. Напоминает маленькую цифру «5» в большинстве шрифтов.
Знак центов —
¢ Цент Unicode: U + 000A2
HTML-объект: & cent; — HTML-код: & # 162;
Используется во многих валютах, иногда с вертикальной линией или без нее
Нажатие клавиши ПК: ALT + 0162
Галочка — ✓
Галочка Unicode: U + 02713
HTML-объект: & check; — HTML-код: & # 10003;
Также есть жирная или жирная галочка ✔ (HTML-код: & # 10004;)
Двоеточие -:
Двоеточие Юникод: U + 0003A — ASCII: 58
HTML-объект: & двоеточие; — HTML-код: & # 58;
Знак препинания, который часто предшествует объяснению или списку
запятая -,
Запятая Unicode: U + 0002C — ASCII: 44
HTML-объект: & comma; — HTML-код: & # 44;
Знак препинания, используемый, среди прочего, для разделения частей предложения или списка
Знак авторского права — ©
Авторские права Unicode: U + 000A9
HTML-объект: & copy; — HTML-код: & # 169;
Символ, используемый в уведомлениях об авторских правах
Нажатие клавиши ПК: ALT + 0169 — Нажатие клавиши Mac: OPTION + g
Фигурные скобки — {}
Левая фигурная скобка Левая фигурная скобка
Юникод: U + 0007B — ASCII: 123
HTML-объект: & lbrace; — HTML-код: & # 123;
Также называется левой фигурной скобкой
Правая фигурная скобка
Юникод: U + 0007D — ASCII: 125
HTML-объект: & rbrace; — HTML-код: & # 125;
Также называется правой скобкой
Знак валюты —
¤ Валюта Unicode: U + 000A4
HTML-объект: & curren; — HTML-код: & # 164;
Сокращение названия валюты, особенно в отношении денежных сумм
Нажатие клавиши ПК: ALT + 0164
Кинжалы — † и ‡
Кинжал Кинжал
Юникод: U + 02020
HTML-объект: & dagger; — HTML-код: & # 8224;
Типографский символ для обозначения сноски (вместо звездочек)
Нажатие клавиши ПК: ALT + 0134 — Нажатие клавиши Mac: OPTION + T
Двойной кинжал
Unicode: U + 02021
HTML-объект: & Dagger; — HTML-код: & # 8225;
Нажатие клавиши ПК: ALT + 0135
Градус — °
Степень Unicode: U + 000B0
HTML-объект: & deg; — HTML-код: & # 176;
Нажатие клавиши ПК: ALT + 0176 — Нажатие клавиши Mac: SHIFT + OPTION + 8
Диэрезис или Умлаут —
¨ Диэрезис или умлаут Юникод: U + 000A8
HTML-объект: & uml;
Диакритический знак (глиф добавляется к другим символам в качестве ударения, e. грамм. ë или Ä), который на таких языках, как французский или испанский, называется диэрезисом, а на немецком — умляутом. Подробнее о различиях можно узнать здесь.
грамм. ë или Ä), который на таких языках, как французский или испанский, называется диэрезисом, а на немецком — умляутом. Подробнее о различиях можно узнать здесь.
Нажатие клавиши ПК: ALT + 0168
Знак отдела — ÷
Знак деления Unicode: U + 000F7
HTML-объект: & div; — HTML-код: & # 247;
Используется для обозначения математического деления, хотя стандарт ISO 80000-2 рекомендует использовать для этого солидус (/).
Нажатие клавиши ПК: ALT + 0247
Знак доллара
—
долларов Знак доллара Юникод: U + 00024 — ASCII: 36
HTML-объект: & доллар; — HTML-код: & # 36;
Также используется для песо и других валют
Эллипсис -…
Многоточие Unicode: U + 02026
HTML-объект: & hellip; — HTML-код: & # 8230;
Также называется тройной точкой или точкой подвеса .Дополнительная информация в Википедии
Нажатие клавиши ПК: ALT + 0133 — Нажатие клавиши Mac: ОПЦИЯ +;
EM Dash
Эм Даш Unicode: U + 02014
HTML-объект: & mdash; — HTML-код: & # 8212;
Нажатие клавиши ПК: ALT + 0151 — Нажатие клавиши Mac: SHIFT + ALT + дефис
EN Чертеж — —
En Dash Unicode: U + 02013
HTML-объект: & ndash; — HTML-код: & # 8211;
Знак препинания, который в основном используется для отображения диапазонов чисел и дат (например, 1914–1918 гг. )
)
Нажатие клавиши ПК: ALT + 0150 — Нажатие клавиши Mac: ALT + дефис
Знак равенства — =
Знак равенства Unicode: U + 0003D — ASCII: 61
HTML-объект: & equals; — HTML-код: & # 61;
Математический символ, используемый для обозначения равенства.Также именуется знаком равенства
Знак евро
— €
Знак евро Unicode: U + 020AC
HTML-объект: & euro; — HTML-код: & # 8364;
Используется для евро, официальной валюты большинства европейских стран
Нажатие клавиши ПК: ALT + 0128
Восклицательный знак -!
Восклицательный знак Unicode: U + 00021 — ASCII: 33
HTML-объект: & excl; — HTML-код: & # 33;
Также называется восклицательным знаком
Знак препинания, используемый для обозначения сильных чувств или большого количества слов или для выделения акцента, часто в конце предложения
Женский знак —
♀ Женский знак Unicode: U + 002640
HTML-объект: & female; — HTML-код: & # 9792;
Нажатие клавиши ПК: ALT + 12
Фракции — ½ ⅓ ¼
⅔ ¾ Одна половина Половина дроби — ½
Unicode: U + 000BD — ASCII: —
HTML-объект: & frac12; — HTML-код: & # 189;
Нажатие клавиши ПК: ALT + 0189 или ALT + 171
Четверть дроби — ¼
Unicode: U + 000BC
HTML-объект: & frac14; — HTML-код: & # 188;
Нажатие клавиши ПК: ALT + 0188 или ALT + 172
Одна третья дробь — ⅓
Unicode: U + 02153
HTML-объект: & frac13; — HTML-код: & # 8531;
Три четверти дроби — ¾
Unicode: U + 000BE
HTML-объект: & frac34; — HTML-код: & # 190;
Две трети дроби — ⅔
Unicode: U + 02154
HTML-объект: & frac23; — HTML-код: & # 8532;
Нажатие клавиши ПК: ALT + 0190
Полная остановка -.
 Полная остановка
Полная остановка Юникод: U + 0002E — ASCII: 46
HTML-объект: & период; — HTML-код: & # 46;
Также называется периодом .
Могильный акцент — `
Могильный акцент Unicode: U + 00060
Также называется обратным апострофом .
Нажатие клавиши ПК: ALT + 96
Знак больше ->
Больше чем знак Юникод: U + 0003E — ASCII: 62
HTML-объект: & gt; — HTML-код: & # 62;
Дефис — —
Дефис Юникод: U + 02010
HTML-объект: & дефис; — HTML-код: & # 8208;
Знак препинания, используемый для соединения слов и разделения слогов в одном слове.
Отличается от тире и немного короче , например, тире (-), и знака минус (-)
Идентично подписи —
≡ Идентично подписать Unicode: U + 02261
HTML-объект: & Equiv; — HTML-код: & # 8801;
Также называется знаком с тройной полосой .
Существует также знак , не идентичный знаку ( ≢ — HTML-объект: & nequiv; — HTML-код: & # 8808;)
Бесконечность — ∞
бесконечность Unicode: U + 0221E
HTML-объект: & infin; — HTML-код: & # 8734;
Interrobang —
‽ Интерробанг Юникод: U + 0203D
HTML-код: & # 8253;
Также называется bang или interabang и обозначается?!,!?,?!? или же !?!
Знак препинания, используемый для выражения волнения или недоверия или для задания риторического вопроса
Перевернутый восклицательный знак —
¡ Перевернутый восклицательный знак Unicode: U + 000A1
HTML-объект: & iexcl; — HTML-код: & # 161;
Также называется перевернутым восклицательным знаком
Нажатие клавиши ПК: ALT + 0161
Перевернутый вопросительный знак —
¿ Перевернутый вопросительный знак Unicode: U + 000BF
HTML-объект: & iquest; — HTML-код: & # 191;
Также называется перевернутым вопросительным знаком
Нажатие клавиши ПК: ALT + 0191
Знак меньше —
< Меньше знака Юникод: U + 0003C — ASCII: 60
HTML-объект: & lt; — HTML-код: & # 60;
Знак меньше или равно знаку — ≤
Меньше или равно подписи Unicode: U + 02264 — ASCII: —
HTML-объект: & le; — HTML-код: & # 8804;
Пастилки —
◊ Знак леденцов Unicode: U + 025CA
HTML-объект: & loz; — HTML-код: & # 9674;
Также называется ромбом , ромбом или тонким ромбом
Нажатие клавиши ПК: ALT + 4 для черной или заполненной пастилки
Мужской знак —
♂ Мужской знак Unicode: U + 02642 — ASCII: —
HTML-объект: & male; — HTML-код: & # 9794;
Нажатие клавиши ПК: ALT + 11
Micro — µ
Микро знак Unicode: U + 000B5 — ASCII: —
HTML-объект: & micro; — HTML-код: & # 181;
Это греческая буква mu .
Нажатие клавиши ПК: ALT + 0181 — Нажатие клавиши Mac: ALT + M
Минус — —
Знак минус Unicode: U + 02212 — ASCII: 45
HTML-объект: & minus; — HTML-код: & # 8722;
Математический символ, используемый для вычитания, а также понятие отрицательного
нажатие клавиши ПК: ALT + 45
Больше или равно знаку — ≥
Больше или равно подписи Unicode: U + 02265 — ASCII: —
HTML-объект: & ge; — HTML-код: & # 8805;
Знак умножения — ×
Знак умножения Unicode: U + 000D7 — ASCII: —
HTML-объект: & times; — HTML-код: & # 215;
Также называется знаком раз или знаком размера и отличается от строчной буквы «x».
Нажатие клавиши ПК: ALT + 0215
Без подписи — ¬
Не подписывать Unicode: U + 000AC
HTML-объект: & not; — HTML-код: & # 172;
Также называется знаком отрицания
Нажатие клавиши ПК: ALT + 0172
Знак не равнозначен —
≠ Не равно знаку Unicode: U + 02260 — ASCII: —
HTML-объект: & ne; — HTML-код: & # 8800;
Нажатие клавиши Mac: OPTION + =
Знак, используемый для обозначения того, что две величины, выражения или уравнения не равны. Это не называется знаком «косая черта».
Это не называется знаком «косая черта».
Цифровой знак — #
Номер Знак Unicode: U + 00023 — ASCII: 35
Также называется фунт , хэш или octothorp знак
OE лигатуры — œ и Œ
Строчная oe Строчные буквы oe
Юникод: U + 00153
HTML-объект: & oelig; — HTML-код: & # 339;
Нажатие клавиши ПК: ALT + 0156
Прописные буквы oe
Unicode: U + 00152
HTML-объект: & OElig; — HTML-код: & # 338;
Нажатие клавиши ПК: ALT + 0140
Ом Знак — Ом
Ом Unicode: U + 02126
HTML-код: & # 8486;
Идентично греческой заглавной букве омега
Круглые скобки — ()
Левая скобка Левая скобка
Юникод: U + 00028 — ASCII: 40
HTML-объект: & lpar; — HTML-код: & # 40;
Знак препинания, используемый для заключения информации
Также называется левой круглой скобкой или левой изогнутой скобкой или открывающейся скобкой (в Великобритании)
Правая скобка
Юникод: U + 00029 — ASCII: 41
HTML-объект: & rpar; — HTML-код: & # 41;
Знак препинания, используемый для заключения информации
Также называется правой круглой скобкой или правой изогнутой скобкой или закрывающей скобкой (в Великобритании)
Знак процента -%
Процентов Unicode: U + 00025 — ASCII: 37
HTML-объект: & percnt; — HTML-код: & # 37;
Символ, используемый для обозначения процента, числа или отношения в виде дроби от 100.
Также называется процентным знаком
Знак промилле —
Знак промилле Unicode: U + 02030
HTML-объект: & permil; — HTML-код: & # 8240;
Символ, используемый для обозначения частей на 1000.
Также называется промилле или промилле знак
Нажатие клавиши ПК: ALT + 0137
за десять тысяч знаков —
За десять тысяч Unicode: U + 02031
HTML-объект: & pertenk; — HTML-код: & # 8241;
Символ, используемый для обозначения частей на 10000.
Нажатие клавиши ПК: ALT + 0137
Знак Pilcrow —
¶ Знак Pilcrow Unicode: U + 000B6
HTML-объект: & para; — HTML-код: & # 182;
Также называется знаком абзаца , paraph или alinea
Нажатие клавиши ПК: ALT + 0182 — Нажатие клавиши Mac: ОПЦИЯ + 7
Знак плюс — +
Знак плюс Unicode: U + 0002B — ASCII: 43
HTML-объект: & plus; — HTML-код: & # 43;
Математический символ, используемый для сложения, а также понятие положительного
Плюс минус — ±
Знак плюс-минус Unicode: U + 000B1
HTML-объект: & plusmn; — HTML-код: & # 177;
Многозначный математический символ, также обозначаемый как плюс-минус .
Нажатие клавиши ПК: ALT + 0177
Знак фунта
— £
Знак фунта стерлингов Unicode: U + 000A3 — ASCII: —
HTML-объект: & pound; — HTML-код: & # 163;
В США «знак фунта» обозначает знак числа (#). Существует также версия с двойным тире: ₤
Нажатие клавиши ПК: ALT + 0163 — Нажатие клавиши Mac: ОПЦИЯ + 3
Вопросительный знак -?
Вопросительный знак Unicode: U + 0003F — ASCII: 63
HTML-объект: & quest; — HTML-код: & # 63;
Знак препинания для обозначения вопросительного предложения или фразы
Кавычки — »‹ ›« »
Бывают обычные и угловые кавычки.Эти знаки препинания используются для цитат на нескольких языках.
Unicode: U + 00022 — ASCII: 34
HTML-объект: & quot; — HTML-код: & # 34;
Также называется двойной кавычкой . Типографы обычно предпочитают отдельные левые и правые двойные кавычки. Они выглядят так: «» . Также существуют левая и правая одинарные кавычки: ‘’ . Затем есть два так называемых варианта low-9: ‚„ и двойная кавычка high-reverse-9: ‟.
Затем есть два так называемых варианта low-9: ‚„ и двойная кавычка high-reverse-9: ‟.
Одноугольные кавычки
Левый одноугловой кавычки Одинарные угловые кавычки, указывающие влево
Unicode: U + 02039
HTML-объект: & lsaquo; — HTML-код: & # 8249;
Не путать со знаком «меньше» (<)
Одинарная угловая кавычка, указывающая вправо
Unicode: U + 0203A
HTML-объект: & rsaquo; — HTML-код: & # 8250;
Не путать со знаком «больше» (>)
Двойные угловые кавычки
Двойные угловые кавычки также называются гильметами или двойными шевронами
Левая кавычка с двойным углом Двойные угловые кавычки, указывающие влево
Unicode: U + 000AB
HTML-объект: & laquo; — HTML-код: & # 171;
Нажатие клавиши ПК: ALT + 0171
Двойные угловые кавычки, указывающие вправо
Unicode: U + 000BB
HTML-объект: & raquo; — HTML-код: & # 187;
Нажатие клавиши ПК: ALT + 0187
Зарегистрированный знак — ®
Зарегистрированный знак Unicode: U + 000AE — ASCII: —
HTML-объект: & reg; — HTML-код: & # 174;
Также называется Racol .
Нажатие клавиши ПК: ALT + 0174 — Нажатие клавиши Mac: OPTION + R
Рубль —
₽ Знак рубля Юникод: U + 020BD
HTML-код: & # 8318;
Используется для рубля или рубля, валюты России
рупий —
Индийская рупия знак Юникод: U + 020B9
Код HTML: & # 8377;
Используется для рупии, валюты Индии. У рупии есть второй знак: ₨ (Unicode: U + 20A8, HTML-код: & # 8360;). Он используется в других странах, которые также используют рупию, например, в Шри-Ланке, Пакистане и Непале
Знак раздела — §
Знак раздела Unicode: U + 000A7 — ASCII: —
HTML-объект: & sect; — HTML-код: & # 167;
Нажатие клавиши ПК: ALT + 0167
Точка с запятой -;
Точка с запятой Unicode: U + 0003B — ASCII: 59
HTML-объект: & semi; — HTML-код: & # 59;
Слэш — /
Солидус Unicode: U + 0002F — ASCII: 47
HTML-объект: & sol; — HTML-код: & # 47;
Также называется косая черта или штрих (Великобритания).
В Unicode это называется solidus , хотя этот глиф менее вертикальный.
Квадратные скобки — []
Левая скобка Левая квадратная скобка
Юникод: U + 0005B — ASCII: 91
HTML-объект: & lbrack; — HTML-код: & # 91;
Также называется левым крючком или открывающейся скобкой (в США)
Правая скобка
Юникод: U + 0005D — ASCII: 93
HTML-объект: & rbrack; — HTML-код: & # 93;
Также называется правый крючок или закрывающая скоба (в США)
Один надстрочный —
Верхний индекс один Юникод: U + 000B9
HTML-объект: & sup1; — HTML-код: & # 185;
Нажатие клавиши ПК: ALT + 0185
Верхний индекс два — ²
Верхний индекс два Юникод: U + 000B2
HTML-объект: & sup2; — HTML-код: & # 178;
Нажатие клавиши ПК: ALT + 0178
Третий верхний индекс — ³
Верхний индекс три Unicode: U + 000B9
HTML-объект: & sup3; — HTML-код: & # 179;
Нажатие клавиши ПК: ALT + 0179
Тильда — ~
Тильда Unicode: U + 0007E
HTML-объект: & tilde; — HTML-код: & # 126;
Также называется swung dash , sciggly или twiddle .
Нажатие клавиши ПК: ALT + 0126
Знак торговой марки — ™
Знак торговой марки Unicode: U + 02122
HTML-объект: & trade; — HTML-код: & # 8482;
Символ, указывающий на то, что предыдущий знак является незарегистрированным товарным знаком. Для зарегистрированных товарных знаков используется ®.
Нажатие клавиши ПК: ALT + 0153 — Нажатие клавиши Mac: ОПЦИЯ + 2
Подчеркивание — _
Низкая линия Unicode: U + 0005F — ASCII: 95
HTML-объект: & lowbar; — HTML-код: & # 95;
Также известен как low line , low dash или understrike glyph
Нажатие клавиши ПК: ALT + 95
Вертикальная линия — |
Вертикальная линия Юникод: U + 0007C — ASCII: 124
HTML-объект: & vert; — HTML-код: & # 124;
Также называется трубкой , символом трубопровода, штрихом Шеффера , вертикальной косой чертой , думаю, двоеточием или разделительной линией .
Символ, который обычно встречается в операторах, связанных с логикой и задает
нажатие клавиши ПК: ALT + 124
Знак
иен —
¥ Знак иены Unicode: U + 000A5
HTML-код: & yen; — HTML-код: & # 165;
Также используется для китайской валюты Юань
Нажатие клавиши ПК: ALT + 0165 — Нажатие клавиши Mac: OPTION + Y
Другие источники информации
Мне нравятся обзоры TopTal Designers, Penn State и Keynote Support
✔️ ❤️ ★ Таблица символов Юникода
Unicode — это вычислительный стандарт для согласованных символов кодирования.Он был создан в 1991 году. Это просто таблица, которая показывает расположение глифов в системе кодирования. Кодировка берет символ из таблицы и сообщает шрифту, что нужно нарисовать. Но компьютер может понимать только двоичный код. Итак, для представления символов используется кодировка цифрой 1 или 0. Как в азбуке Морзе точки и тире представляют буквы и цифры. Каждый блок (1 или 0) является битом вызова. 16 бит — это два байта. Наиболее известная и часто используемая кодировка — UTF-8. Для представления каждого символа требуется 1 или 4 байта. Старые типы кодирования занимают всего 1 байт, поэтому они не могут содержать достаточно глифов для поддержки более чем одного языка.
Каждый блок (1 или 0) является битом вызова. 16 бит — это два байта. Наиболее известная и часто используемая кодировка — UTF-8. Для представления каждого символа требуется 1 или 4 байта. Старые типы кодирования занимают всего 1 байт, поэтому они не могут содержать достаточно глифов для поддержки более чем одного языка.
символов Unicode
Каждый символ Unicode имеет свой номер и HTML-код. Пример: кириллическая заглавная буква Э имеет номер U + 042D (042D — это шестнадцатеричное число), код & # 1098 ;. В таблице буква Э находится на линии пересечения № 0420 и столбец D. Если вы хотите узнать номер какого-либо символа Unicode, вы можете найти его в таблице. Или вставьте его в строку поиска. Или поиск по описанию («кириллическая буква E»). На странице символа вы можете увидеть, как он выглядит в разных шрифтах и операционных системах.Вы можете скопировать это и вставить в Word или Facebook. Также на этом сайте есть несколько наборов символов для более удобного совладания с ситуацией.
Различные части таблицы Unicode включают множество символов разных языков. Представляют почти все системы письма, которые используются в наши дни. Латинский, арабский, кириллица, иероглифы, пиктографические. Буквы, цифры, знаки препинания. Также стандарт Unicode охватывает множество мертвых шрифтов (abugidas, слоговые алфавиты) с исторической целью. Многие другие символы, не относящиеся к конкретной системе письма, тоже закодированы.Это стрелки, звезды, управляющие символы и т. Д. Все человечество должно создавать качественный текст.
Стандарт Unicode не останавливается, он продолжает развиваться. В июне 2015 года была выпущена версия 8.0. На данный момент закодировано более 120 тысяч символов. Консорциум не создает новые символы, а просто добавляет часто используемые. Лица (смайлы) включены, потому что они часто используются японскими операторами мобильной связи. Но некоторые блоки не содержат принципиальных вопросов. В таблице Unicode нет товарных знаков, даже флага Windows или зарегистрированного товарного знака Apple.
unicode — Что это за символ 😕
РЕДАКТИРОВАТЬ При публикации вопроса персонаж, которого я прошу, был показан мне хорошо, но после публикации он больше не отображается. Поскольку он не отображается, пожалуйста, посмотрите на исходный сайт
РЕДАКТИРОВАТЬ2 Я искал символы Unicode, связанные с «alien», и не нашел подходящих. Вот как они сравниваются бок о бок:
Я обнаружил, что некоторые тексты в моей базе данных содержат символы вроде.Я не уверен, как это будет отображаться с разными шрифтами и средами, поэтому вот изображение, как я его вижу:
Пробовал идентифицировать разными способами. Например, когда я вставляю его в Sublime Text, он автоматически отображается как управляющий символ <0x85> . Когда я пытался идентифицировать его в разных юникод-детекторах (http://www.babelstone.co.uk/Unicode/whatisit.html, https://unicode-table.com/en/, https: // unicode-search . net / unicode-namesearch.pl), их вывод почти такой же:
net / unicode-namesearch.pl), их вывод почти такой же:
Символ кодовой точки Unicode U + 0085
Кодировка UTF-8 c2 85 шестнадцатеричная
1 десятичный
0302 0205 восьмеричный
Имя символа Юникода
Юникод 1.Имя символа 0 (не рекомендуется) NEXT LINE (NEL)
https://unicode-search.net/unicode-namesearch.pl также включены эта информация
Кодировка HTML… & # x85; шестнадцатеричный
… & # 133; десятичный
, что дало мне туманный намек на то, как могло случиться, что ... превратятся в ». Но здесь главная проблема не в этом.
Мой вопрос: как это возможно, чтобы этот управляющий символ отображался вот так и какой на самом деле глиф используется для его представления?
Я попытался сделать набросок в http: // shapecatcher.com /, но безуспешно. Я не нашел такого глифа ни в одной таблице Unicode.
Безболезненное руководство — Настоящий Python
Работа с кодировками символов в Python или любом другом языке временами может показаться болезненной. В таких местах, как Stack Overflow, есть тысячи вопросов, возникающих из-за путаницы с исключениями, такими как UnicodeDecodeError и UnicodeEncodeError . Это руководство предназначено для устранения тумана Exception и демонстрации того, что работа с текстовыми и двоичными данными в Python 3 может быть удобной.Поддержка Unicode в Python сильна и надежна, но для ее освоения требуется время.
Это руководство отличается тем, что оно не зависит от языка, а вместо этого намеренно ориентировано на Python. Вы все равно получите учебник, не зависящий от языка, но затем погрузитесь в иллюстрации на Python с минимальным количеством текстовых абзацев. Вы увидите, как использовать концепции кодировок символов в живом коде Python.
По окончании этого руководства вы получите:
- Получите концептуальные обзоры кодировок символов и систем нумерации
- Узнайте, как кодирование вступает в игру с помощью Python
strибайт - Узнайте о поддержке в Python систем нумерации с помощью различных форм
intлитералов - Ознакомьтесь со встроенными функциями Python, связанными с кодировками символов и системами нумерации.


Системы кодирования символов и нумерации настолько тесно связаны, что их нужно рассматривать в одном учебном пособии, иначе обработка любой из них была бы совершенно неадекватной.
Примечание : Эта статья ориентирована на Python 3. В частности, все примеры кода в этом руководстве были созданы из оболочки CPython 3.7.2, хотя все второстепенные версии Python 3 должны вести себя (в основном) одинаково при обработке текста.
Если вы все еще используете Python 2 и вас пугает разница в том, как Python 2 и Python 3 обрабатывают текстовые и двоичные данные, то, надеюсь, это руководство поможет вам сделать переход.
Что такое кодировка символов?
Существуют десятки, если не сотни кодировок символов.Лучший способ понять, что это такое, — рассмотреть одну из простейших кодировок символов, ASCII.
Независимо от того, являетесь ли вы самоучкой или имеете формальное образование в области информатики, скорее всего, вы видели таблицу ASCII один или два раза. ASCII — хорошее место для начала изучения кодировки символов, потому что это небольшая и ограниченная кодировка. (Как оказалось, слишком мало.)
ASCII — хорошее место для начала изучения кодировки символов, потому что это небольшая и ограниченная кодировка. (Как оказалось, слишком мало.)
Включает:
- Строчные английские буквы : a – z
- Заглавные английские буквы : A от до Z
- Некоторые знаки препинания и символы :
"$"и"!", чтобы назвать пару - Пробельные символы : фактический пробел (
""), а также перевод строки, возврат каретки, горизонтальная табуляция, вертикальная табуляция и некоторые другие - Некоторые непечатаемые символы : символы, такие как backspace,
"\ b", которые нельзя напечатать буквально так, как буква A может
Итак, какое более формальное определение кодировки символов?
На очень высоком уровне это способ преобразования символов (таких как буквы, знаки препинания, символы, пробелы и управляющие символы) в целые числа и, в конечном итоге, в биты. Каждый символ может быть закодирован в уникальную последовательность битов. Не волнуйтесь, если вы не уверены в концепции битов, потому что мы скоро к ним вернемся.
Каждый символ может быть закодирован в уникальную последовательность битов. Не волнуйтесь, если вы не уверены в концепции битов, потому что мы скоро к ним вернемся.
Различные выделенные категории представляют собой группы персонажей. Каждому отдельному символу соответствует кодовая точка , которую вы можете рассматривать как целое число. В таблице ASCII символы разбиты на разные диапазоны:
| Диапазон кодовой точки | Класс |
|---|---|
| от 0 до 31 | Контрольные / непечатаемые символы |
| от 32 до 64 | Пунктуация, символы, числа и пробел |
| 65-90 | Заглавные буквы английского алфавита |
| 91–96 | Дополнительные графемы, например [ и \ |
| 97–122 | Строчные буквы английского алфавита |
| от 123 до 126 | Дополнительные графемы, например { и | |
| 127 | Управляющий / непечатаемый символ ( DEL ) |
Вся таблица ASCII содержит 128 символов. В этой таблице содержится полный набор символов , разрешенный ASCII. Если вы не видите здесь символа, вы просто не можете выразить его как печатный текст в схеме кодировки ASCII.
В этой таблице содержится полный набор символов , разрешенный ASCII. Если вы не видите здесь символа, вы просто не можете выразить его как печатный текст в схеме кодировки ASCII.
| Кодовая точка | Персонаж (Имя) | Кодовая точка | Персонаж (Имя) |
|---|---|---|---|
| 0 | NUL (Нуль) | 64 | @ |
| 1 | SOH (начало заголовка) | 65 | А |
| 2 | STX (начало текста) | 66 | Б |
| 3 | ETX (конец текста) | 67 | К |
| 4 | EOT (конец передачи) | 68 | Д |
| 5 | ENQ (Запрос) | 69 | E |
| 6 | ACK (подтверждение) | 70 | Факс |
| 7 | BEL (Звонок) | 71 | G |
| 8 | BS (Backspace) | 72 | H |
| 9 | HT (горизонтальный выступ) | 73 | Я |
| 10 | LF (перевод строки) | 74 | Дж |
| 11 | VT (вертикальный выступ) | 75 | К |
| 12 | FF (подача формы) | 76 | л |
| 13 | CR (возврат каретки) | 77 | М |
| 14 | SO (сдвиг) | 78 | N |
| 15 | SI (сдвиг внутрь) | 79 | О |
| 16 | DLE (выход из канала передачи данных) | 80 | п |
| 17 | DC1 (Управление устройством 1) | 81 | Q |
| 18 | DC2 (Управление устройством 2) | 82 | R |
| 19 | DC3 (Управление устройством 3) | 83 | S |
| 20 | DC4 (Управление устройством 4) | 84 | Т |
| 21 | NAK (отрицательное подтверждение) | 85 | U |
| 22 | SYN (синхронный холостой ход) | 86 | В |
| 23 | ETB (конец блока передачи) | 87 | Вт |
| 24 | CAN (Отмена) | 88 | х |
| 25 | EM (конец среды) | 89 | Y |
| 26 | SUB (Заменитель) | 90 | Z |
| 27 | ESC (выход) | 91 | [ |
| 28 | FS (Разделитель файлов) | 92 | \ |
| 29 | GS (разделитель групп) | 93 | ] |
| 30 | RS (Разделитель записей) | 94 | ^ |
| 31 | США (разделитель единиц) | 95 | _ |
| 32 | СП (Космос) | 96 | ` |
| 33 | ! | 97 | а |
| 34 | " | 98 | б |
| 35 | # | 99 | с |
| 36 | $ | 100 | д |
| 37 | % | 101 | e |
| 38 | и | 102 | f |
| 39 | ' | 103 | г |
| 40 | ( | 104 | ч |
| 41 | ) | 105 | и |
| 42 | * | 106 | j |
| 43 | + | 107 | к |
| 44 | , | 108 | л |
| 45 | - | 109 | м |
| 46 | . | 110 | n |
| 47 | / | 111 | или |
| 48 | 0 | 112 | п |
| 49 | 1 | 113 | q |
| 50 | 2 | 114 | r |
| 51 | 3 | 115 | с |
| 52 | 4 | 116 | т |
| 53 | 5 | 117 | u |
| 54 | 6 | 118 | v |
| 55 | 7 | 119 | w |
| 56 | 8 | 120 | x |
| 57 | 9 | 121 | y |
| 58 | : | 122 | z |
| 59 | ; | 123 | { |
| 60 | < | 124 | | |
| 61 | = | 125 | } |
| 62 | > | 126 | ~ |
| 63 | ? | 127 | DEL (удалить) |

Строка
Модуль Модуль Python string - это удобный универсальный инструмент для строковых констант, которые попадают в набор символов ASCII.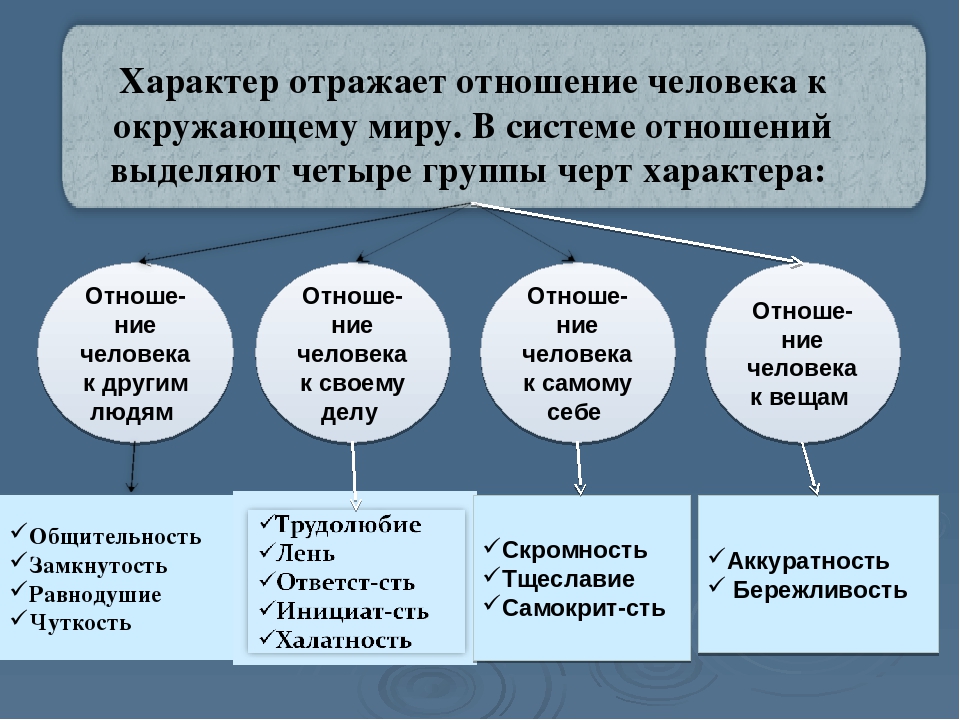 _` {|} ~ "" "
printable = цифры + ascii_letters + пунктуация + пробел
_` {|} ~ "" "
printable = цифры + ascii_letters + пунктуация + пробел
Большинство этих констант должны самодокументироваться в своих именах идентификаторов. Мы скоро рассмотрим, что такое шестнадцатеричных цифр и восьмицифровых цифр .
Эти константы можно использовать для повседневных операций со строками:
>>> >>> импортная строка
>>> s = "Что не так с ASCII?!?!?"
>>> s.rstrip (строка. пунктуация)
"Что не так с ASCII"
Примечание : строка .printable включает в себя все string.whitespace . Это немного не согласуется с другим методом проверки того, считается ли символ пригодным для печати, а именно str.isprintable () , который сообщит вам, что ни один из {'\ v', '\ n', '\ r', '\ f ',' \ t '} считаются пригодными для печати.
Тонкое различие связано с определением: str.isprintable () считает что-то печатаемым, если «все его символы считаются печатаемыми в repr () . ”
”
Немного освежить
Сейчас хорошее время для краткого освежения информации о бит , наиболее фундаментальной единице информации, которую знает компьютер.
Бит — это сигнал, который имеет только два возможных состояния. Есть разные способы символического представления бита, которые означают одно и то же:
- 0 или 1
- «да» или «нет»
-
ВерноилиЛожно - «включено» или «выключено»
В нашей таблице ASCII из предыдущего раздела используется то, что мы с вами называем числами (от 0 до 127), но более точно называемые числами с основанием 10 (десятичными).
Вы также можете выразить каждое из этих чисел с основанием 10 последовательностью битов (основание 2). Вот двоичные версии от 0 до 10 в десятичном виде:
| Десятичное | двоичный (компактный) | Двоичный (заполненная форма) |
|---|---|---|
| 0 | 0 | 00000000 |
| 1 | 1 | 00000001 |
| 2 | 10 | 00000010 |
| 3 | 11 | 00000011 |
| 4 | 100 | 00000100 |
| 5 | 101 | 00000101 |
| 6 | 110 | 00000110 |
| 7 | 111 | 00000111 |
| 8 | 1000 | 00001000 |
| 9 | 1001 | 00001001 |
| 10 | 1010 | 00001010 |
Обратите внимание, что по мере увеличения десятичного числа n вам потребуется больше значащих битов для представления набора символов, включая это число.
Вот удобный способ представить строки ASCII как последовательности битов в Python. Каждый символ из строки ASCII получает псевдокодирование в 8 бит с пробелами между 8-битными последовательностями, каждая из которых представляет один символ:
>>> >>> def make_bitseq (s: str) -> str:
... если не s.isascii ():
... поднять ValueError ("Допускается только ASCII")
... return "" .join (f "{ord (i): 08b}" для i в s)
>>> make_bitseq ("биты")
'01 01 01110100 01110011'
>>> make_bitseq ("CAPS")
'01 01 00 01'
>>> make_bitseq ("25 долларов.43 ")
'00 00110010 00110101 00 00110100 00110011'
>>> make_bitseq ("~ 5")
'01111110 00110101'
Примечание : .isascii () был представлен в Python 3.7.
Строка f f "{ord (i): 08b}" использует мини-язык спецификации формата Python, который является способом определения форматирования для полей замены в строках формата:
Левая часть двоеточия,
ord (i), представляет собой фактический объект, значение которого будет отформатировано и вставлено в вывод. Использование функции Python ord ()дает вам кодовую точку base-10 для одного символаstr.Правая часть двоеточия — это спецификатор формата.
08означает шириной 8, 0 с заполнением , аbдействует как знак для вывода результирующего числа в базе 2 (двоичный).
 Использование функции Python
Использование функции Python Этот трюк предназначен в основном для развлечения, и он очень плохо подойдет для любого символа, который вы не видите в таблице ASCII.Позже мы обсудим, как другие кодировки решают эту проблему.
Нам нужно больше бит!
Есть критически важная формула, связанная с определением бита. Учитывая количество битов, n , количество различных возможных значений, которые могут быть представлены в n битах, составляет 2 n :
def n_possible_values (nbits: int) -> int:
вернуть 2 ** нбит
Вот что это значит:
- 1 бит позволит вам выразить 2 1 == 2 возможных значений.
- 8 бит позволят вам выразить 2 8 == 256 возможных значений.
- 64 бита позволят вам выразить 2 64 == 18,446,744,073,709,551,616 возможных значений.

Из этой формулы следует следствие: учитывая диапазон различных возможных значений, как мы можем найти количество битов, n , которое требуется для полного представления диапазона? Вы пытаетесь найти n в уравнении 2 n = x (где вы уже знаете x ).
Вот что из этого получается:
>>> >>> from math import ceil, log
>>> def n_bits_required (nvalues: int) -> int:
... вернуть ceil (log (nvalues) / log (2))
>>> n_bits_required (256)
8
Причина, по которой вам нужно использовать потолок в n_bits_required () , состоит в том, чтобы учесть значения, которые не являются чистыми степенями 2. Скажем, вам нужно сохранить набор символов из 110 символов. Наивно, это должно занять log (110) / log (2) == 6. бит, но нет такого понятия, как 0,781 бит. 110 значений потребуют 7 бит, а не 6, причем последние слоты не нужны: 781
781
>>> n_bits_required (110)
7
Все это служит доказательством одной концепции: ASCII, строго говоря, является 7-битным кодом. Таблица ASCII, которую вы видели выше, содержит 128 кодовых точек и символов, от 0 до 127 включительно. Для этого требуется 7 бит:
>>> >>> n_bits_required (128) # от 0 до 127
7
>>> n_possible_values (7)
128
Проблема в том, что современные компьютеры ничего не хранят в 7-битных слотах.Они передают данные в единицах по 8 бит, обычно известных как байт .
Примечание : В этом руководстве я предполагаю, что байт относится к 8 битам, как это было с 1960-х годов, а не к какой-либо другой единице хранения. Вы можете называть это октетом октет , если хотите.
Это означает, что дисковое пространство, используемое ASCII, наполовину пусто. Если не ясно, почему это так, вспомните приведенную выше таблицу преобразования десятичных чисел в двоичные. Вы можете выразить числа 0 и 1 всего одним битом, или вы можете использовать 8 бит, чтобы выразить их как 00000000 и 00000001, соответственно.
Если не ясно, почему это так, вспомните приведенную выше таблицу преобразования десятичных чисел в двоичные. Вы можете выразить числа 0 и 1 всего одним битом, или вы можете использовать 8 бит, чтобы выразить их как 00000000 и 00000001, соответственно.
Вы, , можете выразить числа от 0 до 3 всего с 2 битами или от 00 до 11, или вы можете использовать 8 бит, чтобы выразить их как 00000000, 00000001, 00000010 и 00000011 соответственно. Самая высокая кодовая точка ASCII, 127, требует только 7 значащих битов.
Зная это, вы можете видеть, что make_bitseq () преобразует строки ASCII в представление байтов str , где каждый символ занимает один байт:
>>> make_bitseq ("биты")
'01 01 01110100 01110011'
Недостаточное использование ASCII 8-битных байтов, предлагаемых современными компьютерами, привело к семейству конфликтующих, неформальных кодировок, каждая из которых определяла дополнительные символы, которые должны использоваться с оставшимися 128 доступными кодовыми точками, разрешенными в схеме кодирования 8-битных символов.
Эти разные кодировки не только конфликтовали друг с другом, но и каждая из них сама по себе оставалась крайне неполным представлением персонажей мира, несмотря на то, что они использовали один дополнительный бит.
Спустя годы одна мега-схема кодирования символов стала управлять всеми ими. Однако, прежде чем мы перейдем к делу, давайте немного поговорим о системах нумерации, которые являются фундаментальной основой схем кодирования символов.
Покрытие всех баз: другие системы счисления
При обсуждении ASCII выше вы видели, что каждый символ отображается на целое число в диапазоне от 0 до 127.
Этот диапазон чисел выражается в десятичной системе счисления (основание 10). Это способ, которым вы, я и остальные из нас, людей, привыкли считать, и нет более сложной причины, чем то, что у нас 10 пальцев.
Но есть и другие системы нумерации, которые особенно распространены в исходном коде CPython. Хотя «основное число» одинаково, все системы нумерации — это просто разные способы выражения одного и того же числа.
Если бы я спросил вас, какое число представляет строка "11" , вы были бы правы, бросив на меня странный взгляд, прежде чем ответить, что оно представляет собой одиннадцать.
Однако это строковое представление может выражать разные базовые числа в разных системах нумерации. В дополнение к десятичной системе счисления альтернативы включают следующие общие системы нумерации:
- Двоичный : базовый 2
- Octal : base 8
- Шестнадцатеричное (шестнадцатеричное) : основание 16
Но что для нас означает утверждение, что в определенной системе счисления числа представлены в базе N ?
Вот лучший из известных мне способов сформулировать, что это означает: это количество пальцев, на которые вы рассчитываете в этой системе.
Если вам нужно гораздо более полное, но все же мягкое введение в системы нумерации, книга Чарльза Петцольда Code — невероятно крутая книга, в которой подробно исследуются основы компьютерного кода.
Один из способов продемонстрировать, как разные системы нумерации интерпретируют одно и то же, — использовать конструктор Python int () . Если вы передадите str в int () , Python по умолчанию будет считать, что строка выражает число в базе 10, если вы не укажете иное:
>>> int ('11 ')
11
>>> int ('11 ', base = 10) # 10 уже по умолчанию
11
>>> int ('11 ', base = 2) # Двоичный
3
>>> int ('11 ', base = 8) # Восьмеричный
9
>>> int ('11 ', base = 16) # Шестнадцатеричный
17
Есть более распространенный способ сообщить Python, что ваше целое число набрано с основанием, отличным от 10.Python принимает буквальных форм каждой из трех альтернативных систем нумерации, указанных выше:
| Тип литерала | Префикс | Пример |
|---|---|---|
| н / д | н / д | 11 |
| Двоичный литерал | 0b или 0B | 0b11 |
| Восьмеричный литерал | 0o или 0O | 0o11 |
| Шестнадцатеричный литерал | 0x или 0X | 0x11 |
Все это подформы целочисленных литералов .Вы можете видеть, что они дают те же результаты, соответственно, что и вызовы int () с нестандартными значениями base . Все они просто от до Python:
>>> 11
11
>>> 0b11 # Двоичный литерал
3
>>> 0o11 # Восьмеричный литерал
9
>>> 0x11 # шестнадцатеричный литерал
17
Вот как вы можете ввести двоичные, восьмеричные и шестнадцатеричные эквиваленты десятичных чисел от 0 до 20. Любой из них совершенно допустим в оболочке интерпретатора Python или в исходном коде, и все они имеют тип int :
| Десятичное | двоичный | восьмеричное | шестигранник |
|---|---|---|---|
0 | 0b0 | 0o0 | 0x0 |
1 | 0b1 | 0o1 | 0x1 |
2 | 0b10 | 0o2 | 0x2 |
3 | 0b11 | 0o3 | 0x3 |
4 | 0b100 | 0o4 | 0x4 |
5 | 0b101 | 0o5 | 0x5 |
6 | 0b110 | 0o6 | 0x6 |
7 | 0b111 | 0o7 | 0x7 |
8 | 0b1000 | 0o10 | 0x8 |
9 | 0b1001 | 0o11 | 0x9 |
10 | 0b1010 | 0o12 | 0xa |
11 | 0b1011 | 0o13 | 0xb |
12 | 0b1100 | 0o14 | 0xc |
13 | 0b1101 | 0o15 | 0xd |
14 | 0b1110 | 0o16 | 0xe |
15 | 0b1111 | 0о17 | 0xf |
16 | 0b10000 | 0o20 | 0x10 |
17 | 0b10001 | 0o21 | 0x11 |
18 | 0b10010 | 0o22 | 0x12 |
19 | 0b10011 | 0o23 | 0x13 |
20 | 0b10100 | 0o24 | 0x14 |
Удивительно, насколько распространены эти выражения в стандартной библиотеке Python.Если вы хотите в этом убедиться, перейдите туда, где находится ваш каталог lib / python3.7 / , и проверьте использование шестнадцатеричных литералов, например:
$ grep -nri --include "* \. Py" -e "\ b0x" lib / python3.7
Это должно работать в любой системе Unix, имеющей grep . Вы можете использовать «\ b0o» для поиска восьмеричных литералов или «\ b0b» для поиска двоичных литералов.
Каков аргумент в пользу использования этих альтернативных синтаксисов литералов int ? Короче говоря, это потому, что 2, 8 и 16 — это степени двойки, а 10 — нет.Эти три альтернативные системы счисления иногда предлагают способ выражения значений удобным для компьютера способом. Например, число 65536 или 2 16 — это всего лишь 10000 в шестнадцатеричном виде или 0x10000 в шестнадцатеричном формате Python.
Введите Unicode
Как вы видели, проблема с ASCII заключается в том, что это не достаточно большой набор символов, чтобы вместить мировой набор языков, диалектов, символов и глифов. (Его даже недостаточно для одного английского.)
Unicode в основном служит той же цели, что и ASCII, но он просто охватывает способ, путь, , способ большего набора кодовых точек. Есть несколько кодировок, которые возникли в хронологическом порядке между ASCII и Unicode, но на самом деле о них пока не стоит упоминать, потому что Unicode и одна из его схем кодирования, UTF-8, стали широко использоваться.
Думайте о Unicode как об огромной версии таблицы ASCII — той, которая имеет 1 144 112 возможных кодовых точек. Это от 0 до 1,114,111 или от 0 до 17 * (2 16 ) — 1 или 0x10ffff в шестнадцатеричном формате.Фактически, ASCII — идеальное подмножество Unicode. Первые 128 символов в таблице Unicode в точности соответствуют символам ASCII, которые, как вы разумно ожидали, от них будут.
Для обеспечения технической точности, Unicode — это , а не как кодировка . Скорее, Unicode реализован с помощью различных кодировок символов, которые вы скоро увидите. Unicode лучше рассматривать как карту (что-то вроде dict ) или таблицу базы данных с двумя столбцами.Он отображает символы (например, "a" , "" или даже "ቈ" ) в различные положительные целые числа. Кодировка символов должна предлагать немного больше.
Unicode содержит практически все символы, которые вы можете себе представить, включая дополнительные непечатаемые. Один из моих любимых — надоедливый знак письма справа налево, который имеет кодовую точку 8207 и используется в тексте с языковыми скриптами как слева направо, так и справа налево, например в статьях, содержащих абзацы на английском и арабском языках. .
Примечание: Мир кодировок символов — одна из многих тонких технических деталей, над которыми некоторые люди любят придирчиво. Одна из таких деталей заключается в том, что фактически можно использовать только 1111998 кодовых точек Unicode по нескольким архаичным причинам.
Unicode против UTF-8
Людям не потребовалось много времени, чтобы понять, что все символы мира не могут быть упакованы в один байт каждый. Из этого очевидно, что современные, более полные кодировки должны использовать несколько байтов для кодирования некоторых символов.
Вы также видели выше, что Unicode технически не является полноценной кодировкой символов. Это почему?
Есть одна вещь, о которой Unicode не говорит вам: он не говорит вам, как получить фактические биты из текста, а только кодовые точки. В нем недостаточно информации о том, как преобразовать текст в двоичные данные и наоборот.
Unicode — это абстрактный стандарт кодирования, а не кодирование. Вот где в игру вступают UTF-8 и другие схемы кодирования. Стандарт Unicode (карта символов для кодовых точек) определяет несколько различных кодировок из своего единственного набора символов.
UTF-8, а также его менее используемые родственники, UTF-16 и UTF-32, являются форматами кодирования для представления символов Unicode в виде двоичных данных из одного или нескольких байтов на символ. Мы обсудим UTF-16 и UTF-32 чуть позже, но UTF-8 на сегодняшний день занял большую часть пирога.
Это подводит нас к давно назревшему определению. Что означает формально кодировать и декодировать ?
Кодирование и декодирование в Python 3
Тип Python 3 str предназначен для представления удобочитаемого текста и может содержать любой символ Unicode.
Напротив, байтов Тип представляет двоичные данные или последовательности необработанных байтов, которые по сути не имеют прикрепленной к нему кодировки.
Кодирование и декодирование — это процесс перехода от одного к другому:
Кодирование и декодирование (Изображение: Real Python) В .encode () и .decode () параметр кодировки по умолчанию равен «utf-8» , хотя, как правило, безопаснее и однозначнее указывать это:
>>> "резюме".кодировать ("utf-8")
b'r \ xc3 \ xa9sum \ xc3 \ xa9 '
>>> "Эль-Ниньо" .encode ("utf-8")
b'El Ni \ xc3 \ xb1o '
>>> b "r \ xc3 \ xa9sum \ xc3 \ xa9" .decode ("utf-8")
'продолжить'
>>> b "Эль-Нинь \ xc3 \ xb1o" .decode ("utf-8")
'Эль-Ниньо'
Результатом str.encode () является объект байтов байт. Оба байтовых литерала (например, b "r \ xc3 \ xa9sum \ xc3 \ xa9" ) и представления байтов допускают только символы ASCII.
Вот почему при вызове «Эль-Ниньо».encode ("utf-8") , ASCII-совместимый "El" может быть представлен как есть, но n с тильдой заменяется на "\ xc3 \ xb1" . Эта запутанная последовательность представляет собой два байта, 0xc3 и 0xb1 в шестнадцатеричном формате:
>>> "" .join (f "{i: 08b}" для i in (0xc3, 0xb1))
'11 01'
То есть для символа - требуется два байта для его двоичного представления в UTF-8.
Примечание . Если вы наберете help (str.encode) , вы, вероятно, увидите значение по умолчанию: encoding = 'utf-8' . Будьте осторожны, исключая это и просто используйте "резюме" .encode () , потому что значение по умолчанию может быть другим в Windows до Python 3.6.
Python 3: все на Unicode
Python 3 полностью использует Unicode и UTF-8. Вот что это значит:
Исходный код Python 3 по умолчанию считается UTF-8.Это означает, что вам не нужна кодировка
# - * -: UTF-8 - * -в верхней части файлов.pyв Python 3.Весь текст (
str) по умолчанию - Unicode. Закодированный текст Unicode представлен как двоичные данные (байт,). Типstrможет содержать любой буквальный символ Юникода, например«Δv / Δt», все из которых будут сохранены как Unicode.Python 3 принимает в идентификаторах множество кодовых точек Unicode, что означает
résumé = "~ / Documents / resume.pdf "действителен, если вам это интересно.Модуль Python
reпо умолчанию использует флагre.UNICODE, а неre.ASCII. Это означает, например, чтоr "\ w"соответствует символам слова Unicode, а не только буквам ASCII.По умолчанию
кодируетвstr.encode ()иbytes.decode ()- это UTF-8.
Есть еще одно свойство, которое является более тонким, а именно то, что кодировка по умолчанию для встроенного open () зависит от платформы и значения локали .getpreferredencoding () :
>>> # Mac OS X High Sierra
>>> импортировать локаль
>>> locale.getpreferredencoding ()
'UTF-8'
>>> # Windows Server 2012; другие сборки Windows могут использовать UTF-16
>>> импортировать локаль
>>> locale.getpreferredencoding ()
'cp1252'
Опять же, урок здесь состоит в том, чтобы быть осторожным, делая предположения, когда дело доходит до универсальности UTF-8, даже если это преобладающая кодировка. Никогда не помешает быть явным в вашем коде.
Один байт, два байта, три байта, четыре
Важнейшей особенностью является то, что UTF-8 представляет собой кодировку переменной длины . Заманчиво замалчивать, что это означает, но стоит вникнуть.
Вернитесь к разделу, посвященному ASCII. Все в расширенной области ASCII требует не более одного байта пространства. Вы можете быстро доказать это с помощью следующего выражения генератора:
>>> >>> all (len (chr (i) .encode ("ascii")) == 1 для i в диапазоне (128))
Истинный
UTF-8 совсем другой.Данный символ Unicode может занимать от одного до четырех байтов. Вот пример одного символа Юникода, занимающего четыре байта:
>>> >>> ibrow = "🤨"
>>> len (ibrow)
1
>>> ibrow.encode ("utf-8")
б '\ xf0 \ x9f \ xa4 \ xa8'
>>> len (ibrow.encode ("utf-8"))
4
>>> # Calling list () для байтового объекта дает вам
>>> # десятичное значение для каждого байта
>>> список (b '\ xf0 \ x9f \ xa4 \ xa8')
[240, 159, 164, 168]
Это тонкая, но важная особенность len () :
- Длина одного символа Юникода в Python
strбудет всегда равняется 1, независимо от того, сколько байтов он занимает. - Длина одного и того же символа, закодированного в
байтов,будет где-то между 1 и 4.
В таблице ниже приведены общие типы символов, которые помещаются в каждый сегмент длины байта:
| Десятичный диапазон | Hex Диапазон | Что включено | Примеры |
|---|---|---|---|
| от 0 до 127 | "\ u0000" до "\ u007F" | США ASCII | "A" , "\ n" , "7" , "&" |
| 128 до 2047 | "\ u0080" до "\ u07FF" | Большинство латинских алфавитов * | "ę" , "±" , "" , "ñ" |
| 2048 до 65535 | "\ u0800" до "\ uFFFF" | Дополнительные детали многоязычного самолета (БМП) ** | "" , "" , "ᮈ" , "‰" |
| 65536 до 1114111 | "\ U00010000" до "\ U0010FFFF" | Другое *** | "" , "𐀀" , "" , "🂲" , |
* Например, английский, арабский, греческий и ирландский
** Огромный набор языков и символов - в основном китайский, японский и корейский по объему (также ASCII и латинский алфавиты)
*** Дополнительный китайский , Японские, корейские и вьетнамские символы, а также другие символы и смайлы
Примечание : Чтобы не упустить из виду общую картину, существует дополнительный набор технических возможностей UTF-8, которые здесь не рассматриваются, поскольку они редко видны пользователю Python.
Например, UTF-8 фактически использует коды префикса, которые указывают количество байтов в последовательности. Это позволяет декодеру определять, какие байты принадлежат друг другу при кодировании переменной длины, и позволяет первому байту служить индикатором количества байтов в предстоящей последовательности.
В статьеWikipedia, посвященной UTF-8, не обойтись без технических подробностей, и всегда существует официальный стандарт Unicode, который поможет вам при чтении.
А как насчет UTF-16 и UTF-32?
Вернемся к двум другим вариантам кодировки, UTF-16 и UTF-32.
На практике разница между ними и UTF-8 существенна. Вот пример того, насколько велика разница при двустороннем преобразовании:
>>> >>> letter = "αβγδ"
>>> rawdata = letter.encode ("utf-8")
>>> rawdata.decode ("utf-8")
'αβγδ'
>>> rawdata.decode ("utf-16") # 😧
'뇎닎 돎듎'
В этом случае кодирование четырех греческих букв с помощью UTF-8 и последующее декодирование обратно в текст в UTF-16 приведет к созданию текста str , который написан на совершенно другом языке (корейском).
Совершенно неверные результаты, подобные этому, возможны, если одна и та же кодировка не используется в двух направлениях. Два варианта декодирования одного и того же объекта байтов байтов могут давать результаты, которые даже не на одном языке.
В этой таблице указаны диапазон или количество байтов в UTF-8, UTF-16 и UTF-32:
| Кодировка | байтов на символ (включительно) | переменной длины |
|---|---|---|
| UTF-8 | от 1 до 4 | Есть |
| UTF-16 | от 2 до 4 | Есть |
| UTF-32 | 4 | № |
Еще одним любопытным аспектом семейства UTF является то, что UTF-8 не всегда занимает меньше места, чем UTF-16.Это может показаться математически нелогичным, но вполне возможно:
>>> >>> text = "記者 鄭啟源 羅智堅"
>>> len (text.encode ("utf-8"))
26
>>> len (text.encode ("utf-16"))
22
Причина этого в том, что кодовые точки в диапазоне от U + 0800 до U + FFFF (от 2048 до 65535 в десятичной форме) занимают три байта в UTF-8 по сравнению с двумя в UTF-16.
Я ни в коем случае не рекомендую вам садиться в поезд UTF-16, независимо от того, работаете ли вы на языке, символы которого обычно находятся в этом диапазоне.Среди прочего, одним из веских аргументов в пользу использования UTF-8 является то, что в мире кодирования отличная идея - сливаться с толпой.
Не говоря уже о том, что это 2019 год: память компьютера дешевая, поэтому экономия 4 байтов за счет использования UTF-16, вероятно, не стоит того.
Встроенные функции Python
Вы прошли через трудную часть. Пришло время использовать то, что вы уже видели в Python.
Python имеет группу встроенных функций, которые так или иначе связаны с системами нумерации и кодировкой символов:
Их можно логически сгруппировать в зависимости от их назначения:
ascii (),bin (),hex ()иoct ()предназначены для получения другого представления ввода.Каждый производитstr. Первый,ascii (), создает представление объекта только в формате ASCII с экранированными символами, отличными от ASCII. Остальные три дают двоичное, шестнадцатеричное и восьмеричное представление целого числа соответственно. Это всего лишь представлений , а не фундаментальное изменение ввода.байтов (),str ()иint ()- это конструкторы классов для соответствующих типов,байтов,strиint.Каждый из них предлагает способы принуждения ввода к желаемому типу. Например, как вы видели ранее, хотяint (11.0), вероятно, более распространен, вы также можете увидетьint ('11 ', base = 16).ord ()иchr ()являются инверсиями друг друга в том смысле, что функция Pythonord ()преобразует символstrв его кодовую точку base-10, аchr ()делает противоположный.
Вот более подробный взгляд на каждую из этих девяти функций:
| Функция | Подпись | принимает | Тип возврата | Назначение |
|---|---|---|---|---|
ascii () | ascii (obj) | Различается | ул. | Представление объекта только в формате ASCII, с экранированными символами, отличными от ASCII |
бункер () | бин (номер) | номер: внутренний | ул. | Двоичное представление целого числа с префиксом «0b» |
байт () | байтов (iterable_of_ints) | Различается | байтов | Преобразование входных данных в байтов , сырые двоичные данные |
chr () | chr (i) | i: int | ул. | Преобразование целочисленной кодовой точки в один символ Юникода |
шестигранник () | шестнадцатеричный (номер) | номер: внутренний | ул. | Шестнадцатеричное представление целого числа с префиксом «0x» |
внутр () | int ([x]) | Различается | внутренний | Coerce (преобразовать) вход в int |
окт. () | окт (номер) | номер: внутренний | ул. | Восьмеричное представление целого числа с префиксом "0o" |
ord () | или в) | c: str | внутренний | Преобразование одиночного символа Юникода в его целочисленную кодовую точку |
ул. () | str (object = ’‘) | Различается | ул. | Привести (преобразовать) вход в str , текст |
Вы можете развернуть раздел ниже, чтобы увидеть несколько примеров каждой функции.
ascii () дает представление объекта только в формате ASCII с экранированными символами, отличными от ASCII:
>>> ascii ("abcdefg")
"abcdefg"
>>> ascii ("халепеньо")
"'Джалепе \\ xf1o'"
>>> ascii ((1, 2, 3))
'(1, 2, 3)'
>>> ascii (0xc0ffee) # Шестнадцатеричный литерал (int)
"12648430"
bin () дает двоичное представление целого числа с префиксом «0b» :
>>> корзина (0)
'0b0'
>>> корзина (400)
'0b100'
>>> bin (0xc0ffee) # Шестнадцатеричный литерал (int)
'0b101111111111'
>>> [bin (i) for i in [1, 2, 4, 8, 16]] # `int` + понимание списка
['0b1', '0b10', '0b100', '0b1000', '0b10000']
байтов () переводит вход в байтов , представляя необработанные двоичные данные:
>>> # Итерация целых чисел
>>> байты ((104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100))
привет мир
>>> bytes (range (97, 123)) # Итерация целых чисел
b'abcdefghijklmnopqrstuvwxyz '
>>> bytes ("real 🐍", "utf-8") # Строка + кодировка
б'реал \ xf0 \ x9f \ x90 \ x8d '
>>> байтов (10)
б '\ x00 \ x00 \ x00 \ x00 \ x00 \ x00 \ x00 \ x00 \ x00 \ x00'
>>> байтов.fromhex ('c0 ff ee')
б '\ xc0 \ xff \ xee'
>>> bytes.fromhex ("72 65 61 6c 70 79 74 68 6f 6e")
b 'альпифон'
chr () преобразует целочисленную кодовую точку в один символ Unicode:
>>> chr (97)
'а'
>>> chr (7048)
'ᮈ'
>>> chr (1114111)
'\ U0010ffff'
>>> chr (0x10FFFF) # Шестнадцатеричный литерал (int)
'\ U0010ffff'
>>> chr (0b01) # Двоичный литерал (int)
'd'
hex () дает шестнадцатеричное представление целого числа с префиксом «0x» :
>>> шестнадцатеричный (100)
'0x64'
>>> [hex (i) для i в [1, 2, 4, 8, 16]]
['0x1', '0x2', '0x4', '0x8', '0x10']
>>> [hex (i) для i в диапазоне (16)]
['0x0', '0x1', '0x2', '0x3', '0x4', '0x5', '0x6', '0x7',
'0x8', '0x9', '0xa', '0xb', '0xc', '0xd', '0xe', '0xf']
int () приводит к вводу int , опционально интерпретируя ввод в заданной базе:
>>> int (11.0)
11
>>> int ('11 ')
11
>>> int ('11 ', основание = 2)
3
>>> int ('11 ', основание = 8)
9
>>> int ('11 ', основание = 16)
17
>>> int (0xc0ffee - 1.0)
12648429
>>> int.from_bytes (b "\ x0f", "маленький")
15
>>> int.from_bytes (b '\ xc0 \ xff \ xee', "большой")
12648430
Функция Python ord () преобразует один символ Юникода в его целочисленный код:
>>> ord ("а")
97
>>> ord ("ę")
281
>>> ord ("ᮈ")
7048
>>> [ord (i) вместо i в "привет, мир"]
[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
str () приводит к вводу str , представляя текст:
>>> str ("строка строки")
'строка строки'
>>> str (5)
'5'
>>> str ([1, 2, 3, 4]) # Как [1, 2, 3, 4].__str __ (), но используйте str ()
'[1, 2, 3, 4]'
>>> str (b "\ xc2 \ xbc чашка муки", "utf-8")
Стакана муки
>>> str (0xc0ffee)
"12648430"
Строковые литералы Python: способы снять шкуру с кошки
Вместо того, чтобы использовать конструктор str () , принято вводить str буквально:
>>> еда = "креветки и крупа"
Это может показаться достаточно простым. Но интересная сторона дела заключается в том, что, поскольку Python 3 полностью ориентирован на Unicode, вы можете «набирать» символы Unicode, которые вы, вероятно, даже не найдете на своей клавиатуре.Вы можете скопировать и вставить это прямо в оболочку интерпретатора Python 3:
>>> >>> алфавит = 'αβγδεζηθικλμνξοπρςστυφχψ'
>>> печать (алфавит)
αβγδεζηθικλμνξοπρςστυφχψ
Помимо размещения фактических, неэкранированных символов Unicode в консоли, есть и другие способы ввода строк Unicode.
Один из самых плотных разделов документации Python - это раздел, посвященный лексическому анализу, особенно раздел, посвященный строковым и байтовым литералам.Лично мне пришлось прочитать этот раздел один, два или, может быть, девять раз, чтобы он действительно проникся.
Частично в нем говорится, что существует до шести способов, которыми Python позволяет вам вводить один и тот же символ Unicode.
Первый и самый распространенный способ - ввести буквальный текст самого символа, как вы уже видели. Самая сложная часть этого метода - найти фактические нажатия клавиш. Вот где в игру вступают другие методы получения и представления персонажей. Вот полный список:
| Последовательность выхода | Значение | Как выразить "а" |
|---|---|---|
"\ ooo" | Знак с восьмеричным числом ооо | "\ 141" |
"\ xhh" | Символ с шестнадцатеричным значением hh | "\ x61" |
"\ N {name}" | Персонаж с именем имя в базе данных Unicode | "\ N {СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A}" |
"\ uxxxx" | Символ с 16-битным (2-байтовым) шестнадцатеричным значением xxxx | "\ u0061" |
"\ Uxxxxxxxx" | Символ с 32-битным (4-байтовым) шестнадцатеричным значением xxxxxxxx | "\ U00000061" |
Вот некоторые доказательства и подтверждения вышеизложенного:
>>> >>> (
... "а" ==
... "\ x61" ==
... "\ N {СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A}" ==
... "\ u0061" ==
... "\ U00000061"
...)
Истинный
Есть два основных предостережения:
Не все эти формы подходят для всех персонажей. Шестнадцатеричное представление целого числа 300 - это
0x012c, что просто не подходит для 2-значного escape-кода"\ xhh". Наивысшая кодовая точка, которую вы можете втиснуть в эту escape-последовательность, -"\ xff"("ÿ").Аналогично для"\ ooo", он будет работать только до"\ 777"("ǿ").Для
\ xhh,\ uxxxxи\ Uxxxxxxxxтребуется ровно столько цифр, сколько показано в этих примерах. Это может вызвать зацикливание из-за того, что в таблицах Unicode обычно отображаются коды символов с ведущимиU +и переменным количеством шестнадцатеричных символов. Ключевым моментом является то, что таблицы Unicode чаще всего не дополняют эти коды нулями.
Например, если вы обратитесь на unicode-table.com за информацией о готической букве faihu (или fehu), "𐍆" , вы увидите, что она указана как имеющая код U + 10346 .
Как поместить это в "\ uxxxx" или "\ Uxxxxxxxx" ? Что ж, вы не можете поместить его в "\ uxxxx" , потому что это 4-байтовый символ, и чтобы использовать "\ Uxxxxxxxx" для представления этого символа, вам нужно будет ввести последовательность слева:
>>> "\ U00010346"
'𐍆'
Это также означает, что форма "\ Uxxxxxxxx" является единственной управляющей последовательностью, которая может содержать любой -й символ Unicode.
Примечание : Вот короткая функция для преобразования строк, которые выглядят как "U + 10346" , в нечто, с чем может работать Python. Он использует str.zfill () :
>>> def make_uchr (код: str):
... вернуть chr (int (code.lstrip ("U +"). zfill (8), 16))
>>> make_uchr ("U + 10346")
'𐍆'
>>> make_uchr ("U + 0026")
'&'
Другие кодировки, доступные в Python
На данный момент вы видели четыре кодировки символов:
- ASCII
- UTF-8
- UTF-16
- UTF-32
Есть масса других.
Одним из примеров является Latin-1 (также называемый ISO-8859-1), который технически является значением по умолчанию для протокола передачи гипертекста (HTTP) согласно RFC 2616. Windows имеет свой собственный вариант Latin-1, называемый cp1252.
Примечание : ISO-8859-1 все еще широко распространен в дикой природе. Библиотека запросов следует RFC 2616 «в буквальном смысле» в использовании ее в качестве кодировки по умолчанию для содержимого ответа HTTP или HTTPS. Если слово «текст» найдено в заголовке Content-Type и не указана другая кодировка, тогда запросы будут использовать ISO-8859-1.
Полный список принятых кодировок скрыт в документации для модуля кодеков , который является частью стандартной библиотеки Python.
Есть еще одна полезная распознанная кодировка, о которой следует знать, это "unicode-escape" . Если у вас есть декодированный str и вы хотите быстро получить представление его экранированного литерала Unicode, вы можете указать эту кодировку в .encode () :
>>> alef = chr (1575) # Или "\ u0627"
>>> alef_hamza = chr (1571) # Или "\ u0623"
>>> алеф, алеф_хамза
('ا', 'أ')
>>> алеф.кодировать ("unicode-escape")
б '\\ u0627'
>>> alef_hamza.encode ("unicode-escape")
б '\\ u0623'
Вы знаете, что говорят о предположениях…
Тот факт, что Python делает допущение о кодировке UTF-8 для файлов и кода, который генерирует , который вы генерируете , не означает, что вы, программист, должны работать с такими же предположениями для внешних данных.
Скажем так, потому что это правило, по которому нужно жить: когда вы получаете двоичные данные (байты) из стороннего источника, будь то из файла или по сети, лучше всего проверить, что данные указывают кодировку. .Если нет, то спросите сами.
Все операции ввода-вывода происходят в байтах, а не в тексте, и байты для компьютера - это только единицы и нули, пока вы не укажете иное, сообщив ему кодировку.
Вот пример того, где что-то может пойти не так. Вы подписаны на API, который отправляет вам рецепт дня, который вы получаете в байтах и всегда без проблем декодировали с помощью .decode ("utf-8") . В этот день часть рецепта выглядит так:
>>> data = b "\ xbc чашка муки"
Похоже, рецепт требует немного муки, но мы не знаем, сколько:
>>> >>> данные.декодировать ("utf-8")
Отслеживание (последний вызов последний):
Файл "", строка 1, в
UnicodeDecodeError: кодек utf-8 не может декодировать байт 0xbc в позиции 0: недопустимый начальный байт
Эээ . Есть эта надоедливая ошибка UnicodeDecodeError , которая может укусить вас, когда вы делаете предположения о кодировании. Вы уточняете у хоста API. И вот, данные на самом деле отправляются в кодировке Latin-1:
>>> data.decode ("латиница-1")
Стакана муки
Ну вот.В Latin-1 каждый символ помещается в один байт, тогда как символ «¼» занимает два байта в UTF-8 ( "\ xc2 \ xbc" ).
Урок здесь в том, что может быть опасно предполагать кодировку любых данных, которые передаются вам. В наши дни это , обычно это UTF-8, но это небольшой процент случаев, когда это не приведет к взрыву.
Если вам действительно нужно отказаться от поставки и угадать кодировку, взгляните на библиотеку chardet , которая использует методологию Mozilla, чтобы сделать обоснованное предположение о неоднозначно закодированном тексте.Тем не менее, такой инструмент, как chardet , должен быть вашим последним средством, а не первым.
Шансы и окончания:
unicodedata Было бы упущением не упомянуть unicodedata из стандартной библиотеки Python, которая позволяет вам взаимодействовать и выполнять поиск в базе данных символов Unicode (UCD):
>>> импортировать unicodedata
>>> unicodedata.name ("€")
'ЗНАК ЕВРО'
>>> unicodedata.lookup («ЗНАК ЕВРО»)
'€'
Заключение
В этой статье вы раскрыли обширную и впечатляющую тему кодировки символов в Python.
Здесь вы много узнали:
- Основные понятия кодировок символов и систем нумерации
- Целочисленные, двоичные, восьмеричные, шестнадцатеричные, строковые и байтовые литералы в Python
- Встроенные функции Python, связанные с системами кодировки и нумерации символов
- Обработка текста в Python 3 по сравнению с двоичными данными
Теперь идите и кодируйте!
Ресурсы
Чтобы получить более подробную информацию о затронутых здесь темах, посетите эти ресурсы:
В документации Python есть две страницы по теме:
Кодировка HTML
Для правильного отображения HTML-страницы веб-браузер должен знать какой набор символов использовать.
Из ASCII в UTF-8
ASCII был первым стандартом кодировки символов. ASCII определяет 128 различных символов, которые могут использоваться в Интернете: цифры (0-9), английские буквы (A-Z) и некоторые специальные персонажи нравятся! $ + - () @ <>.
ISO-8859-1 был набором символов по умолчанию для HTML 4. Этот набор символов поддерживаются 256 различных кодов символов. HTML 4 также поддерживает UTF-8.
ANSI (Windows-1252) был исходным набором символов Windows.ANSI идентичен согласно ISO-8859-1, за исключением того, что ANSI содержит 32 дополнительных символа.
Спецификация HTML5 поощряет веб-разработчиков использовать символ UTF-8. набор, который охватывает почти все персонажи и символы в мире!
Атрибут кодировки HTML
Чтобы правильно отображать HTML-страницу, веб-браузер должен знать набор символов, используемый на странице.
Это указано в теге :
Различия между наборами символов
В следующей таблице показаны различия между наборами символов, описанными выше:
| Число | ASCII | ANSI | 8859 | UTF-8 | Описание | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 32 | пространство | |||||||||||||||||||||
| 33 | ! | ! | ! | ! | восклицательный знак | |||||||||||||||||
| 34 | " | " | " | " | кавычка | |||||||||||||||||
| 35 | # | # | # | # | # | # | # | 36 | $ | $ | $ | $ | знак доллара | |||||||||
| 37 | % | % | % | % | знак процента | и | и | амперсанд | ||||||||||||||
| 39 | ' | ' | ' | ' | апостроф | |||||||||||||||||
| 40 | 62 (||||||||||||||||||||||
| 41 | ) | ) | ) | ) | правая скобка | |||||||||||||||||
| 42 | 9 1062 ** | * | * | звездочка | ||||||||||||||||||
| 43 | + | + | + | + | плюс знак | 63 | , | запятая | ||||||||||||||
| 45 | - | - | - | - | дефис-минус | |||||||||||||||||
| 46 | . | . | . | . | полная остановка | |||||||||||||||||
| 47 | / | / | / | / | солидус | |||||||||||||||||
| 48 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | цифра один | |||||||||||||
| 50 | 2 | 2 | 2 | 2 | 51 цифра 2 | 62 33 | цифра три | |||||||||||||||
| 52 | 4 | 4 | 4 | 4 | цифра четыре | |||||||||||||||||
| 53 | 5 | 62|||||||||||||||||||||
| 54 | 6 | 6 | 6 | 6 | цифра шесть | |||||||||||||||||
| 55 | 7 | 7 | 910 62 77 | цифра семь | ||||||||||||||||||
| 56 | 8 | 8 | 8 | 8 | цифра восемь | |||||||||||||||||
| 57 | 9 | 62девять | ||||||||||||||||||||
| 58 | : | : | : | : | двоеточие | |||||||||||||||||
| 59 | ; | ; | ; | ; | точка с запятой | |||||||||||||||||
| 60 | < | < | < | < | знак меньше | |||||||||||||||||
| 61 | = | = | = | = | = | = | = | 62 | > | > | > | > | знак больше | |||||||||
| 63 | ? | ? | ? | ? | вопросительный знак | |||||||||||||||||
| 64 | @ | @ | @ | @ | коммерческий по | |||||||||||||||||
| 65 | A | A | букваA | A|||||||||||||||||||
| 66 | B | B | B | B | Заглавная латинская буква B | |||||||||||||||||
| 67 | C | C | C | C | 63латинская заглавная буква C | D | D | D | D | Заглавная латинская буква D | ||||||||||||
| 69 | E | E | E | E | Заглавная латинская буква E | F | F | F | Заглавная латинская буква F | |||||||||||||
| 71 | G | G | G | G | 910 62 Заглавная латинская буква G||||||||||||||||||
| 72 | H | H | H | H | Заглавная латинская буква H | |||||||||||||||||
| 73 | I | I | I | заглавная буква I | I | |||||||||||||||||
| 74 | J | J | J | J | Заглавная латинская буква J | |||||||||||||||||
| 75 | K | K | K | 62 K заглавная буква76 | L | L | L | L | Заглавная латинская буква L | |||||||||||||
| 77 | M | M | M | M | Заглавная латинская буква | N | N | N | N | Заглавная латинская буква N | ||||||||||||
| 79 | O | O | O | O 91 063 | Заглавная латинская буква O | |||||||||||||||||
| 80 | P | P | P | P | Заглавная латинская буква P | |||||||||||||||||
| 81 | Q | Q | Q | Q | Q 910 буква Q | |||||||||||||||||
| 82 | R | R | R | R | Заглавная латинская буква R | |||||||||||||||||
| 83 | S | S | S | S | заглавная | |||||||||||||||||
| 84 | T | T | T | T | Заглавная латинская буква T | |||||||||||||||||
| 85 | U | U | U | U | 63U | V | V | V | V | Заглавная латинская буква V | ||||||||||||
| 87 | W | W | W | 91 062 WЗаглавная латинская буква W | ||||||||||||||||||
| 88 | X | X | X | X | Заглавная латинская буква X | |||||||||||||||||
| 89 | Y | Y62 | Заглавная латинская буква Y | |||||||||||||||||||
| 90 | Z | Z | Z | Z | Заглавная латинская буква Z | |||||||||||||||||
| 91 | [ | [ | [ | [левая квадратная скобка | ] | |||||||||||||||||
| 92 | \ | \ | \ | \ | обратный солидус | |||||||||||||||||
| 93 | ] | ] | ] | ] | правый квадрат | ^ | ^ | ^ | акцент с циркумфлексом | |||||||||||||
| 95 | _ | _ | _ | _ 910 63 | нижняя линия | |||||||||||||||||
| 96 | ` | ` | ` | ` | серьезный акцент | |||||||||||||||||
| 97 | a | a | a | a | 910||||||||||||||||||
| 98 | b | b | b | b | Строчная латинская буква b | |||||||||||||||||
| 99 | c | c | c | c | 63d | d | d | d | Строчная латинская буква d | |||||||||||||
| 101 | e | e | e | e | Строчная латинская буква e | 102 | f | f | f | Строчная латинская буква f | ||||||||||||
| 103 | g | g | g | g | Строчная латинская le tter g | |||||||||||||||||
| 104 | h | h | h | h | Строчная латинская буква h | |||||||||||||||||
| 105 | i | i | маленькая букваi | i | ||||||||||||||||||
| 106 | j | j | j | j | Строчная латинская буква j | |||||||||||||||||
| 107 | k | k | k | k | 63l | l | l | l | Строчная латинская буква l | |||||||||||||
| 109 | m | m | m | m | Строчная латинская буква m | 110 | nn | n | латинская строчная буква n | |||||||||||||
| 111 | o | o | o | o | латинская строчная le tter o | |||||||||||||||||
| 112 | p | p | p | p | Строчная латинская буква p | |||||||||||||||||
| 113 | q | q | маленькаяq | q | q | q | q | |||||||||||||||
| 114 | r | r | r | r | Строчная латинская буква r | |||||||||||||||||
| 115 | s | s | s | s | 63t | t | t | t | Строчная латинская буква t | |||||||||||||
| 117 | u | u | u | u | Строчная латинская буква | 118 | vv | v | Строчная латинская буква v | |||||||||||||
| 119 | w | w | w | w | Строчная латинская буква le tter w | |||||||||||||||||
| 120 | x | x | x | x | Строчная латинская буква x | |||||||||||||||||
| 121 | y | y | маленькаяy | y | y | y | y | |||||||||||||||
| 122 | z | z | z | z | Строчная латинская буква z | |||||||||||||||||
| 123 | { | { | { | { | 63| | | | | | | | вертикальная линия | |||||||||||||
| 125 | } | } | } | } | правая фигурная скоба | |||||||||||||||||
| 126 | ~ | ~ | 62127 | DEL | ||||||||||||||||||
| 128 | € | евро знак | ||||||||||||||||||||
| 130 | ‚ | одинарная кавычка | ||||||||||||||||||||
| 131 | ƒ | 910 малая буква с крючком | „ | двойные низкие 9 кавычки | ||||||||||||||||||
| 133 | … | двойное многоточие по горизонтали | ||||||||||||||||||||
| 134 | † | 62 кинжал | ||||||||||||||||||||
| 136 | ˆ | буква-модификатор с циркумфлексом с акцентом | ||||||||||||||||||||
| 137 | ‰ | Заглавная латинская буква S с кароном | ||||||||||||||||||||
| 139 | ‹ | одинарный левый угол кавычки | ||||||||||||||||||||
| 140 | латиница c апитальная лигатура OE | |||||||||||||||||||||
| 141 | НЕ ИСПОЛЬЗУЕТСЯ | |||||||||||||||||||||
| 142 | Ž | заглавная буква | латиница 910 | НЕ ИСПОЛЬЗУЕТСЯ | ||||||||||||||||||
| 144 | НЕ ИСПОЛЬЗУЕТСЯ | |||||||||||||||||||||
| левая одинарная кавычка | ||||||||||||||||||||||
| 146 | ’ | правая одинарная кавычка | ||||||||||||||||||||
| 147 | “ | двойная двойная кавычка | ” | правый двойная кавычка | ||||||||||||||||||
| 149 | • | пуля | ||||||||||||||||||||
| 150 | - | длинное тире | ||||||||||||||||||||
| 152 | ˜ | маленькая тильда | ||||||||||||||||||||
| 153 | š | Строчная латинская буква s с кароном | ||||||||||||||||||||
| 155 | › | одинарная кавычка с прямым углом наклона | Латинская маленькая лигатура oe | |||||||||||||||||||
| 157 | НЕ ИСПОЛЬЗУЕТСЯ | |||||||||||||||||||||
| 158 | ž | Ÿ | Заглавная латинская буква Y с диэрезисом | |||||||||||||||||||
| 160 | ||||||||||||||||||||||
| перевернутый восклицательный знак | ||||||||||||||||||||||
| 162 | ¢ | ¢ | ¢ | знак центов | ||||||||||||||||||
| 163 | 62 | £ £ | ¤ | ¤ | ¤ | знак валюты | 91 058||||||||||||||||
| 165 | ¥ | ¥ | ¥ | йен знак | ||||||||||||||||||
| 166 | ¦ | ¦ | 62§ | § | знак раздела | |||||||||||||||||
| 168 | ¨ | ¨ | ¨ | диэрезис | ||||||||||||||||||
| 169 | ||||||||||||||||||||||
| 170 | ª | ª | ª | женский порядковый указатель | ||||||||||||||||||
| 171 | « | « | 58 « | двойная кавычка слева направо.¬ | ¬ | ¬ | без подписи | |||||||||||||||
| 173 | 910 62мягкий дефис | |||||||||||||||||||||
| 174 | ® | ® | ® | ¯1063 | ||||||||||||||||||
| 176 | ° | ° | ° | знак градуса | ||||||||||||||||||
| 177 | ± | ± | ± 63 | минус | ² | ² | ² | надстрочный два | ||||||||||||||
| 179 | ³ | ³ | ³ | надстрочный 3 | 62 ³острый акцент | |||||||||||||||||
| 181 | µ | µ | µ | 9 1062 микро знак|||||||||||||||||||
| 182 | ¶ | ¶ | ¶ | знак пилкроу | ||||||||||||||||||
| 183 | · | 62¸ | ¸ | ¸ | седилла | |||||||||||||||||
| 185 | ¹ | ¹ | ¹ | верхний индекс | º мужской порядковый номер | |||||||||||||||||
| 187 | » | » | » | двойная угловая кавычка, указывающая вправо | ||||||||||||||||||
| 188 | ¼ | |||||||||||||||||||||
| 189 | ½ | ½ | ½ | vulga r дробь одна половина | ||||||||||||||||||
| 190 | ¾ | ¾ | ¾ | вульгарная дробь три четверти | ||||||||||||||||||
| 191 | ¿ | 192 | À | À | À | Заглавная латинская буква A с тупым шрифтом | ||||||||||||||||
| 193 | Á | Á | Á1063 | Á | Á1063 заглавная | 910 | Â | Â | Â | Заглавная латинская буква A с циркумфлексом | ||||||||||||
| 195 | Ã | Ã | Ã | латинская заглавная буква | Ä | Ä | Ä | Заглавная латинская буква A с тремой | ||||||||||||||
| 197 | Å | Å | Å | Заглавная латинская буква A с кольцом сверху | ||||||||||||||||||
| 198 | Æ | Æ | Æ | Ç | Ç | Ç | Заглавная латинская буква C с седилем | |||||||||||||||
| 200 | È | È | È | 201 | É | É | É | Заглавная латинская буква E с острым ударением | ||||||||||||||
| 202 | Ê | Ê | Ê | Заглавная латинская буква E с циркумфлексом | Ë | Ë | Заглавная латинская буква E с тремой | |||||||||||||||
| 204 | 9 1063 | Ì | Ì | Ì | Заглавная латинская буква I с тупым ударением | |||||||||||||||||
| 205 | Í | Í | Í | Заглавная латинская буква I1062 | Î | Î | Î | Заглавная латинская буква I с циркумфлексом | ||||||||||||||
| 207 | Ï | Ï | Ï | Заглавная латинская буква I с диэрезисом 1062 | ì | ì | Заглавная латинская буква Eth | |||||||||||||||
| 209 | Ñ | Ñ | Ñ | Заглавная латинская буква N с тильдой | ||||||||||||||||||
| Ò | Латинская заглавная буква O с могилой | |||||||||||||||||||||
| 211 | Ó | Ó | Ó | Заглавная латинская буква O с острым ударением | ||||||||||||||||||
| 212 | Ô | Ô | Ô | Заглавная латинская буква O с циркумфлексом | ||||||||||||||||||
| 213 | Заглавная латинская буква O с тильдой | |||||||||||||||||||||
| 214 | Ö | Ö | Ö | Латинская заглавная буква O с диэрезисом | ||||||||||||||||||
| 215 | знак умножения | |||||||||||||||||||||
| 216 | Ø | Ø | Ø | Заглавная латинская буква O со штрихом | ||||||||||||||||||
| 217 | Ù | 62|||||||||||||||||||||
| 218 | Ú | Ú | Ú | Латинская заглавная l etter U с острым ударением | ||||||||||||||||||
| 219 | Û | Û | Û | Латинская заглавная буква U с циркумфлексом | ||||||||||||||||||
| 220 | Ü | U с диэрезисом | ||||||||||||||||||||
| 221 | Ý | Ý | Ý | Заглавная латинская буква Y с острым ударением | ||||||||||||||||||
| 222 | Þ | |||||||||||||||||||||
| 223 | ß | ß | ß | Строчная латинская буква резкая s | ||||||||||||||||||
| 224 | à | à | 62 aa | á | á | á | Строчная латинская буква а с острым ударением | |||||||||||||||
| â | â | â | Строчная латинская буква а с циркумфлексом | |||||||||||||||||||
| 227 | ã | ã | ã | ã | ã1063 | 910 910ä | ä | ä | Строчная латинская буква a с диэрезисом | |||||||||||||
| 229 | å | å | маленькая буква | æ | æ | æ | Строчная латинская буква ae | |||||||||||||||
| 231 | ç | ç | ç | ç | çedilla | çedilla | è | è | Строчная латинская буква e с тупым ударением | |||||||||||||
| 233 | é | é | é | Строчная латинская буква e с острым ударением | ||||||||||||||||||
| 234 | ê | ê | ê | Латинская строчная буква e с флексом | ë | Строчная латинская буква e с тремой | ||||||||||||||||
| 236 | ì | ì | ì | Строчная латинская буква i с надписями | ||||||||||||||||||
| 910 í | Строчная латинская буква i с острым ударением | |||||||||||||||||||||
| 238 | î | î | î | Строчная латинская буква i с циркумфлексом | ||||||||||||||||||
| 239 | 621063 | Строчная латинская буква i с тремой | ||||||||||||||||||||
| 240 | ð | ð | ð | Строчная латинская буква eth | ||||||||||||||||||
| 241 | - | - | - | Строчная латинская буква n с тильдой | ||||||||||||||||||
| 242 | 62 | o с могилой | ||||||||||||||||||||
| 243 | - | - | - | латинская строчная буква o с острым ударением | ||||||||||||||||||
| 244 | ô | с циркумфлексом | ||||||||||||||||||||
| 245 | х | х | х | латинская строчная буква o с тильдой | ||||||||||||||||||
| 246 | ö | |||||||||||||||||||||
| 247 | ÷ | ÷ | ÷ | знак деления | ||||||||||||||||||
| 248 | ø | ø | ø | Строчная латинская буква o с чертой | ||||||||||||||||||
| 249 | ù | ù | ù | grave | ú | ú | ú | Строчная латинская буква u с острым ударением | ||||||||||||||
| 251 | û | û | û | с циркумфлексом ü | ü | ü | Строчная латинская буква u с диэрезисом | |||||||||||||||
| 253 | ý | ý | ý | Строчная латинская буква y с острым знаком 63 | þ | þ | Строчная латинская шип | |||||||||||||||
| 255 | ÿ | ÿ | ÿ | Строчная латинская буква y с тремой |
Набор символов ASCII
ASCII использует значения от 0 до 31 (и 127) для управляющих символов.
ASCII использует значения от 32 до 126 для букв, цифр и символов.
ASCII не использует значения от 128 до 255.
Набор символов ANSI (Windows-1252)
ANSI идентичен ASCII для значений от 0 до 127.
ANSI имеет собственный набор символов для значений от 128 до 159.
ANSI идентичен UTF-8 для значений от 160 до 255.
Набор символов ISO-8859-1
ISO-8859-1 идентичен ASCII для значений от 0 до 127.
ISO-8859-1 не использует значения от 128 до 159.
ISO-8859-1 идентичен UTF-8 для значений от 160 до 255.
Набор символов UTF-8
UTF-8 идентичен ASCII для значений от 0 до 127.
UTF-8 не использует значения от 128 до 159.
UTF-8 идентичен ANSI и 8859-1 для значений от 160 до 255.
UTF-8 продолжает значение 256 с более чем 10 000 различных символы.
Для более детального ознакомления ознакомьтесь с нашим полным справочником по набору символов HTML.
Кодировки символов для начинающих
Во-первых, какое мне дело?
Если вы используете что-либо, кроме самого основного текста на английском языке, люди могут не прочитать созданный вами контент. если вы не укажете, какую кодировку символов вы использовали.
Например, вы можете сделать так, чтобы текст выглядел так:
, но на самом деле он может отображаться так:
Отсутствие информации о кодировке символов не только ухудшает читаемость отображаемого текста, но также может означать, что ваши данные не могут быть найдены поисковой системой или надежно обрабатывается машинами другими способами.
Так что за кодировка символов?
Слова и предложения в тексте состоят из символов . Примеры символов включают латинскую букву á, китайскую идеограмму 請 или символ деванагари ह.
Возможно, вы не сможете увидеть некоторые символы на этой странице, потому что у вас нет необходимых шрифтов. Если вы нажмете на то место, где ожидали увидеть персонажа, вы перейдете к графической версии. Эта страница закодирована в UTF-8.
Персонажи, необходимые для определенной цели, сгруппированы в набор символов (также называемый репертуаром ). (Для однозначного обозначения символов каждый символ связан с числом, называемым кодовой точкой .)
Символы хранятся в компьютере как один или несколько байтов .
В принципе, вы можете визуализировать это, предположив, что все символы хранятся в компьютерах с использованием специального кода, как шифры, используемые в шпионаже.Кодировка предоставляет ключ для разблокировки (т. Е. Взлома) кода. Это набор соответствий между байтами в компьютере и символами в наборе символов. Без ключа данные выглядят как мусор.
Вводящий в заблуждение термин кодировка часто используется для обозначения того, что на самом деле является кодировкой символов. Вам следует помните об этом использовании, но всегда старайтесь использовать термины кодировки символов.
Итак, когда вы вводите текст с клавиатуры или каким-либо другим способом, кодировка символов сопоставляет выбранные вами символы с конкретными байтами в памяти компьютера, а затем для отображения текста считывает байты обратно в символы.
К сожалению, существует множество различных наборов символов и кодировок символов, т.е. множество разных способов сопоставления байтов, кодовые точки и символы. В разделе «Дополнительная информация» для тех, кому интересно, чуть подробнее.
Однако в большинстве случаев вам не нужно знать подробности. Вам просто нужно быть уверенным, что вы прислушиваетесь к советам в раздел Как это влияет на меня? ниже.
Как к этому подходят шрифты?
Шрифт - это набор определений глифов, т.е.определения форм, используемых для отображения символов.
Как только ваш браузер или приложение определит, с какими символами имеет дело, оно будет искать в шрифте глифы, которые можно использовать для отображения. или распечатайте эти символы. (Конечно, если информация о кодировке была неправильной, она будет искать глифы для неправильных символов.)
Данный шрифт обычно покрывает один набор символов или, в случае большого набора символов, например Unicode, только подмножество всех персонажей в наборе.Если в вашем шрифте нет глифа для определенного символа, некоторые браузеры или программные приложения будут искать отсутствующие глифы в других шрифты в вашей системе (это будет означать, что глиф будет отличаться от окружающего текста, как записка с требованием выкупа). В противном случае вы обычно вместо этого увидите квадратную рамку, вопросительный знак или какой-либо другой символ. Например:
Как это повлияет на меня?
Как автор или разработчик контента, в настоящее время вы всегда должны выбирать UTF-8 кодировка символов для вашего контента или данных.Эта кодировка Unicode - хороший выбор, поскольку вы можете использовать односимвольную кодировку для обработки любого символа, который вам может понадобиться. Это значительно упрощает работу. Использование Unicode во всей вашей системе также избавляет от необходимости отслеживать и конвертировать между различными кодировками символов.
Авторы контента должны выяснить, как объявить персонажа кодировка, используемая для формата документа, с которым они работают.
Обратите внимание, что просто объявление другой кодировки на вашей странице не изменит байты; вам нужно сохранить и текста в этой кодировке.
Как автор контента, вам необходимо проверить, в какой кодировке ваш редактор или скрипты сохраняют текст и как сохранять текст в UTF-8. (В наши дни это обычно используется по умолчанию.) Вам также может потребоваться проверить, что ваш сервер обслуживает документы с правильным HTTP декларации.
Разработчикам необходимо убедиться, что различные части системы могут взаимодействовать друг с другом, понимать, какие кодировки символов используются и поддерживают все необходимые кодировки и символы.(В идеале вы должны использовать UTF-8 повсюду и избавиться от этой проблемы.)
По ссылкам ниже можно найти дополнительную информацию по этим темам.
Этот раздел предоставляет небольшую дополнительную информацию о сопоставлении байтов, кодовых точек и символов для тех, кому это интересно. Не стесняйтесь просто перейти к разделу Дополнительная литература.
Обратите внимание, что номера кодовых точек обычно выражаются в шестнадцатеричной системе счисления, т.е. основание 16. Например, 233 в шестнадцатеричной форме - это E9.Значения кодовой точки Unicode обычно записываются в форме U + 00E9.
В наборе кодированных символов под названием ISO 8859-1 (также известном как Latin1) значение десятичной кодовой точки для буквы é равно 233. Однако в ISO 8859-5, та же кодовая точка представляет кириллический символ щ.
Эти наборы символов содержат менее 256 символов и напрямую сопоставляют кодовые точки с байтовыми значениями, поэтому кодовая точка со значением 233 представлена одним байтом со значением 233.Обратите внимание, что только контекст определяет, представляет ли этот байт либо é, либо щ.
Есть и другие способы работы с символами из ряда сценариев. Например, с набором символов Unicode вы можете представить оба символа в одном наборе. Фактически, Unicode содержит в одном наборе, вероятно, все символы, которые вам когда-либо понадобятся. Хотя буква é по-прежнему представлена значением кодовой точки 233, кириллический символ щ теперь имеет значение кодовой точки 1097.
С другой стороны, 1097 - слишком большое число, чтобы его можно было представить одним байт*. Итак, если вы используете кодировку символов для текста Unicode под названием UTF-8, щ будет представлен двумя байтами. Тем не менее значение кодовой точки не просто выводится из значения двух байтов, соединенных вместе - требуется более сложное декодирование.
Другой Unicode символы отображаются в один, три или четыре байта в кодировке UTF-8.
Кроме того, обратите внимание, что буква é также представлена двумя байтами в UTF-8, а не одним байтом, используемым в ISO 8859-1. (Только символы ASCII кодируются одним байтом в UTF-8.)
UTF-8 - это наиболее широко используемый способ представления текста Unicode на веб-страницах, и вы всегда должны использовать UTF-8 при создании веб-страниц и баз данных. Но, в принципе, UTF-8 - лишь один из возможных способов кодирования. Символы Юникода. Другими словами, одна кодовая точка в наборе символов Unicode может фактически отображаться в разные последовательности байтов, в зависимости от какая кодировка использовалась для документа.Кодовые точки Unicode могут быть сопоставлены с байтами с использованием любой из кодировок, называемых UTF-8, UTF-16 или UTF-32. Символ деванагари क с кодовой точкой 2325 (что составляет 915 в шестнадцатеричной системе счисления) будет представлен двумя байтов при использовании кодировки UTF-16 (09 15), трех байтов с UTF-8 (E0 A4 95) или четырех байтов с UTF-32 (00 00 09 15).
Могут быть и другие сложности помимо описанных в этом разделе (например, порядок байтов и escape-последовательности), но детали описанное здесь показывает, почему важно, чтобы приложение, с которым вы работаете, знало, какая кодировка символов подходит для ваших данных, и знает, как обрабатывать эту кодировку.
| НУЛЬ (U + 0000) | 00 | |
| НАЧАЛО ЗАГОЛОВКИ (U + 0001) | 01 | |
| НАЧАЛО ТЕКСТА (U + 0002) | 02 | |
| КОНЕЦ ТЕКСТА (U + 0003) | 03 | |
| КОНЕЦ ПЕРЕДАЧИ (U + 0004) | 04 | |
| ЗАПРОС (U + 0005) | 05 | |
| ПОДТВЕРЖДЕНИЕ (U + 0006) | 06 | |
| BELL (U + 0007) | 07 | |
| BACKSPACE (U + 0008) | 08 | |
| ТАБЛИЦА ХАРАКТЕРОВ (U + 0009) | 09 | |
| ЛИНИЯ ПОДАЧИ (LF) (U + 000A) | 0a | |
| ТАБЛИЦА СТРОК (U + 000B) | 0b | |
| ПОДАЧА ФОРМЫ (FF) (U + 000C) | 0c | |
| ВОЗВРАТ ТРАНСПОРТА (CR) (U + 000D) | 0d | |
| ВЫДЕЛЕНИЕ (U + 000E) | 0e | |
| СМЕНА ВХОДА (U + 000F) | 0f | |
| ОТКЛЮЧЕНИЕ ССЫЛКИ ДАННЫХ (U + 0010) | 10 | |
| DEVICE CONTROL ONE (U + 0011) | 11 | |
| УПРАВЛЕНИЕ УСТРОЙСТВОМ ДВА (U + 0012) | 12 | |
| УПРАВЛЕНИЕ УСТРОЙСТВОМ ТРИ (U + 0013) | 13 | |
| УПРАВЛЕНИЕ УСТРОЙСТВОМ ЧЕТЫРЕ (U + 0014) | 14 | |
| ОТРИЦАТЕЛЬНОЕ ПОДТВЕРЖДЕНИЕ (U + 0015) | 15 | |
| СИНХРОННЫЙ ХОЛОСТОЙ ХОД (U + 0016) | 16 | |
| КОНЕЦ БЛОКА ТРАНСМИССИИ (U + 0017) | 17 | |
| ОТМЕНА (U + 0018) | 18 | |
| КОНЕЦ СРЕДЫ (U + 0019) | 19 | |
| ЗАМЕСТИТЕЛЬ (U + 001A) | 1a | |
| ESCAPE (U + 001B) | 1б | |
| ИНФОРМАЦИОННЫЙ РАЗДЕЛИТЕЛЬ ЧЕТЫРЕ (U + 001C) | 1c | |
| ИНФОРМАЦИОННЫЙ РАЗДЕЛИТЕЛЬ ТРЕТИЙ (U + 001D) | 1д | |
| ДВОЙНОЙ РАЗДЕЛИТЕЛЬ ИНФОРМАЦИИ (U + 001E) | 1e | |
| ИНФОРМАЦИОННЫЙ СЕПАРАТОР ОДИН (U + 001F) | 1ф | |
| ПРОСТРАНСТВО (U + 0020) | 20 | |
| ! | Восклицательный знак (U + 0021) | 21 |
| " | ЦЕНА (U + 0022) | 22 |
| # | НОМЕРНЫЙ ЗНАК (U + 0023) | 23 |
| $ | ДОЛЛАРНЫЙ ЗНАК (U + 0024) | 24 |
| % | ЗНАК ПРОЦЕНТА (U + 0025) | 25 |
| и | АМПЕРСАНД (U + 0026) | 26 |
| ' | АПОСТРОФ (U + 0027) | 27 |
| ( | ЛЕВЫЙ ПАРЕНТЕЗ (U + 0028) | 28 |
| ) | ПРАВЫЙ ПАРЕНТЕЗ (U + 0029) | 29 |
| * | АСТЕРИСК (U + 002A) | 2a |
| + | ЗНАК ПЛЮС (U + 002B) | 2b |
| , | ЗАПЯТАЯ (U + 002C) | 2c |
| - | ДЕФЕН-МИНУС (U + 002D) | 2д |
| . | ПОЛНЫЙ ОСТАНОВ (U + 002E) | 2e |
| / | СОЛИДУС (U + 002F) | 2f |
| 0 | ЦИФРОВОЙ НУЛЬ (U + 0030) | 30 |
| 1 | DIGIT ONE (U + 0031) | 31 |
| 2 | ЦИФРА ДВА (U + 0032) | 32 |
| 3 | ТРИ ЦИФРА (U + 0033) | 33 |
| 4 | ЦИФРА ЧЕТЫРЕ (U + 0034) | 34 |
| 5 | ЦИФРА ПЯТЬ (U + 0035) | 35 |
| 6 | ШЕСТЬ ЦИФРОВ (U + 0036) | 36 |
| 7 | ЦИФРА СЕМЬ (U + 0037) | 37 |
| 8 | ВОСЬМАЯ ЦИФРА (U + 0038) | 38 |
| 9 | ДЕВЯТЬ ЦИФРОВ (U + 0039) | 39 |
| : | КОЛОН (U + 003A) | 3a |
| ; | СЕМИКОЛОН (U + 003B) | 3б |
| < | МЕНЬШЕ ЗНАКА (U + 003C) | 3c |
| = | ЗНАК РАВНО (U + 003D) | 3д |
| > | ЗНАК БОЛЬШЕ ЧЕМ (U + 003E) | 3e |
| ? | ВОПРОСНЫЙ ЗНАК (U + 003F) | 3f |
| @ | КОММЕРЧЕСКИЙ AT (U + 0040) | 40 |
| А | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА A (U + 0041) | 41 |
| Б | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА B (U + 0042) | 42 |
| С | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА C (U + 0043) | 43 |
| D | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА D (U + 0044) | 44 |
| E | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E (U + 0045) | 45 |
| ф | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА F (U + 0046) | 46 |
| G | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА G (U + 0047) | 47 |
| H | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА H (U + 0048) | 48 |
| I | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА I (U + 0049) | 49 |
| Дж | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА J (U + 004A) | 4a |
| К | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА K (U + 004B) | 4б |
| л | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА L (U + 004C) | 4c |
| М | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА M (U + 004D) | 4д |
| N | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА N (U + 004E) | 4e |
| O | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O (U + 004F) | 4f |
| п | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА P (U + 0050) | 50 |
| Q | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Q (U + 0051) | 51 |
| р | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА R (U + 0052) | 52 |
| S | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА S (U + 0053) | 53 |
| т | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА T (U + 0054) | 54 |
| U | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U (U + 0055) | 55 |
| В | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА V (U + 0056) | 56 |
| Вт | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА W (U + 0057) | 57 |
| X | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА X (U + 0058) | 58 |
| Y | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Y (U + 0059) | 59 |
| Z | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Z (U + 005A) | 5a |
| [ | КРОНШТЕЙН КВАДРАТНЫЙ ЛЕВЫЙ (U + 005B) | 5б |
| \ | REVERSE SOLIDUS (U + 005C) | 5c |
| ] | КРОНШТЕЙН ПРАВЫЙ КВАДРАТНЫЙ (U + 005D) | 5д |
| ^ | CIRCUMFLEX ACCENT (U + 005E) | 5e |
| _ | НИЗКАЯ ЛИНИЯ (U + 005F) | 5f |
| ` | МОЩНЫЙ АКЦЕНТ (U + 0060) | 60 |
| а | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A (U + 0061) | 61 |
| б | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА B (U + 0062) | 62 |
| с | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА C (U + 0063) | 63 |
| д | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА D (U + 0064) | 64 |
| и | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E (U + 0065) | 65 |
| f | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА F (U + 0066) | 66 |
| г | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА G (U + 0067) | 67 |
| ч | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА H (U + 0068) | 68 |
| i | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I (U + 0069) | 69 |
| дж | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА J (U + 006A) | 6a |
| к | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА K (U + 006B) | 6б |
| л | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА L (U + 006C) | 6c |
| м | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА M (U + 006D) | 6д |
| n | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА N (U + 006E) | 6e |
| или | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O (U + 006F) | 6ф |
| п. | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА P (U + 0070) | 70 |
| q | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Q (U + 0071) | 71 |
| р | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА R (U + 0072) | 72 |
| с | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА S (U + 0073) | 73 |
| т | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА T (U + 0074) | 74 |
| u | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U (U + 0075) | 75 |
| в | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА V (U + 0076) | 76 |
| w | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА W (U + 0077) | 77 |
| х | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА X (U + 0078) | 78 |
| y | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y (U + 0079) | 79 |
| z | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Z (U + 007A) | 7a |
| { | КРОНШТЕЙН ЛЕВЫЙ ИЗОЛИРУЮЩИЙ (U + 007B) | 7b |
| | | ВЕРТИКАЛЬНАЯ ЛИНИЯ (U + 007C) | 7c |
| } | КРОНШТЕЙН ПРАВИЛЬНЫЙ (U + 007D) | 7д |
| ~ | ТИЛЬДА (U + 007E) | 7e |
| УДАЛИТЬ (U + 007F) | 7f | |
| € | <контроль> (U + 0080) | c280 |
| <контроль> (U + 0081) | c281 | |
| , | ПЕРЕРЫВ РАЗРЕШЕН ЗДЕСЬ (U + 0082) | c282 |
| ƒ | ЗДЕСЬ БЕЗ ПЕРЕРЫВА (U + 0083) | c283 |
| „ | <контроль> (U + 0084) | c284 |
| … | СЛЕДУЮЩАЯ СТРОКА (NEL) (U + 0085) | c285 |
| † | НАЧАЛО ВЫБРАННОЙ ПЛОЩАДИ (U + 0086) | c286 |
| ‡ | КОНЕЦ ВЫБРАННОЙ ОБЛАСТИ (U + 0087) | c287 |
| ˆ | НАБОР ТАБЛИЦЫ ПЕРСОНАЖЕЙ (U + 0088) | c288 |
| ‰ | ТАБЛИЦА ХАРАКТЕРОВ С ОБОСНОВАНИЕМ (U + 0089) | c289 |
| Š | НАБОР ТАБЛИЦ ЛИНИИ (U + 008A) | c28a |
| ‹ | ЧАСТИЧНАЯ ЛИНИЯ ВПЕРЕД (U + 008B) | c28b |
| Œ | ЧАСТИЧНАЯ ЛИНИЯ НАЗАД (U + 008C) | c28c |
| ОБРАТНАЯ ЛИНИЯ ПОДАЧИ (U + 008D) | c28d | |
| Ž | ОДИНАРНАЯ СМЕНА ДВУХ (U + 008E) | c28e |
| ОДНОСМЕНА ТРИ (U + 008F) | c28f | |
| СТРОКА УПРАВЛЕНИЯ УСТРОЙСТВОМ (U + 0090) | c290 | |
| ‘ | ЧАСТНОЕ ИСПОЛЬЗОВАНИЕ ОДИН (U + 0091) | c291 |
| ’ | ЧАСТНОЕ ИСПОЛЬЗОВАНИЕ ДВА (U + 0092) | c292 |
| “ | УСТАНОВИТЬ СОСТОЯНИЕ ПЕРЕДАЧИ (U + 0093) | c293 |
| ” | ОТМЕНА ХАРАКТЕРА (U + 0094) | c294 |
| • | ОЖИДАНИЕ СООБЩЕНИЯ (U + 0095) | c295 |
| - | НАЧАЛО ОХРАНЫ (U + 0096) | c296 |
| - | КОНЕЦ ОХРАНЫ (U + 0097) | c297 |
| ~ | НАЧАЛО СТРОКИ (U + 0098) | c298 |
| ™ | <контроль> (U + 0099) | c299 |
| š | ИНТРОДУКТОР ОДИНОЧНОГО ПЕРСОНАЖА (U + 009A) | c29a |
| › | ИНСТРУМЕНТ ПОСЛЕДОВАТЕЛЬНОСТИ УПРАВЛЕНИЯ (U + 009B) | c29b |
| – | СТРОЧНОЙ КОНДИЦИОНЕР (U + 009C) | c29c |
| КОМАНДА ОПЕРАЦИОННОЙ СИСТЕМЫ (U + 009D) | c29d | |
| ž | СООБЩЕНИЕ О КОНФИДЕНЦИАЛЬНОСТИ (U + 009E) | c29e |
| Ÿ | ПРИЛОЖЕНИЕ КОМАНДА ПРОГРАММЫ (U + 009F) | c29f |
| ПРОСТРАНСТВО БЕЗ РАЗРЫВА (U + 00A0) | c2a0 | |
| ¡ | ПЕРЕВЕРНУТЫЙ восклицательный знак (U + 00A1) | c2a1 |
| ¢ | ЦЕНТРАЛЬНЫЙ ЗНАК (U + 00A2) | c2a2 |
| £ | ЗНАК ФУНТА (U + 00A3) | c2a3 |
| ¤ | ЗНАК ВАЛЮТЫ (U + 00A4) | c2a4 |
| ¥ | ЗНАК ЙЕН (U + 00A5) | c2a5 |
| ¦ | СЛОМАННЫЙ БАР (U + 00A6) | c2a6 |
| § | СЕКЦИОННЫЙ ЗНАК (U + 00A7) | c2a7 |
| ¨ | ДИАРЕЗИС (U + 00A8) | c2a8 |
| © | ЗНАК АВТОРСКОГО ПРАВА (U + 00A9) | c2a9 |
| ª | ЖЕНСКИЙ ОБЫЧНЫЙ ИНДИКАТОР (U + 00AA) | c2aa |
| « | ЛЕВЫЙ ДВОЙНОЙ УГОЛ ЦИТАТЫ (U + 00AB) | c2ab |
| ¬ | НЕ ПОДПИСАТЬ (U + 00AC) | c2ac |
| МЯГКИЙ ДЕФЕН (U + 00AD) | c2ad | |
| ® | ЗАРЕГИСТРИРОВАННЫЙ ЗНАК (U + 00AE) | c2ae |
| ¯ | МАКРОН (U + 00AF) | c2af |
| ° | ЗНАК СТЕПЕНИ (U + 00B0) | c2b0 |
| ± | ЗНАК ПЛЮС-МИНУС (U + 00B1) | c2b1 |
| ² | ЗАПИСЬ ВТОРОЙ (U + 00B2) | c2b2 |
| ³ | ЗАПИСЬ ТРИ (U + 00B3) | c2b3 |
| ´ | ОСТРЫЙ АКЦЕНТ (U + 00B4) | c2b4 |
| мкм | МИКРОЗНАК (U + 00B5) | c2b5 |
| ¶ | ЗНАК ПИЛКРОУ (U + 00B6) | c2b6 |
| · | СРЕДНЯЯ ТОЧКА (U + 00B7) | c2b7 |
| ¸ | CEDILLA (U + 00B8) | c2b8 |
| ¹ | SUPERSCRIPT ONE (U + 00B9) | c2b9 |
| º | ИНДИКАТОР ОБОРУДОВАНИЯ МУЖЧИНЫ (U + 00BA) | c2ba |
| » | ДВОЙНОЙ УГЛОВОЙ ЦИТАТНЫЙ ЗНАК, УКАЗАННЫЙ ВПРАВО (U + 00BB) | c2bb |
| ¼ | VULGAR FRACTION ONE QUARTER (U + 00BC) | c2bc |
| ½ | VULGAR FRACTION ONE HALF (U + 00BD) | c2bd |
| ¾ | ВОЛГАРНАЯ ФРАКЦИЯ ТРИ ЧЕТВЕРТИ (U + 00BE) | c2be |
| ¿ | ПЕРЕВЕРНУТЫЙ ВОПРОСНЫЙ ЗНАК (U + 00BF) | c2bf |
| À | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА А С ТЯЖЕЛЫМ (U + 00C0) | c380 |
| Á | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА А С ОСТРЫМ (U + 00C1) | c381 |
| Â | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА А С ЦИРКУМФЛЕКСОМ (U + 00C2) | c382 |
| Ã | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА А С ТИЛЬДОЙ (U + 00C3) | c383 |
| Ä | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА А С ДИАРЕЗОМ (U + 00C4) | c384 |
| Å | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА А С КОЛЬЦОМ ВЫШЕ (U + 00C5) | с385 |
| Æ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА AE (U + 00C6) | с386 |
| Ç | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА C С СЕДИЛЬЕЙ (U + 00C7) | с387 |
| È | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E С ТЯЖЕЛЫМ (U + 00C8) | c388 |
| É | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E С ОСТРЫМ (U + 00C9) | c389 |
| Ê | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E с CIRCUMFLEX (U + 00CA) | c38a |
| Ë | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E С ДИАРЕЗОМ (U + 00CB) | c38b |
| Ì | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА I С ТЯЖЕЛЫМ (U + 00CC) | c38c |
| Í | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА I С ОСТРЫМ (U + 00CD) | c38d |
| Î | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА I С ЦИРКУМФЛЕКСОМ (U + 00CE) | c38e |
| Ï | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА I С ДИАРЕЗОМ (U + 00CF) | c38f |
| ì | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА ETH (U + 00D0) | c390 |
| Ñ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА N С ТИЛЬДОЙ (U + 00D1) | c391 |
| Ò | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С ТЯЖЕЛЫМ (U + 00D2) | c392 |
| Ó | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С ОСТРЫМ (U + 00D3) | c393 |
| Ô | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С CIRCUMFLEX (U + 00D4) | c394 |
| Õ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С ТИЛЬДОЙ (U + 00D5) | c395 |
| Ö | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С ДИАРЕЗОМ (U + 00D6) | c396 |
| × | ЗНАК УМНОЖЕНИЯ (U + 00D7) | c397 |
| Ø | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С ИНСУЛЬТОМ (U + 00D8) | c398 |
| Ù | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U С ТЯЖЕЛЫМ (U + 00D9) | c399 |
| Ú | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U С ОСТРЫМ (U + 00DA) | c39a |
| Û | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U С ЦИРКУМФЛЕКСОМ (U + 00DB) | c39b |
| Ü | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U С ДИАРЕЗОМ (U + 00DC) | c39c |
| Ý | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Y С ОСТРЫМ (U + 00DD) | c39d |
| Þ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА ШИП (U + 00DE) | c39e |
| ß | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА SHARP S (U + 00DF) | c39f |
| до | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА А С ТЯЖЕЛЫМ (U + 00E0) | c3a0 |
| á | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A с ОСТРЫМ (U + 00E1) | c3a1 |
| – | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A с CIRCUMFLEX (U + 00E2) | c3a2 |
| ã | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A с тильдой (U + 00E3) | c3a3 |
| ä | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА А С ДИАРЕЗИСОМ (U + 00E4) | c3a4 |
| å | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A с КОЛЬЦОМ ВЫШЕ (U + 00E5) | c3a5 |
| æ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА AE (U + 00E6) | c3a6 |
| ç | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА C С СЕДИЛЬЕЙ (U + 00E7) | c3a7 |
| и | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E С ТЯЖЕЛЫМ (U + 00E8) | c3a8 |
| é | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E с ОСТРЫМ (U + 00E9) | c3a9 |
| ê | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E с CIRCUMFLEX (U + 00EA) | c3aa |
| ë | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E с ДИАРЕЗИСОМ (U + 00EB) | c3ab |
| мм | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С ТЯЖЕЛЫМ (U + 00EC) | c3ac |
| до | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С ОСТРЫМ (U + 00ED) | c3ad |
| – | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С CIRCUMFLEX (U + 00EE) | c3ae |
| • | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С ДИАРЕЗИСОМ (U + 00EF) | c3af |
| ð | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА ETH (U + 00F0) | c3b0 |
| – | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА N С ТИЛЬДОЙ (U + 00F1) | c3b1 |
| ò | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ТЯЖЕЛЫМ (U + 00F2) | c3b2 |
| - | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O с ОСТРЫМ (U + 00F3) | c3b3 |
| ô | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O с CIRCUMFLEX (U + 00F4) | c3b4 |
| х | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O с тильдой (U + 00F5) | c3b5 |
| ö | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ДИАРЕЗИСОМ (U + 00F6) | c3b6 |
| ÷ | ЗНАК РАЗДЕЛА (U + 00F7) | c3b7 |
| ø | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С ИНСУЛЬТОМ (U + 00F8) | c3b8 |
| ù | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С ТЯЖЕЛЫМ (U + 00F9) | c3b9 |
| ú | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U с ОСТРЫМ (U + 00FA) | c3ba |
| û | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U с CIRCUMFLEX (U + 00FB) | c3bb |
| ü | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С ДИАРЕЗИСОМ (U + 00FC) | c3bc |
| ý | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y с ОСТРЫМ (U + 00FD) | c3bd |
| þ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА ШИП (U + 00FE) | c3be |
| ÿ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y С ДИАРЕЗИСОМ (U + 00FF) | c3bf |
| Ā | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА А С МАКРОНОМ (U + 0100) | c480 |
| ā | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С МАКРОНОМ (U + 0101) | c481 |
| Ă | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА А С BREVE (U + 0102) | c482 |
| до | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A С BREVE (U + 0103) | c483 |
| Ą | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА A с ОГОНЕК (U + 0104) | c484 |
| ą | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА А с ОГОНЕК (U + 0105) | c485 |
| Ć | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА C С ОСТРЫМ (U + 0106) | с486 |
| ć | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА C с ОСТРЫМ (U + 0107) | c487 |
| Ĉ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА C с CIRCUMFLEX (U + 0108) | c488 |
| ĉ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА C с CIRCUMFLEX (U + 0109) | с489 |
| Ċ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА C С ТОЧКОЙ ВЫШЕ (U + 010A) | c48a |
| ċ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА C С ТОЧКОЙ ВЫШЕ (U + 010B) | c48b |
| Č | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА C С КАРОН (U + 010C) | c48c |
| č | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА C с КАРОН (U + 010D) | c48d |
| Ď | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА D С КАРОН (U + 010E) | c48e |
| ď | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА D С КАРОН (U + 010F) | c48f |
| Đ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА D С ИНСУЛЬТОМ (U + 0110) | c490 |
| đ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА D С ИНСУЛЬТОМ (U + 0111) | c491 |
| Ē | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E С МАКРОНОМ (U + 0112) | c492 |
| ē | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E С МАКРОНОМ (U + 0113) | c493 |
| Ĕ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E С BREVE (U + 0114) | c494 |
| ĕ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E С BREVE (U + 0115) | c495 |
| Ė | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E С ТОЧКОЙ ВЫШЕ (U + 0116) | c496 |
| e | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E с точкой вверху (U + 0117) | c497 |
| Ę | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E с ОГОНЕК (U + 0118) | c498 |
| ę | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E с ОГОНЕК (U + 0119) | c499 |
| Ě | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E С КАРОН (U + 011A) | c49a |
| ě | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E с КАРОН (U + 011B) | c49b |
| Ĝ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА G С CIRCUMFLEX (U + 011C) | c49c |
| ĝ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА G С CIRCUMFLEX (U + 011D) | c49d |
| Ğ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА G С BREVE (U + 011E) | c49e |
| ğ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА G С BREVE (U + 011F) | c49f |
| Ġ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА G С ТОЧКОЙ ВЫШЕ (U + 0120) | c4a0 |
| ġ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА G С ТОЧКОЙ ВЫШЕ (U + 0121) | c4a1 |
| Ģ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА G С СЕДИЛЬЕЙ (U + 0122) | c4a2 |
| ģ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА G С СЕДИЛЬЕЙ (U + 0123) | c4a3 |
| Ĥ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА H С CIRCUMFLEX (U + 0124) | c4a4 |
| ĥ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА H С CIRCUMFLEX (U + 0125) | c4a5 |
| Ħ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА H С ИНСУЛЬТОМ (U + 0126) | c4a6 |
| ħ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА H С ИНСУЛЬТОМ (U + 0127) | c4a7 |
| Ĩ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА I С ТИЛЬДОЙ (U + 0128) | c4a8 |
| ĩ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С ТИЛЬДОЙ (U + 0129) | c4a9 |
| Ī | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА I С МАКРОНОМ (U + 012A) | c4aa |
| ī | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С МАКРОНОМ (U + 012B) | c4ab |
| Ĭ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА I С БРЕВОМ (U + 012C) | c4ac |
| ĭ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I С BREVE (U + 012D) | c4ad |
| Į | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА I С ОГОНЕК (U + 012E) | c4ae |
| į | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I с ОГОНЕК (U + 012F) | c4af |
| из | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА I С ТОЧКОЙ ВЫШЕ (U + 0130) | c4b0 |
| № | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА БЕЗ ТОЧЕК I (U + 0131) | c4b1 |
| IJ | ЛАТИНСКАЯ ЗАГЛАВНАЯ ПИСЬМА IJ (U + 0132) | c4b2 |
| ij | СТРОЧНАЯ ЛАТИНСКАЯ ЛИГАТУРА IJ (U + 0133) | c4b3 |
| Ĵ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА J С ЦИРКУМФЛЕКСОМ (U + 0134) | c4b4 |
| ĵ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА J с CIRCUMFLEX (U + 0135) | c4b5 |
| Ķ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА K С СЕДИЛЬЕЙ (U + 0136) | c4b6 |
| ķ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА K с СЕДИЛЬЕЙ (U + 0137) | c4b7 |
| ĸ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА KRA (U + 0138) | c4b8 |
| Ĺ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА L С ОСТРЫМ (U + 0139) | c4b9 |
| ĺ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА L С ОСТРЫМ (U + 013A) | c4ba |
| Ļ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА L С СЕДИЛЬЕЙ (U + 013B) | c4bb |
| ļ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА L С СЕДИЛЬЕЙ (U + 013C) | c4bc |
| Ľ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА L С КАРОН (U + 013D) | c4bd |
| ľ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА L С КАРОН (U + 013E) | c4be |
| Ŀ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА L СО СРЕДНЕЙ ТОЧКОЙ (U + 013F) | c4bf |
| ŀ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА L С СРЕДНЕЙ ТОЧКОЙ (U + 0140) | c580 |
| Ł | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА L С ИНСУЛЬТОМ (U + 0141) | c581 |
| ł | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА L С ИНСУЛЬТОМ (U + 0142) | c582 |
| Ń | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА N С ОСТРЫМ (U + 0143) | c583 |
| ń | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА N С ОСТРЫМ (U + 0144) | c584 |
| Ņ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА N С СЕДИЛЬЕЙ (U + 0145) | c585 |
| ņ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА N С СЕДИЛЬЕЙ (U + 0146) | c586 |
| Ň | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА N С КАРОН (U + 0147) | с587 |
| ň | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА N С КАРОН (U + 0148) | c588 |
| ʼn | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА N, ПРЕДШЕСТВУЮЩАЯ АПОСТРОФУ (U + 0149) | с589 |
| Ŋ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА ENG (U + 014A) | c58a |
| ŋ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА ENG (U + 014B) | c58b |
| Ō | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С МАКРОНОМ (U + 014C) | c58c |
| ō | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С МАКРОНОМ (U + 014D) | c58d |
| Ŏ | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА O С BREVE (U + 014E) | c58e |
| ŏ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O С BREVE (U + 014F) | c58f |
| Ő | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O С ДВУСТОРОННИМ ОСТРЫМ (U + 0150) | c590 |
| ő | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O с ДВОЙНОЙ ОСТРОЙ (U + 0151) | c591 |
| Œ | ЛАТИНСКАЯ ЗАГЛАВНАЯ ЛИГАТУРА OE (U + 0152) | c592 |
| – | ЛАТИНСКАЯ СТРОЧНАЯ ЛИГАТУРА OE (U + 0153) | c593 |
| Ŕ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА R С ОСТРЫМ (U + 0154) | c594 |
| ŕ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА R С ОСТРЫМ (U + 0155) | c595 |
| Ŗ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА R С СЕДИЛЬЕЙ (U + 0156) | c596 |
| ŗ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА R С СЕДИЛЬЕЙ (U + 0157) | c597 |
| Ř | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА R С КАРОН (U + 0158) | c598 |
| ø | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА R С КАРОН (U + 0159) | c599 |
| Ś | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА S С ОСТРЫМ (U + 015A) | c59a |
| ś | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА S С ОСТРЫМ (U + 015B) | c59b |
| Ŝ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА S С ЦИРКУМФЛЕКСОМ (U + 015C) | c59c |
| ŝ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА S С ЦИРКУМФЛЕКСОМ (U + 015D) | c59d |
| Ş | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА S С СЕДИЛЬЕЙ (U + 015E) | c59e |
| ş | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА S С СЕДИЛЬЕЙ (U + 015F) | c59f |
| Š | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА S С КАРОН (U + 0160) | c5a0 |
| š | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА S С КАРОН (U + 0161) | c5a1 |
| Ţ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА T С СЕДИЛЬЕЙ (U + 0162) | c5a2 |
| ţ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА T С СЕДИЛЬЕЙ (U + 0163) | c5a3 |
| Ť | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА T С КАРОН (U + 0164) | c5a4 |
| ť | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА T С КАРОН (U + 0165) | c5a5 |
| Ŧ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА T С ИНСУЛЬТОМ (U + 0166) | c5a6 |
| ŧ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА T С ИНСУЛЬТОМ (U + 0167) | c5a7 |
| Ũ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U С ТИЛЬДОЙ (U + 0168) | c5a8 |
| ũ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С ТИЛЬДОЙ (U + 0169) | c5a9 |
| Ū | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U С МАКРОНОМ (U + 016A) | c5aa |
| ū | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С МАКРОНОМ (U + 016B) | c5ab |
| Ŭ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U С BREVE (U + 016C) | c5ac |
| ŭ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U С BREVE (U + 016D) | c5ad |
| Ů | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U с КОЛЬЦОМ ВЫШЕ (U + 016E) | c5ae |
| ů | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U с КОЛЬЦОМ ВЫШЕ (U + 016F) | c5af |
| Ű | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U С ДВУСТОРОННИМ ОСТРЫМ (U + 0170) | c5b0 |
| ű | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U с ДВОЙНОЙ ОСТРОЙ (U + 0171) | c5b1 |
| Ų | ЗАГЛАВНАЯ БУКВА U с ОГОНЕК (U + 0172) | c5b2 |
| ų | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U с ОГОНЕК (U + 0173) | c5b3 |
| Ŵ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА W С ЦИРКУМФЛЕКСОМ (U + 0174) | c5b4 |
| ŵ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА W С CIRCUMFLEX (U + 0175) | c5b5 |
| Ŷ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Y С ЦИРКУМФЛЕКСОМ (U + 0176) | c5b6 |
| ŷ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y С CIRCUMFLEX (U + 0177) | c5b7 |
| Ÿ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Y С ДИАРЕЗОМ (U + 0178) | c5b8 |
| Ź | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Z С ОСТРЫМ (U + 0179) | c5b9 |
| ź | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Z С ОСТРЫМ (U + 017A) | c5ba |
| Ż | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Z С ТОЧКОЙ ВЫШЕ (U + 017B) | c5bb |
| ż | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Z С ТОЧКОЙ ВЫШЕ (U + 017C) | c5bc |
| Ž | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Z С КАРОН (U + 017D) | c5bd |
| ž | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Z С КАРОН (U + 017E) | c5be |
| ſ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА ДЛИННАЯ S (U + 017F) | c5bf |
| ƀ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА B С ИНСУЛЬТОМ (U + 0180) | c680 |
| Ɓ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА B С КРЮЧКОМ (U + 0181) | c681 |
| Ƃ | ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА B С TOPBAR (U + 0182) | c682 |
| ƃ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА B С TOPBAR (U + 0183) | c683 |
| Ƅ | ЛАТИНСКАЯ ЗАГЛАВНАЯ БУКВА ШЕСТЬ (U + 0184) | c684 |
| ƅ | СТРОЧНАЯ ЛАТИНСКАЯ БУКВА ШЕСТЬ (U + 0185) | c685 |
| Ɔ | LATIN CAPITAL LETTER OPEN O (U+0186) | c686 |
| Ƈ | LATIN CAPITAL LETTER C WITH HOOK (U+0187) | c687 |
| ƈ | LATIN SMALL LETTER C WITH HOOK (U+0188) | c688 |
| Ɖ | LATIN CAPITAL LETTER AFRICAN D (U+0189) | c689 |
| Ɗ | LATIN CAPITAL LETTER D WITH HOOK (U+018A) | c68a |
| Ƌ | LATIN CAPITAL LETTER D WITH TOPBAR (U+018B) | c68b |
| ƌ | LATIN SMALL LETTER D WITH TOPBAR (U+018C) | c68c |
| ƍ | LATIN SMALL LETTER TURNED DELTA (U+018D) | c68d |
| Ǝ | LATIN CAPITAL LETTER REVERSED E (U+018E) | c68e |
| Ə | LATIN CAPITAL LETTER SCHWA (U+018F) | c68f |
| Ɛ | LATIN CAPITAL LETTER OPEN E (U+0190) | c690 |
| Ƒ | LATIN CAPITAL LETTER F WITH HOOK (U+0191) | c691 |
| ƒ | LATIN SMALL LETTER F WITH HOOK (U+0192) | c692 |
| Ɠ | LATIN CAPITAL LETTER G WITH HOOK (U+0193) | c693 |
| Ɣ | LATIN CAPITAL LETTER GAMMA (U+0194) | c694 |
| ƕ | LATIN SMALL LETTER HV (U+0195) | c695 |
| Ɩ | LATIN CAPITAL LETTER IOTA (U+0196) | c696 |
| Ɨ | LATIN CAPITAL LETTER I WITH STROKE (U+0197) | c697 |
| Ƙ | LATIN CAPITAL LETTER K WITH HOOK (U+0198) | c698 |
| ƙ | LATIN SMALL LETTER K WITH HOOK (U+0199) | c699 |
| ƚ | LATIN SMALL LETTER L WITH BAR (U+019A) | c69a |
| ƛ | LATIN SMALL LETTER LAMBDA WITH STROKE (U+019B) | c69b |
| Ɯ | LATIN CAPITAL LETTER TURNED M (U+019C) | c69c |
| Ɲ | LATIN CAPITAL LETTER N WITH LEFT HOOK (U+019D) | c69d |
| ƞ | LATIN SMALL LETTER N WITH LONG RIGHT LEG (U+019E) | c69e |
| Ɵ | LATIN CAPITAL LETTER O WITH MIDDLE TILDE (U+019F) | c69f |
| Ơ | LATIN CAPITAL LETTER O WITH HORN (U+01A0) | c6a0 |
| ơ | LATIN SMALL LETTER O WITH HORN (U+01A1) | c6a1 |
| Ƣ | LATIN CAPITAL LETTER OI (U+01A2) | c6a2 |
| ƣ | LATIN SMALL LETTER OI (U+01A3) | c6a3 |
| Ƥ | LATIN CAPITAL LETTER P WITH HOOK (U+01A4) | c6a4 |
| ƥ | LATIN SMALL LETTER P WITH HOOK (U+01A5) | c6a5 |
| Ʀ | LATIN LETTER YR (U+01A6) | c6a6 |
| Ƨ | LATIN CAPITAL LETTER TONE TWO (U+01A7) | c6a7 |
| ƨ | LATIN SMALL LETTER TONE TWO (U+01A8) | c6a8 |
| Ʃ | LATIN CAPITAL LETTER ESH (U+01A9) | c6a9 |
| ƪ | LATIN LETTER REVERSED ESH LOOP (U+01AA) | c6aa |
| ƫ | LATIN SMALL LETTER T WITH PALATAL HOOK (U+01AB) | c6ab |
| Ƭ | LATIN CAPITAL LETTER T WITH HOOK (U+01AC) | c6ac |
| ƭ | LATIN SMALL LETTER T WITH HOOK (U+01AD) | c6ad |
| Ʈ | LATIN CAPITAL LETTER T WITH RETROFLEX HOOK (U+01AE) | c6ae |
| Ư | LATIN CAPITAL LETTER U WITH HORN (U+01AF) | c6af |
| ư | LATIN SMALL LETTER U WITH HORN (U+01B0) | c6b0 |
| Ʊ | LATIN CAPITAL LETTER UPSILON (U+01B1) | c6b1 |
| Ʋ | LATIN CAPITAL LETTER V WITH HOOK (U+01B2) | c6b2 |
| Ƴ | LATIN CAPITAL LETTER Y WITH HOOK (U+01B3) | c6b3 |
| ƴ | LATIN SMALL LETTER Y WITH HOOK (U+01B4) | c6b4 |
| Ƶ | LATIN CAPITAL LETTER Z WITH STROKE (U+01B5) | c6b5 |
| ƶ | LATIN SMALL LETTER Z WITH STROKE (U+01B6) | c6b6 |
| Ʒ | LATIN CAPITAL LETTER EZH (U+01B7) | c6b7 |
| Ƹ | LATIN CAPITAL LETTER EZH REVERSED (U+01B8) | c6b8 |
| ƹ | LATIN SMALL LETTER EZH REVERSED (U+01B9) | c6b9 |
| ƺ | LATIN SMALL LETTER EZH WITH TAIL (U+01BA) | c6ba |
| ƻ | LATIN LETTER TWO WITH STROKE (U+01BB) | c6bb |
| Ƽ | LATIN CAPITAL LETTER TONE FIVE (U+01BC) | c6bc |
| ƽ | LATIN SMALL LETTER TONE FIVE (U+01BD) | c6bd |
| ƾ | LATIN LETTER INVERTED GLOTTAL STOP WITH STROKE (U+01BE) | c6be |
| ƿ | LATIN LETTER WYNN (U+01BF) | c6bf |
| ǀ | LATIN LETTER DENTAL CLICK (U+01C0) | c780 |
| ǁ | LATIN LETTER LATERAL CLICK (U+01C1) | c781 |
| ǂ | LATIN LETTER ALVEOLAR CLICK (U+01C2) | c782 |
| ǃ | LATIN LETTER RETROFLEX CLICK (U+01C3) | c783 |
| DŽ | LATIN CAPITAL LETTER DZ WITH CARON (U+01C4) | c784 |
| Dž | LATIN CAPITAL LETTER D WITH SMALL LETTER Z WITH CARON (U+01C5) | c785 |
| dž | LATIN SMALL LETTER DZ WITH CARON (U+01C6) | c786 |
| LJ | LATIN CAPITAL LETTER LJ (U+01C7) | c787 |
| Lj | LATIN CAPITAL LETTER L WITH SMALL LETTER J (U+01C8) | c788 |
| lj | LATIN SMALL LETTER LJ (U+01C9) | c789 |
| NJ | LATIN CAPITAL LETTER NJ (U+01CA) | c78a |
| Nj | LATIN CAPITAL LETTER N WITH SMALL LETTER J (U+01CB) | c78b |
| nj | LATIN SMALL LETTER NJ (U+01CC) | c78c |
| Ǎ | LATIN CAPITAL LETTER A WITH CARON (U+01CD) | c78d |
| ǎ | LATIN SMALL LETTER A WITH CARON (U+01CE) | c78e |
| Ǐ | LATIN CAPITAL LETTER I WITH CARON (U+01CF) | c78f |
| ǐ | LATIN SMALL LETTER I WITH CARON (U+01D0) | c790 |
| Ǒ | LATIN CAPITAL LETTER O WITH CARON (U+01D1) | c791 |
| ǒ | LATIN SMALL LETTER O WITH CARON (U+01D2) | c792 |
| Ǔ | LATIN CAPITAL LETTER U WITH CARON (U+01D3) | c793 |
| ǔ | LATIN SMALL LETTER U WITH CARON (U+01D4) | c794 |
| Ǖ | LATIN CAPITAL LETTER U WITH DIAERESIS AND MACRON (U+01D5) | c795 |
| ǖ | LATIN SMALL LETTER U WITH DIAERESIS AND MACRON (U+01D6) | c796 |
| Ǘ | LATIN CAPITAL LETTER U WITH DIAERESIS AND ACUTE (U+01D7) | c797 |
| ǘ | LATIN SMALL LETTER U WITH DIAERESIS AND ACUTE (U+01D8) | c798 |
| Ǚ | LATIN CAPITAL LETTER U WITH DIAERESIS AND CARON (U+01D9) | c799 |
| ǚ | LATIN SMALL LETTER U WITH DIAERESIS AND CARON (U+01DA) | c79a |
| Ǜ | LATIN CAPITAL LETTER U WITH DIAERESIS AND GRAVE (U+01DB) | c79b |
| ǜ | LATIN SMALL LETTER U WITH DIAERESIS AND GRAVE (U+01DC) | c79c |
| ǝ | LATIN SMALL LETTER TURNED E (U+01DD) | c79d |
| Ǟ | LATIN CAPITAL LETTER A WITH DIAERESIS AND MACRON (U+01DE) | c79e |
| ǟ | LATIN SMALL LETTER A WITH DIAERESIS AND MACRON (U+01DF) | c79f |
| Ǡ | LATIN CAPITAL LETTER A WITH DOT ABOVE AND MACRON (U+01E0) | c7a0 |
| ǡ | LATIN SMALL LETTER A WITH DOT ABOVE AND MACRON (U+01E1) | c7a1 |
| Ǣ | LATIN CAPITAL LETTER AE WITH MACRON (U+01E2) | c7a2 |
| ǣ | LATIN SMALL LETTER AE WITH MACRON (U+01E3) | c7a3 |
| Ǥ | LATIN CAPITAL LETTER G WITH STROKE (U+01E4) | c7a4 |
| ǥ | LATIN SMALL LETTER G WITH STROKE (U+01E5) | c7a5 |
| Ǧ | LATIN CAPITAL LETTER G WITH CARON (U+01E6) | c7a6 |
| ǧ | LATIN SMALL LETTER G WITH CARON (U+01E7) | c7a7 |
| Ǩ | LATIN CAPITAL LETTER K WITH CARON (U+01E8) | c7a8 |
| ǩ | LATIN SMALL LETTER K WITH CARON (U+01E9) | c7a9 |
| Ǫ | LATIN CAPITAL LETTER O WITH OGONEK (U+01EA) | c7aa |
| ǫ | LATIN SMALL LETTER O WITH OGONEK (U+01EB) | c7ab |
| Ǭ | LATIN CAPITAL LETTER O WITH OGONEK AND MACRON (U+01EC) | c7ac |
| ǭ | LATIN SMALL LETTER O WITH OGONEK AND MACRON (U+01ED) | c7ad |
| Ǯ | LATIN CAPITAL LETTER EZH WITH CARON (U+01EE) | c7ae |
| ǯ | LATIN SMALL LETTER EZH WITH CARON (U+01EF) | c7af |
| ǰ | LATIN SMALL LETTER J WITH CARON (U+01F0) | c7b0 |
| DZ | LATIN CAPITAL LETTER DZ (U+01F1) | c7b1 |
| Dz | LATIN CAPITAL LETTER D WITH SMALL LETTER Z (U+01F2) | c7b2 |
| dz | LATIN SMALL LETTER DZ (U+01F3) | c7b3 |
| Ǵ | LATIN CAPITAL LETTER G WITH ACUTE (U+01F4) | c7b4 |
| ǵ | LATIN SMALL LETTER G WITH ACUTE (U+01F5) | c7b5 |
| Ƕ | LATIN CAPITAL LETTER HWAIR (U+01F6) | c7b6 |
| Ƿ | LATIN CAPITAL LETTER WYNN (U+01F7) | c7b7 |
| Ǹ | LATIN CAPITAL LETTER N WITH GRAVE (U+01F8) | c7b8 |
| ǹ | LATIN SMALL LETTER N WITH GRAVE (U+01F9) | c7b9 |
| Ǻ | LATIN CAPITAL LETTER A WITH RING ABOVE AND ACUTE (U+01FA) | c7ba |
| ǻ | LATIN SMALL LETTER A WITH RING ABOVE AND ACUTE (U+01FB) | c7bb |
| Ǽ | LATIN CAPITAL LETTER AE WITH ACUTE (U+01FC) | c7bc |
| ǽ | LATIN SMALL LETTER AE WITH ACUTE (U+01FD) | c7bd |
| Ǿ | LATIN CAPITAL LETTER O WITH STROKE AND ACUTE (U+01FE) | c7be |
| ǿ | LATIN SMALL LETTER O WITH STROKE AND ACUTE (U+01FF) | c7bf |
| Ȁ | LATIN CAPITAL LETTER A WITH DOUBLE GRAVE (U+0200) | c880 |
| ȁ | LATIN SMALL LETTER A WITH DOUBLE GRAVE (U+0201) | c881 |
| Ȃ | LATIN CAPITAL LETTER A WITH INVERTED BREVE (U+0202) | c882 |
| ȃ | LATIN SMALL LETTER A WITH INVERTED BREVE (U+0203) | c883 |
| Ȅ | LATIN CAPITAL LETTER E WITH DOUBLE GRAVE (U+0204) | c884 |
| ȅ | LATIN SMALL LETTER E WITH DOUBLE GRAVE (U+0205) | c885 |
| Ȇ | LATIN CAPITAL LETTER E WITH INVERTED BREVE (U+0206) | c886 |
| ȇ | LATIN SMALL LETTER E WITH INVERTED BREVE (U+0207) | c887 |
| Ȉ | LATIN CAPITAL LETTER I WITH DOUBLE GRAVE (U+0208) | c888 |
| ȉ | LATIN SMALL LETTER I WITH DOUBLE GRAVE (U+0209) | c889 |
| Ȋ | LATIN CAPITAL LETTER I WITH INVERTED BREVE (U+020A) | c88a |
| ȋ | LATIN SMALL LETTER I WITH INVERTED BREVE (U+020B) | c88b |
| Ȍ | LATIN CAPITAL LETTER O WITH DOUBLE GRAVE (U+020C) | c88c |
| ȍ | LATIN SMALL LETTER O WITH DOUBLE GRAVE (U+020D) | c88d |
| Ȏ | LATIN CAPITAL LETTER O WITH INVERTED BREVE (U+020E) | c88e |
| ȏ | LATIN SMALL LETTER O WITH INVERTED BREVE (U+020F) | c88f |
| Ȑ | LATIN CAPITAL LETTER R WITH DOUBLE GRAVE (U+0210) | c890 |
| ȑ | LATIN SMALL LETTER R WITH DOUBLE GRAVE (U+0211) | c891 |
| Ȓ | LATIN CAPITAL LETTER R WITH INVERTED BREVE (U+0212) | c892 |
| ȓ | LATIN SMALL LETTER R WITH INVERTED BREVE (U+0213) | c893 |
| Ȕ | LATIN CAPITAL LETTER U WITH DOUBLE GRAVE (U+0214) | c894 |
| ȕ | LATIN SMALL LETTER U WITH DOUBLE GRAVE (U+0215) | c895 |
| Ȗ | LATIN CAPITAL LETTER U WITH INVERTED BREVE (U+0216) | c896 |
| ȗ | LATIN SMALL LETTER U WITH INVERTED BREVE (U+0217) | c897 |
| Ș | LATIN CAPITAL LETTER S WITH COMMA BELOW (U+0218) | c898 |
| ș | LATIN SMALL LETTER S WITH COMMA BELOW (U+0219) | c899 |
| Ț | LATIN CAPITAL LETTER T WITH COMMA BELOW (U+021A) | c89a |
| ț | LATIN SMALL LETTER T WITH COMMA BELOW (U+021B) | c89b |
| Ȝ | LATIN CAPITAL LETTER YOGH (U+021C) | c89c |
| ȝ | LATIN SMALL LETTER YOGH (U+021D) | c89d |
| Ȟ | LATIN CAPITAL LETTER H WITH CARON (U+021E) | c89e |
| ȟ | LATIN SMALL LETTER H WITH CARON (U+021F) | c89f |
| Ƞ | LATIN CAPITAL LETTER N WITH LONG RIGHT LEG (U+0220) | c8a0 |
| ȡ | LATIN SMALL LETTER D WITH CURL (U+0221) | c8a1 |
| Ȣ | LATIN CAPITAL LETTER OU (U+0222) | c8a2 |
| ȣ | LATIN SMALL LETTER OU (U+0223) | c8a3 |
| Ȥ | LATIN CAPITAL LETTER Z WITH HOOK (U+0224) | c8a4 |
| ȥ | LATIN SMALL LETTER Z WITH HOOK (U+0225) | c8a5 |
| Ȧ | LATIN CAPITAL LETTER A WITH DOT ABOVE (U+0226) | c8a6 |
| ȧ | LATIN SMALL LETTER A WITH DOT ABOVE (U+0227) | c8a7 |
| Ȩ | LATIN CAPITAL LETTER E WITH CEDILLA (U+0228) | c8a8 |
| ȩ | LATIN SMALL LETTER E WITH CEDILLA (U+0229) | c8a9 |
| Ȫ | LATIN CAPITAL LETTER O WITH DIAERESIS AND MACRON (U+022A) | c8aa |
| ȫ | LATIN SMALL LETTER O WITH DIAERESIS AND MACRON (U+022B) | c8ab |
| Ȭ | LATIN CAPITAL LETTER O WITH TILDE AND MACRON (U+022C) | c8ac |
| ȭ | LATIN SMALL LETTER O WITH TILDE AND MACRON (U+022D) | c8ad |
| Ȯ | LATIN CAPITAL LETTER O WITH DOT ABOVE (U+022E) | c8ae |
| ȯ | LATIN SMALL LETTER O WITH DOT ABOVE (U+022F) | c8af |
| Ȱ | LATIN CAPITAL LETTER O WITH DOT ABOVE AND MACRON (U+0230) | c8b0 |
| ȱ | LATIN SMALL LETTER O WITH DOT ABOVE AND MACRON (U+0231) | c8b1 |
| Ȳ | LATIN CAPITAL LETTER Y WITH MACRON (U+0232) | c8b2 |
| ȳ | LATIN SMALL LETTER Y WITH MACRON (U+0233) | c8b3 |
| ȴ | LATIN SMALL LETTER L WITH CURL (U+0234) | c8b4 |
| ȵ | LATIN SMALL LETTER N WITH CURL (U+0235) | c8b5 |
| ȶ | LATIN SMALL LETTER T WITH CURL (U+0236) | c8b6 |
| ȷ | LATIN SMALL LETTER DOTLESS J (U+0237) | c8b7 |
| ȸ | LATIN SMALL LETTER DB DIGRAPH (U+0238) | c8b8 |
| ȹ | LATIN SMALL LETTER QP DIGRAPH (U+0239) | c8b9 |
| Ⱥ | LATIN CAPITAL LETTER A WITH STROKE (U+023A) | c8ba |
| Ȼ | LATIN CAPITAL LETTER C WITH STROKE (U+023B) | c8bb |
| ȼ | LATIN SMALL LETTER C WITH STROKE (U+023C) | c8bc |
| Ƚ | LATIN CAPITAL LETTER L WITH BAR (U+023D) | c8bd |
| Ⱦ | LATIN CAPITAL LETTER T WITH DIAGONAL STROKE (U+023E) | c8be |
| ȿ | LATIN SMALL LETTER S WITH SWASH TAIL (U+023F) | c8bf |
| ɀ | LATIN SMALL LETTER Z WITH SWASH TAIL (U+0240) | c980 |
| Ɂ | LATIN CAPITAL LETTER GLOTTAL STOP (U+0241) | c981 |
| ɂ | LATIN SMALL LETTER GLOTTAL STOP (U+0242) | c982 |
| Ƀ | LATIN CAPITAL LETTER B WITH STROKE (U+0243) | c983 |
| Ʉ | LATIN CAPITAL LETTER U BAR (U+0244) | c984 |
| Ʌ | LATIN CAPITAL LETTER TURNED V (U+0245) | c985 |
| Ɇ | LATIN CAPITAL LETTER E WITH STROKE (U+0246) | c986 |
| ɇ | LATIN SMALL LETTER E WITH STROKE (U+0247) | c987 |
| Ɉ | LATIN CAPITAL LETTER J WITH STROKE (U+0248) | c988 |
| ɉ | LATIN SMALL LETTER J WITH STROKE (U+0249) | c989 |
| Ɋ | LATIN CAPITAL LETTER SMALL Q WITH HOOK TAIL (U+024A) | c98a |
| ɋ | LATIN SMALL LETTER Q WITH HOOK TAIL (U+024B) | c98b |
| Ɍ | LATIN CAPITAL LETTER R WITH STROKE (U+024C) | c98c |
| ɍ | LATIN SMALL LETTER R WITH STROKE (U+024D) | c98d |
| Ɏ | LATIN CAPITAL LETTER Y WITH STROKE (U+024E) | c98e |
| ɏ | LATIN SMALL LETTER Y WITH STROKE (U+024F) | c98f |
| ɐ | LATIN SMALL LETTER TURNED A (U+0250) | c990 |
| ɑ | LATIN SMALL LETTER ALPHA (U+0251) | c991 |
| ɒ | LATIN SMALL LETTER TURNED ALPHA (U+0252) | c992 |
| ɓ | LATIN SMALL LETTER B WITH HOOK (U+0253) | c993 |
| ɔ | LATIN SMALL LETTER OPEN O (U+0254) | c994 |
| ɕ | LATIN SMALL LETTER C WITH CURL (U+0255) | c995 |
| ɖ | LATIN SMALL LETTER D WITH TAIL (U+0256) | c996 |
| ɗ | LATIN SMALL LETTER D WITH HOOK (U+0257) | c997 |
| ɘ | LATIN SMALL LETTER REVERSED E (U+0258) | c998 |
| ə | LATIN SMALL LETTER SCHWA (U+0259) | c999 |
| ɚ | LATIN SMALL LETTER SCHWA WITH HOOK (U+025A) | c99a |
| ɛ | LATIN SMALL LETTER OPEN E (U+025B) | c99b |
| ɜ | LATIN SMALL LETTER REVERSED OPEN E (U+025C) | c99c |
| ɝ | LATIN SMALL LETTER REVERSED OPEN E WITH HOOK (U+025D) | c99d |
| ɞ | LATIN SMALL LETTER CLOSED REVERSED OPEN E (U+025E) | c99e |
| ɟ | LATIN SMALL LETTER DOTLESS J WITH STROKE (U+025F) | c99f |
| ɠ | LATIN SMALL LETTER G WITH HOOK (U+0260) | c9a0 |
| ɡ | LATIN SMALL LETTER SCRIPT G (U+0261) | c9a1 |
| ɢ | LATIN LETTER SMALL CAPITAL G (U+0262) | c9a2 |
| ɣ | LATIN SMALL LETTER GAMMA (U+0263) | c9a3 |
| ɤ | LATIN SMALL LETTER RAMS HORN (U+0264) | c9a4 |
| ɥ | LATIN SMALL LETTER TURNED H (U+0265) | c9a5 |
| ɦ | LATIN SMALL LETTER H WITH HOOK (U+0266) | c9a6 |
| ɧ | LATIN SMALL LETTER HENG WITH HOOK (U+0267) | c9a7 |
| ɨ | LATIN SMALL LETTER I WITH STROKE (U+0268) | c9a8 |
| ɩ | LATIN SMALL LETTER IOTA (U+0269) | c9a9 |
| ɪ | LATIN LETTER SMALL CAPITAL I (U+026A) | c9aa |
| ɫ | LATIN SMALL LETTER L WITH MIDDLE TILDE (U+026B) | c9ab |
| ɬ | LATIN SMALL LETTER L WITH BELT (U+026C) | c9ac |
| ɭ | LATIN SMALL LETTER L WITH RETROFLEX HOOK (U+026D) | c9ad |
| ɮ | LATIN SMALL LETTER LEZH (U+026E) | c9ae |
| ɯ | LATIN SMALL LETTER TURNED M (U+026F) | c9af |
| ɰ | LATIN SMALL LETTER TURNED M WITH LONG LEG (U+0270) | c9b0 |
| ɱ | LATIN SMALL LETTER M WITH HOOK (U+0271) | c9b1 |
| ɲ | LATIN SMALL LETTER N WITH LEFT HOOK (U+0272) | c9b2 |
| ɳ | LATIN SMALL LETTER N WITH RETROFLEX HOOK (U+0273) | c9b3 |
| ɴ | LATIN LETTER SMALL CAPITAL N (U+0274) | c9b4 |
| ɵ | LATIN SMALL LETTER BARRED O (U+0275) | c9b5 |
| ɶ | LATIN LETTER SMALL CAPITAL OE (U+0276) | c9b6 |
| ɷ | LATIN SMALL LETTER CLOSED OMEGA (U+0277) | c9b7 |
| ɸ | LATIN SMALL LETTER PHI (U+0278) | c9b8 |
| ɹ | LATIN SMALL LETTER TURNED R (U+0279) | c9b9 |
| ɺ | LATIN SMALL LETTER TURNED R WITH LONG LEG (U+027A) | c9ba |
| ɻ | LATIN SMALL LETTER TURNED R WITH HOOK (U+027B) | c9bb |
| ɼ | LATIN SMALL LETTER R WITH LONG LEG (U+027C) | c9bc |
| ɽ | LATIN SMALL LETTER R WITH TAIL (U+027D) | c9bd |
| ɾ | LATIN SMALL LETTER R WITH FISHHOOK (U+027E) | c9be |
| ɿ | LATIN SMALL LETTER REVERSED R WITH FISHHOOK (U+027F) | c9bf |
| ʀ | LATIN LETTER SMALL CAPITAL R (U+0280) | ca80 |
| ʁ | LATIN LETTER SMALL CAPITAL INVERTED R (U+0281) | ca81 |
| ʂ | LATIN SMALL LETTER S WITH HOOK (U+0282) | ca82 |
| ʃ | LATIN SMALL LETTER ESH (U+0283) | ca83 |
| ʄ | LATIN SMALL LETTER DOTLESS J WITH STROKE AND HOOK (U+0284) | ca84 |
| ʅ | LATIN SMALL LETTER SQUAT REVERSED ESH (U+0285) | ca85 |
| ʆ | LATIN SMALL LETTER ESH WITH CURL (U+0286) | ca86 |
| ʇ | LATIN SMALL LETTER TURNED T (U+0287) | ca87 |
| ʈ | LATIN SMALL LETTER T WITH RETROFLEX HOOK (U+0288) | ca88 |
| ʉ | LATIN SMALL LETTER U BAR (U+0289) | ca89 |
| ʊ | LATIN SMALL LETTER UPSILON (U+028A) | ca8a |
| ʋ | LATIN SMALL LETTER V WITH HOOK (U+028B) | ca8b |
| ʌ | LATIN SMALL LETTER TURNED V (U+028C) | ca8c |
| ʍ | LATIN SMALL LETTER TURNED W (U+028D) | ca8d |
| ʎ | LATIN SMALL LETTER TURNED Y (U+028E) | ca8e |
| ʏ | LATIN LETTER SMALL CAPITAL Y (U+028F) | ca8f |
| ʐ | LATIN SMALL LETTER Z WITH RETROFLEX HOOK (U+0290) | ca90 |
| ʑ | LATIN SMALL LETTER Z WITH CURL (U+0291) | ca91 |
| ʒ | LATIN SMALL LETTER EZH (U+0292) | ca92 |
| ʓ | LATIN SMALL LETTER EZH WITH CURL (U+0293) | ca93 |
| ʔ | LATIN LETTER GLOTTAL STOP (U+0294) | ca94 |
| ʕ | LATIN LETTER PHARYNGEAL VOICED FRICATIVE (U+0295) | ca95 |
| ʖ | LATIN LETTER INVERTED GLOTTAL STOP (U+0296) | ca96 |
| ʗ | LATIN LETTER STRETCHED C (U+0297) | ca97 |
| ʘ | LATIN LETTER BILABIAL CLICK (U+0298) | ca98 |
| ʙ | LATIN LETTER SMALL CAPITAL B (U+0299) | ca99 |
| ʚ | LATIN SMALL LETTER CLOSED OPEN E (U+029A) | ca9a |
| ʛ | LATIN LETTER SMALL CAPITAL G WITH HOOK (U+029B) | ca9b |
| ʜ | LATIN LETTER SMALL CAPITAL H (U+029C) | ca9c |
| ʝ | LATIN SMALL LETTER J WITH CROSSED-TAIL (U+029D) | ca9d |
| ʞ | LATIN SMALL LETTER TURNED K (U+029E) | ca9e |
| ʟ | LATIN LETTER SMALL CAPITAL L (U+029F) | ca9f |
| ʠ | LATIN SMALL LETTER Q WITH HOOK (U+02A0) | caa0 |
| ʡ | LATIN LETTER GLOTTAL STOP WITH STROKE (U+02A1) | caa1 |
| ʢ | LATIN LETTER REVERSED GLOTTAL STOP WITH STROKE (U+02A2) | caa2 |
| ʣ | LATIN SMALL LETTER DZ DIGRAPH (U+02A3) | caa3 |
| ʤ | LATIN SMALL LETTER DEZH DIGRAPH (U+02A4) | caa4 |
| ʥ | LATIN SMALL LETTER DZ DIGRAPH WITH CURL (U+02A5) | caa5 |
| ʦ | LATIN SMALL LETTER TS DIGRAPH (U+02A6) | caa6 |
| ʧ | LATIN SMALL LETTER TESH DIGRAPH (U+02A7) | caa7 |
| ʨ | LATIN SMALL LETTER TC DIGRAPH WITH CURL (U+02A8) | caa8 |
| ʩ | LATIN SMALL LETTER FENG DIGRAPH (U+02A9) | caa9 |
| ʪ | LATIN SMALL LETTER LS DIGRAPH (U+02AA) | caaa |
| ʫ | LATIN SMALL LETTER LZ DIGRAPH (U+02AB) | caab |
| ʬ | LATIN LETTER BILABIAL PERCUSSIVE (U+02AC) | caac |
| ʭ | LATIN LETTER BIDENTAL PERCUSSIVE (U+02AD) | caad |
| ʮ | LATIN SMALL LETTER TURNED H WITH FISHHOOK (U+02AE) | caae |
| ʯ | LATIN SMALL LETTER TURNED H WITH FISHHOOK AND TAIL (U+02AF) | caaf |
| ʰ | MODIFIER LETTER SMALL H (U+02B0) | cab0 |
| ʱ | MODIFIER LETTER SMALL H WITH HOOK (U+02B1) | cab1 |
| ʲ | MODIFIER LETTER SMALL J (U+02B2) | cab2 |
| ʳ | MODIFIER LETTER SMALL R (U+02B3) | cab3 |
| ʴ | MODIFIER LETTER SMALL TURNED R (U+02B4) | cab4 |
| ʵ | MODIFIER LETTER SMALL TURNED R WITH HOOK (U+02B5) | cab5 |
| ʶ | MODIFIER LETTER SMALL CAPITAL INVERTED R (U+02B6) | cab6 |
| ʷ | MODIFIER LETTER SMALL W (U+02B7) | cab7 |
| ʸ | MODIFIER LETTER SMALL Y (U+02B8) | cab8 |
| ʹ | MODIFIER LETTER PRIME (U+02B9) | cab9 |
| ʺ | MODIFIER LETTER DOUBLE PRIME (U+02BA) | caba |
| ʻ | MODIFIER LETTER TURNED COMMA (U+02BB) | cabb |
| ʼ | MODIFIER LETTER APOSTROPHE (U+02BC) | cabc |
| ʽ | MODIFIER LETTER REVERSED COMMA (U+02BD) | cabd |
| ʾ | MODIFIER LETTER RIGHT HALF RING (U+02BE) | cabe |
| ʿ | MODIFIER LETTER LEFT HALF RING (U+02BF) | cabf |
| ˀ | MODIFIER LETTER GLOTTAL STOP (U+02C0) | cb80 |
| ˁ | MODIFIER LETTER REVERSED GLOTTAL STOP (U+02C1) | cb81 |
| ˂ | MODIFIER LETTER LEFT ARROWHEAD (U+02C2) | cb82 |
| ˃ | MODIFIER LETTER RIGHT ARROWHEAD (U+02C3) | cb83 |
| ˄ | MODIFIER LETTER UP ARROWHEAD (U+02C4) | cb84 |
| ˅ | MODIFIER LETTER DOWN ARROWHEAD (U+02C5) | cb85 |
| ˆ | MODIFIER LETTER CIRCUMFLEX ACCENT (U+02C6) | cb86 |
| ˇ | CARON (U+02C7) | cb87 |
| ˈ | MODIFIER LETTER VERTICAL LINE (U+02C8) | cb88 |
| ˉ | MODIFIER LETTER MACRON (U+02C9) | cb89 |
| ˊ | MODIFIER LETTER ACUTE ACCENT (U+02CA) | cb8a |
| ˋ | MODIFIER LETTER GRAVE ACCENT (U+02CB) | cb8b |
| ˌ | MODIFIER LETTER LOW VERTICAL LINE (U+02CC) | cb8c |
| ˍ | MODIFIER LETTER LOW MACRON (U+02CD) | cb8d |
| ˎ | MODIFIER LETTER LOW GRAVE ACCENT (U+02CE) | cb8e |
| ˏ | MODIFIER LETTER LOW ACUTE ACCENT (U+02CF) | cb8f |
| ː | MODIFIER LETTER TRIANGULAR COLON (U+02D0) | cb90 |
| ˑ | MODIFIER LETTER HALF TRIANGULAR COLON (U+02D1) | cb91 |
| ˒ | MODIFIER LETTER CENTRED RIGHT HALF RING (U+02D2) | cb92 |
| ˓ | MODIFIER LETTER CENTRED LEFT HALF RING (U+02D3) | cb93 |
| ˔ | MODIFIER LETTER UP TACK (U+02D4) | cb94 |
| ˕ | MODIFIER LETTER DOWN TACK (U+02D5) | cb95 |
| ˖ | MODIFIER LETTER PLUS SIGN (U+02D6) | cb96 |
| ˗ | MODIFIER LETTER MINUS SIGN (U+02D7) | cb97 |
| ˘ | BREVE (U+02D8) | cb98 |
| ˙ | DOT ABOVE (U+02D9) | cb99 |
| ˚ | RING ABOVE (U+02DA) | cb9a |
| ˛ | OGONEK (U+02DB) | cb9b |
| ˜ | SMALL TILDE (U+02DC) | cb9c |
| ˝ | DOUBLE ACUTE ACCENT (U+02DD) | cb9d |
| ˞ | MODIFIER LETTER RHOTIC HOOK (U+02DE) | cb9e |
| ˟ | MODIFIER LETTER CROSS ACCENT (U+02DF) | cb9f |
| ˠ | MODIFIER LETTER SMALL GAMMA (U+02E0) | cba0 |
| ˡ | MODIFIER LETTER SMALL L (U+02E1) | cba1 |
| ˢ | MODIFIER LETTER SMALL S (U+02E2) | cba2 |
| ˣ | MODIFIER LETTER SMALL X (U+02E3) | cba3 |
| ˤ | MODIFIER LETTER SMALL REVERSED GLOTTAL STOP (U+02E4) | cba4 |
| ˥ | MODIFIER LETTER EXTRA-HIGH TONE BAR (U+02E5) | cba5 |
| ˦ | MODIFIER LETTER HIGH TONE BAR (U+02E6) | cba6 |
| ˧ | MODIFIER LETTER MID TONE BAR (U+02E7) | cba7 |
| ˨ | MODIFIER LETTER LOW TONE BAR (U+02E8) | cba8 |
| ˩ | MODIFIER LETTER EXTRA-LOW TONE BAR (U+02E9) | cba9 |
| ˪ | MODIFIER LETTER YIN DEPARTING TONE MARK (U+02EA) | cbaa |
| ˫ | MODIFIER LETTER YANG DEPARTING TONE MARK (U+02EB) | cbab |
| ˬ | MODIFIER LETTER VOICING (U+02EC) | cbac |
| ˭ | MODIFIER LETTER UNASPIRATED (U+02ED) | cbad |
| ˮ | MODIFIER LETTER DOUBLE APOSTROPHE (U+02EE) | cbae |
| ˯ | MODIFIER LETTER LOW DOWN ARROWHEAD (U+02EF) | cbaf |
| ˰ | MODIFIER LETTER LOW UP ARROWHEAD (U+02F0) | cbb0 |
| ˱ | MODIFIER LETTER LOW LEFT ARROWHEAD (U+02F1) | cbb1 |
| ˲ | MODIFIER LETTER LOW RIGHT ARROWHEAD (U+02F2) | cbb2 |
| ˳ | MODIFIER LETTER LOW RING (U+02F3) | cbb3 |
| ˴ | MODIFIER LETTER MIDDLE GRAVE ACCENT (U+02F4) | cbb4 |
| ˵ | MODIFIER LETTER MIDDLE DOUBLE GRAVE ACCENT (U+02F5) | cbb5 |
| ˶ | MODIFIER LETTER MIDDLE DOUBLE ACUTE ACCENT (U+02F6) | cbb6 |
| ˷ | MODIFIER LETTER LOW TILDE (U+02F7) | cbb7 |
| ˸ | MODIFIER LETTER RAISED COLON (U+02F8) | cbb8 |
| ˹ | MODIFIER LETTER BEGIN HIGH TONE (U+02F9) | cbb9 |
| ˺ | MODIFIER LETTER END HIGH TONE (U+02FA) | cbba |
| ˻ | MODIFIER LETTER BEGIN LOW TONE (U+02FB) | cbbb |
| ˼ | MODIFIER LETTER END LOW TONE (U+02FC) | cbbc |
| ˽ | MODIFIER LETTER SHELF (U+02FD) | cbbd |
| ˾ | MODIFIER LETTER OPEN SHELF (U+02FE) | cbbe |
| ˿ | MODIFIER LETTER LOW LEFT ARROW (U+02FF) | cbbf |
| ̀ | COMBINING GRAVE ACCENT (U+0300) | cc80 |
| ́ | COMBINING ACUTE ACCENT (U+0301) | cc81 |
| ̂ | COMBINING CIRCUMFLEX ACCENT (U+0302) | cc82 |
| ̃ | COMBINING TILDE (U+0303) | cc83 |
| ̄ | COMBINING MACRON (U+0304) | cc84 |
| ̅ | COMBINING OVERLINE (U+0305) | cc85 |
| ̆ | COMBINING BREVE (U+0306) | cc86 |
| ̇ | COMBINING DOT ABOVE (U+0307) | cc87 |
| ̈ | COMBINING DIAERESIS (U+0308) | cc88 |
| ̉ | COMBINING HOOK ABOVE (U+0309) | cc89 |
| ̊ | COMBINING RING ABOVE (U+030A) | cc8a |
| ̋ | COMBINING DOUBLE ACUTE ACCENT (U+030B) | cc8b |
| ̌ | COMBINING CARON (U+030C) | cc8c |
| ̍ | COMBINING VERTICAL LINE ABOVE (U+030D) | cc8d |
| ̎ | COMBINING DOUBLE VERTICAL LINE ABOVE (U+030E) | cc8e |
| ̏ | COMBINING DOUBLE GRAVE ACCENT (U+030F) | cc8f |
| ̐ | COMBINING CANDRABINDU (U+0310) | cc90 |
| ̑ | COMBINING INVERTED BREVE (U+0311) | cc91 |
| ̒ | COMBINING TURNED COMMA ABOVE (U+0312) | cc92 |
| ̓ | COMBINING COMMA ABOVE (U+0313) | cc93 |
| ̔ | COMBINING REVERSED COMMA ABOVE (U+0314) | cc94 |
| ̕ | COMBINING COMMA ABOVE RIGHT (U+0315) | cc95 |
| ̖ | COMBINING GRAVE ACCENT BELOW (U+0316) | cc96 |
| ̗ | COMBINING ACUTE ACCENT BELOW (U+0317) | cc97 |
| ̘ | COMBINING LEFT TACK BELOW (U+0318) | cc98 |
| ̙ | COMBINING RIGHT TACK BELOW (U+0319) | cc99 |
| ̚ | COMBINING LEFT ANGLE ABOVE (U+031A) | cc9a |
| ̛ | COMBINING HORN (U+031B) | cc9b |
| ̜ | COMBINING LEFT HALF RING BELOW (U+031C) | cc9c |
| ̝ | COMBINING UP TACK BELOW (U+031D) | cc9d |
| ̞ | COMBINING DOWN TACK BELOW (U+031E) | cc9e |
| ̟ | COMBINING PLUS SIGN BELOW (U+031F) | cc9f |
| ̠ | COMBINING MINUS SIGN BELOW (U+0320) | cca0 |
| ̡ | COMBINING PALATALIZED HOOK BELOW (U+0321) | cca1 |
| ̢ | COMBINING RETROFLEX HOOK BELOW (U+0322) | cca2 |
| ̣ | COMBINING DOT BELOW (U+0323) | cca3 |
| ̤ | COMBINING DIAERESIS BELOW (U+0324) | cca4 |
| ̥ | COMBINING RING BELOW (U+0325) | cca5 |
| ̦ | COMBINING COMMA BELOW (U+0326) | cca6 |
| ̧ | COMBINING CEDILLA (U+0327) | cca7 |
| ̨ | COMBINING OGONEK (U+0328) | cca8 |
| ̩ | COMBINING VERTICAL LINE BELOW (U+0329) | cca9 |
| ̪ | COMBINING BRIDGE BELOW (U+032A) | ccaa |
| ̫ | COMBINING INVERTED DOUBLE ARCH BELOW (U+032B) | ccab |
| ̬ | COMBINING CARON BELOW (U+032C) | ccac |
| ̭ | COMBINING CIRCUMFLEX ACCENT BELOW (U+032D) | ccad |
| ̮ | COMBINING BREVE BELOW (U+032E) | ccae |
| ̯ | COMBINING INVERTED BREVE BELOW (U+032F) | ccaf |
| ̰ | COMBINING TILDE BELOW (U+0330) | ccb0 |
| ̱ | COMBINING MACRON BELOW (U+0331) | ccb1 |
| ̲ | COMBINING LOW LINE (U+0332) | ccb2 |
| ̳ | COMBINING DOUBLE LOW LINE (U+0333) | ccb3 |
| ̴ | COMBINING TILDE OVERLAY (U+0334) | ccb4 |
| ̵ | COMBINING SHORT STROKE OVERLAY (U+0335) | ccb5 |
| ̶ | COMBINING LONG STROKE OVERLAY (U+0336) | ccb6 |
| ̷ | COMBINING SHORT SOLIDUS OVERLAY (U+0337) | ccb7 |
| ̸ | COMBINING LONG SOLIDUS OVERLAY (U+0338) | ccb8 |
| ̹ | COMBINING RIGHT HALF RING BELOW (U+0339) | ccb9 |
| ̺ | COMBINING INVERTED BRIDGE BELOW (U+033A) | ccba |
| ̻ | COMBINING SQUARE BELOW (U+033B) | ccbb |
| ̼ | COMBINING SEAGULL BELOW (U+033C) | ccbc |
| ̽ | COMBINING X ABOVE (U+033D) | ccbd |
| ̾ | COMBINING VERTICAL TILDE (U+033E) | ccbe |
| ̿ | COMBINING DOUBLE OVERLINE (U+033F) | ccbf |
| ̀ | COMBINING GRAVE TONE MARK (U+0340) | cd80 |
| ́ | COMBINING ACUTE TONE MARK (U+0341) | cd81 |
| ͂ | COMBINING GREEK PERISPOMENI (U+0342) | cd82 |
| ̓ | COMBINING GREEK KORONIS (U+0343) | cd83 |
| ̈́ | COMBINING GREEK DIALYTIKA TONOS (U+0344) | cd84 |
| ͅ | COMBINING GREEK YPOGEGRAMMENI (U+0345) | cd85 |
| ͆ | COMBINING BRIDGE ABOVE (U+0346) | cd86 |
| ͇ | COMBINING EQUALS SIGN BELOW (U+0347) | cd87 |
| ͈ | COMBINING DOUBLE VERTICAL LINE BELOW (U+0348) | cd88 |
| ͉ | COMBINING LEFT ANGLE BELOW (U+0349) | cd89 |
| ͊ | COMBINING NOT TILDE ABOVE (U+034A) | cd8a |
| ͋ | COMBINING HOMOTHETIC ABOVE (U+034B) | cd8b |
| ͌ | COMBINING ALMOST EQUAL TO ABOVE (U+034C) | cd8c |
| ͍ | COMBINING LEFT RIGHT ARROW BELOW (U+034D) | cd8d |
| ͎ | COMBINING UPWARDS ARROW BELOW (U+034E) | cd8e |
| ͏ | COMBINING GRAPHEME JOINER (U+034F) | cd8f |
| ͐ | COMBINING RIGHT ARROWHEAD ABOVE (U+0350) | cd90 |
| ͑ | COMBINING LEFT HALF RING ABOVE (U+0351) | cd91 |
| ͒ | COMBINING FERMATA (U+0352) | cd92 |
| ͓ | COMBINING X BELOW (U+0353) | cd93 |
| ͔ | COMBINING LEFT ARROWHEAD BELOW (U+0354) | cd94 |
| ͕ | COMBINING RIGHT ARROWHEAD BELOW (U+0355) | cd95 |
| ͖ | COMBINING RIGHT ARROWHEAD AND UP ARROWHEAD BELOW (U+0356) | cd96 |
| ͗ | COMBINING RIGHT HALF RING ABOVE (U+0357) | cd97 |
| ͘ | COMBINING DOT ABOVE RIGHT (U+0358) | cd98 |
| ͙ | COMBINING ASTERISK BELOW (U+0359) | cd99 |
| ͚ | COMBINING DOUBLE RING BELOW (U+035A) | cd9a |
| ͛ | COMBINING ZIGZAG ABOVE (U+035B) | cd9b |
| ͜ | COMBINING DOUBLE BREVE BELOW (U+035C) | cd9c |
| ͝ | COMBINING DOUBLE BREVE (U+035D) | cd9d |
| ͞ | COMBINING DOUBLE MACRON (U+035E) | cd9e |
| ͟ | COMBINING DOUBLE MACRON BELOW (U+035F) | cd9f |
| ͠ | COMBINING DOUBLE TILDE (U+0360) | cda0 |
| ͡ | COMBINING DOUBLE INVERTED BREVE (U+0361) | cda1 |
| ͢ | COMBINING DOUBLE RIGHTWARDS ARROW BELOW (U+0362) | cda2 |
| ͣ | COMBINING LATIN SMALL LETTER A (U+0363) | cda3 |
| ͤ | COMBINING LATIN SMALL LETTER E (U+0364) | cda4 |
| ͥ | COMBINING LATIN SMALL LETTER I (U+0365) | cda5 |
| ͦ | COMBINING LATIN SMALL LETTER O (U+0366) | cda6 |
| ͧ | COMBINING LATIN SMALL LETTER U (U+0367) | cda7 |
| ͨ | COMBINING LATIN SMALL LETTER C (U+0368) | cda8 |
| ͩ | COMBINING LATIN SMALL LETTER D (U+0369) | cda9 |
| ͪ | COMBINING LATIN SMALL LETTER H (U+036A) | cdaa |
| ͫ | COMBINING LATIN SMALL LETTER M (U+036B) | cdab |
| ͬ | COMBINING LATIN SMALL LETTER R (U+036C) | cdac |
| ͭ | COMBINING LATIN SMALL LETTER T (U+036D) | cdad |
| ͮ | COMBINING LATIN SMALL LETTER V (U+036E) | cdae |
| ͯ | COMBINING LATIN SMALL LETTER X (U+036F) | cdaf |
| Ͱ | GREEK CAPITAL LETTER HETA (U+0370) | cdb0 |
| ͱ | GREEK SMALL LETTER HETA (U+0371) | cdb1 |
| Ͳ | GREEK CAPITAL LETTER ARCHAIC SAMPI (U+0372) | cdb2 |
| ͳ | GREEK SMALL LETTER ARCHAIC SAMPI (U+0373) | cdb3 |
| ʹ | GREEK NUMERAL SIGN (U+0374) | cdb4 |
| ͵ | GREEK LOWER NUMERAL SIGN (U+0375) | cdb5 |
| Ͷ | GREEK CAPITAL LETTER PAMPHYLIAN DIGAMMA (U+0376) | cdb6 |
| ͷ | GREEK SMALL LETTER PAMPHYLIAN DIGAMMA (U+0377) | cdb7 |
| ͺ | GREEK YPOGEGRAMMENI (U+037A) | cdba |
| ͻ | GREEK SMALL REVERSED LUNATE SIGMA SYMBOL (U+037B) | cdbb |
| ͼ | GREEK SMALL DOTTED LUNATE SIGMA SYMBOL (U+037C) | cdbc |
| ͽ | GREEK SMALL REVERSED DOTTED LUNATE SIGMA SYMBOL (U+037D) | cdbd |
| ; | GREEK QUESTION MARK (U+037E) | cdbe |
| Ϳ | GREEK CAPITAL LETTER YOT (U+037F) | cdbf |
| ΄ | GREEK TONOS (U+0384) | ce84 |
| ΅ | GREEK DIALYTIKA TONOS (U+0385) | ce85 |
| Ά | GREEK CAPITAL LETTER ALPHA WITH TONOS (U+0386) | ce86 |
| · | GREEK ANO TELEIA (U+0387) | ce87 |
| Έ | GREEK CAPITAL LETTER EPSILON WITH TONOS (U+0388) | ce88 |
| Ή | GREEK CAPITAL LETTER ETA WITH TONOS (U+0389) | ce89 |
| Ί | GREEK CAPITAL LETTER IOTA WITH TONOS (U+038A) | ce8a |
| Ό | GREEK CAPITAL LETTER OMICRON WITH TONOS (U+038C) | ce8c |
| Ύ | GREEK CAPITAL LETTER UPSILON WITH TONOS (U+038E) | ce8e |
| Ώ | GREEK CAPITAL LETTER OMEGA WITH TONOS (U+038F) | ce8f |
| ΐ | GREEK SMALL LETTER IOTA WITH DIALYTIKA AND TONOS (U+0390) | ce90 |
| Α | GREEK CAPITAL LETTER ALPHA (U+0391) | ce91 |
| Β | GREEK CAPITAL LETTER BETA (U+0392) | ce92 |
| Γ | GREEK CAPITAL LETTER GAMMA (U+0393) | ce93 |
| Δ | GREEK CAPITAL LETTER DELTA (U+0394) | ce94 |
| Ε | GREEK CAPITAL LETTER EPSILON (U+0395) | ce95 |
| Ζ | GREEK CAPITAL LETTER ZETA (U+0396) | ce96 |
| Η | GREEK CAPITAL LETTER ETA (U+0397) | ce97 |
| Θ | GREEK CAPITAL LETTER THETA (U+0398) | ce98 |
| Ι | GREEK CAPITAL LETTER IOTA (U+0399) | ce99 |
| Κ | GREEK CAPITAL LETTER KAPPA (U+039A) | ce9a |
| Λ | GREEK CAPITAL LETTER LAMDA (U+039B) | ce9b |
| Μ | GREEK CAPITAL LETTER MU (U+039C) | ce9c |
| Ν | GREEK CAPITAL LETTER NU (U+039D) | ce9d |
| Ξ | GREEK CAPITAL LETTER XI (U+039E) | ce9e |
| Ο | GREEK CAPITAL LETTER OMICRON (U+039F) | ce9f |
| Π | GREEK CAPITAL LETTER PI (U+03A0) | cea0 |
| Ρ | GREEK CAPITAL LETTER RHO (U+03A1) | cea1 |
| Σ | GREEK CAPITAL LETTER SIGMA (U+03A3) | cea3 |
| Τ | GREEK CAPITAL LETTER TAU (U+03A4) | cea4 |
| Υ | GREEK CAPITAL LETTER UPSILON (U+03A5) | cea5 |
| Φ | GREEK CAPITAL LETTER PHI (U+03A6) | cea6 |
| Χ | GREEK CAPITAL LETTER CHI (U+03A7) | cea7 |
| Ψ | GREEK CAPITAL LETTER PSI (U+03A8) | cea8 |
| Ω | GREEK CAPITAL LETTER OMEGA (U+03A9) | cea9 |
| Ϊ | GREEK CAPITAL LETTER IOTA WITH DIALYTIKA (U+03AA) | ceaa |
| Ϋ | GREEK CAPITAL LETTER UPSILON WITH DIALYTIKA (U+03AB) | ceab |
| ά | GREEK SMALL LETTER ALPHA WITH TONOS (U+03AC) | ceac |
| έ | GREEK SMALL LETTER EPSILON WITH TONOS (U+03AD) | cead |
| ή | GREEK SMALL LETTER ETA WITH TONOS (U+03AE) | ceae |
| ί | GREEK SMALL LETTER IOTA WITH TONOS (U+03AF) | ceaf |
| ΰ | GREEK SMALL LETTER UPSILON WITH DIALYTIKA AND TONOS (U+03B0) | ceb0 |
| α | GREEK SMALL LETTER ALPHA (U+03B1) | ceb1 |
| β | GREEK SMALL LETTER BETA (U+03B2) | ceb2 |
| γ | GREEK SMALL LETTER GAMMA (U+03B3) | ceb3 |
| δ | GREEK SMALL LETTER DELTA (U+03B4) | ceb4 |
| ε | GREEK SMALL LETTER EPSILON (U+03B5) | ceb5 |
| ζ | GREEK SMALL LETTER ZETA (U+03B6) | ceb6 |
| η | GREEK SMALL LETTER ETA (U+03B7) | ceb7 |
| θ | GREEK SMALL LETTER THETA (U+03B8) | ceb8 |
| ι | GREEK SMALL LETTER IOTA (U+03B9) | ceb9 |
| κ | GREEK SMALL LETTER KAPPA (U+03BA) | ceba |
| λ | GREEK SMALL LETTER LAMDA (U+03BB) | cebb |
| μ | GREEK SMALL LETTER MU (U+03BC) | cebc |
| ν | GREEK SMALL LETTER NU (U+03BD) | cebd |
| ξ | GREEK SMALL LETTER XI (U+03BE) | cebe |
| ο | GREEK SMALL LETTER OMICRON (U+03BF) | cebf |
| π | GREEK SMALL LETTER PI (U+03C0) | cf80 |
| ρ | GREEK SMALL LETTER RHO (U+03C1) | cf81 |
| ς | GREEK SMALL LETTER FINAL SIGMA (U+03C2) | cf82 |
| σ | GREEK SMALL LETTER SIGMA (U+03C3) | cf83 |
| τ | GREEK SMALL LETTER TAU (U+03C4) | cf84 |
| υ | GREEK SMALL LETTER UPSILON (U+03C5) | cf85 |
| φ | GREEK SMALL LETTER PHI (U+03C6) | cf86 |
| χ | GREEK SMALL LETTER CHI (U+03C7) | cf87 |
| ψ | GREEK SMALL LETTER PSI (U+03C8) | cf88 |
| ω | GREEK SMALL LETTER OMEGA (U+03C9) | cf89 |
| ϊ | GREEK SMALL LETTER IOTA WITH DIALYTIKA (U+03CA) | cf8a |
| ϋ | GREEK SMALL LETTER UPSILON WITH DIALYTIKA (U+03CB) | cf8b |
| ό | GREEK SMALL LETTER OMICRON WITH TONOS (U+03CC) | cf8c |
| ύ | GREEK SMALL LETTER UPSILON WITH TONOS (U+03CD) | cf8d |
| ώ | GREEK SMALL LETTER OMEGA WITH TONOS (U+03CE) | cf8e |
| Ϗ | GREEK CAPITAL KAI SYMBOL (U+03CF) | cf8f |
| ϐ | GREEK BETA SYMBOL (U+03D0) | cf90 |
| ϑ | GREEK THETA SYMBOL (U+03D1) | cf91 |
| ϒ | GREEK UPSILON WITH HOOK SYMBOL (U+03D2) | cf92 |
| ϓ | GREEK UPSILON WITH ACUTE AND HOOK SYMBOL (U+03D3) | cf93 |
| ϔ | GREEK UPSILON WITH DIAERESIS AND HOOK SYMBOL (U+03D4) | cf94 |
| ϕ | GREEK PHI SYMBOL (U+03D5) | cf95 |
| ϖ | GREEK PI SYMBOL (U+03D6) | cf96 |
| ϗ | GREEK KAI SYMBOL (U+03D7) | cf97 |
| Ϙ | GREEK LETTER ARCHAIC KOPPA (U+03D8) | cf98 |
| ϙ | GREEK SMALL LETTER ARCHAIC KOPPA (U+03D9) | cf99 |
| Ϛ | GREEK LETTER STIGMA (U+03DA) | cf9a |
| ϛ | GREEK SMALL LETTER STIGMA (U+03DB) | cf9b |
| Ϝ | GREEK LETTER DIGAMMA (U+03DC) | cf9c |
| ϝ | GREEK SMALL LETTER DIGAMMA (U+03DD) | cf9d |
| Ϟ | GREEK LETTER KOPPA (U+03DE) | cf9e |
| ϟ | GREEK SMALL LETTER KOPPA (U+03DF) | cf9f |
| Ϡ | GREEK LETTER SAMPI (U+03E0) | cfa0 |
| ϡ | GREEK SMALL LETTER SAMPI (U+03E1) | cfa1 |
| Ϣ | COPTIC CAPITAL LETTER SHEI (U+03E2) | cfa2 |
| ϣ | COPTIC SMALL LETTER SHEI (U+03E3) | cfa3 |
| Ϥ | COPTIC CAPITAL LETTER FEI (U+03E4) | cfa4 |
| ϥ | COPTIC SMALL LETTER FEI (U+03E5) | cfa5 |
| Ϧ | COPTIC CAPITAL LETTER KHEI (U+03E6) | cfa6 |
| ϧ | COPTIC SMALL LETTER KHEI (U+03E7) | cfa7 |
| Ϩ | COPTIC CAPITAL LETTER HORI (U+03E8) | cfa8 |
| ϩ | COPTIC SMALL LETTER HORI (U+03E9) | cfa9 |
| Ϫ | COPTIC CAPITAL LETTER GANGIA (U+03EA) | cfaa |
| ϫ | COPTIC SMALL LETTER GANGIA (U+03EB) | cfab |
| Ϭ | COPTIC CAPITAL LETTER SHIMA (U+03EC) | cfac |
| ϭ | COPTIC SMALL LETTER SHIMA (U+03ED) | cfad |
| Ϯ | COPTIC CAPITAL LETTER DEI (U+03EE) | cfae |
| ϯ | COPTIC SMALL LETTER DEI (U+03EF) | cfaf |
| ϰ | GREEK KAPPA SYMBOL (U+03F0) | cfb0 |
| ϱ | GREEK RHO SYMBOL (U+03F1) | cfb1 |
| ϲ | GREEK LUNATE SIGMA SYMBOL (U+03F2) | cfb2 |
| ϳ | GREEK LETTER YOT (U+03F3) | cfb3 |
| ϴ | GREEK CAPITAL THETA SYMBOL (U+03F4) | cfb4 |
| ϵ | GREEK LUNATE EPSILON SYMBOL (U+03F5) | cfb5 |
| ϶ | GREEK REVERSED LUNATE EPSILON SYMBOL (U+03F6) | cfb6 |
| Ϸ | GREEK CAPITAL LETTER SHO (U+03F7) | cfb7 |
| ϸ | GREEK SMALL LETTER SHO (U+03F8) | cfb8 |
| Ϲ | GREEK CAPITAL LUNATE SIGMA SYMBOL (U+03F9) | cfb9 |
| Ϻ | GREEK CAPITAL LETTER SAN (U+03FA) | cfba |
| ϻ | GREEK SMALL LETTER SAN (U+03FB) | cfbb |
| ϼ | GREEK RHO WITH STROKE SYMBOL (U+03FC) | cfbc |
| Ͻ | GREEK CAPITAL REVERSED LUNATE SIGMA SYMBOL (U+03FD) | cfbd |
| Ͼ | GREEK CAPITAL DOTTED LUNATE SIGMA SYMBOL (U+03FE) | cfbe |
| Ͽ | GREEK CAPITAL REVERSED DOTTED LUNATE SIGMA SYMBOL (U+03FF) | cfbf |
| Ѐ | CYRILLIC CAPITAL LETTER IE WITH GRAVE (U+0400) | d080 |
| Ё | CYRILLIC CAPITAL LETTER IO (U+0401) | d081 |
| Ђ | CYRILLIC CAPITAL LETTER DJE (U+0402) | d082 |
| Ѓ | CYRILLIC CAPITAL LETTER GJE (U+0403) | d083 |
| Є | CYRILLIC CAPITAL LETTER UKRAINIAN IE (U+0404) | d084 |
| Ѕ | CYRILLIC CAPITAL LETTER DZE (U+0405) | d085 |
| І | CYRILLIC CAPITAL LETTER BYELORUSSIAN-UKRAINIAN I (U+0406) | d086 |
| Ї | CYRILLIC CAPITAL LETTER YI (U+0407) | d087 |
| Ј | CYRILLIC CAPITAL LETTER JE (U+0408) | d088 |
| More. | ||