Классификация характеров
В целом не может быть абсолютной или универсальной классификации характеров, деления их на типы. Основания для типизации, как правило вводятся исследователем или заинтересованным лицом для того, чтобы в соответствии с имеющейся задачей раздеть людей на группы по преобладающим качествам. Так сходные характеры могут наблюдаться у людей имеющих доминирующие волевые или эмоциональные качества. Соответственно делят характеры на типы: волевой (активный, целеустремленный, деятельный) ; эмоциональный (действующий под влиянием порыва, переживаний) ; рассудочный (оценивающий все с точки зрения разумности).
К. Юнг предложил классифицировать характеры в зависимости от принадлежности к экстравертированному и интравертированному типу.
ОБЩЕЕ ОПИСАНИЕ ТИПОВ
Экстравертированный тип . Характеризуется обращенностью личности на окружающий мир, объекты которого подобно магниту, притягивают к себе интересы, жизненную энергию субъекта, в известном смысле ведет к принижению личностной значимости явлений его субъективного мира.
Интровертированный тип . Для него характерна фиксация интересов личности на явлениях собственного внутреннего мира, которым она придает высшую ценность, необщительность, замкнутость, склонность к самоанализу, затрудненная адаптация.
Возможна также классификация на конфорный и самостоятельный; доминирующий и подчиняющийся; нормативный и анархический и прочие типы.
Черт характера чрезвычайно велико, каждая из черт имеет разную качественную степень выраженности.
Чрезмерную выраженность отдельных черт характера и их сочетаний, представляющую крайние варианты нормы, называют акцентуацией характера . Практическая акцентуация — это предельная величина, крайний вариант проявления нормы. Акцентуации характера свойственна повышенная уязвимость лишь к определенного рода психотравматическим воздействиям, адресованным к так называемому «месту наименьшего сопротивления» данного типа характера при сохранении устойчивости к другим. Это слабое звено в характере человека проявляется только в ситуациях, предъявляющих повышенные требования к функционированию именно этого звена, во всех других ситуациях, не затрагивающих уязвимых точек характера, индивид ведет себя без срывов не доставляя неприятностей ни окружающим, ни себе.
Это слабое звено в характере человека проявляется только в ситуациях, предъявляющих повышенные требования к функционированию именно этого звена, во всех других ситуациях, не затрагивающих уязвимых точек характера, индивид ведет себя без срывов не доставляя неприятностей ни окружающим, ни себе.
В зависимости от степени выраженности различают явные и скрытые (латентные) акцентуации характера. Явные, или выраженные, акцентуации относят к крайней границе нормы и отличаются постоянными чертами определенного типа характера. Скрытая акцентуация представляет собой обычный вариант нормы, выраженный слабо или не выраженный совсем. Такие акцентуации могут проявляться неожиданно под влиянием ситуаций и травм, представляющих требования к месту наименьшего сопротивления, в то время как психогенные факторы иного рода, даже тяжелые, не только не вызывают психических расстройств, но могут даже не выявить типа характера. Оба типа акцентуации могут переходить друг в друга под влиянием различных факторов, среди которых важную роль играют особенности семейного воспитания, социального окружения, профессиональной деятельности и т.
См. также
Характер и темперамент
RSS [email protected]
Классификация типов характера — Реферат
Классификация характера
Попытки построения типологии характеров неоднократно предпринимались на протяжении всей истории психологии. Наиболее и ранняя из них предложена немецким психиатром и психологом Эрнстом Кречмером (1888-1964). Несколько позже аналогичную попытку предпринял его американский коллега У. Шелдон, а в наши дни – Э. Фромм, К. Леонгард, А. Е. Личко и ряд других ученых.
Все типологии исходили из ряда общих идей:
1. Характер человека формируется довольно рано в онтогенезе и на протяжении остальной его жизни проявляет себя как более или менее устойчивый.
2.
Те сочетания личностных черт, которые
входят в характер человека, не являются
случайными. Они образуют четко различимые
типы, позволяющие выявлять и строить
типологию характеров.
3. Большая часть людей в соответствии с этой типологией может быть разделена на группы.
Типы характера Э. Кречмера — классификация темпераментов на основе особенностей телосложения. Кречмер организовал собственную лабораторию конституциональной и трудовой психологи, которой руководил до своей смерти.
Э. Кречмер, обследовав 8 800 человек, выделил и описал по результатам тщательного обследования его пациентов, три наиболее часто встречающихся типа строения тела человека.
·Астенический, или лептосомный,
·Атлетический,
·Пикнический.
Астенический
Атлетический (греч. athletes – борец ) сильное развитие
скелета и мускулатуры- мускулистый,
крепкий, высокий, широкоплечий. Голова
плотная и высокая, сильная шея, а лицо
имеет обычно вытянутую яйцевидную
форму.
Пикнический (греч. pyknos – плотный) — толстый, тучный, средний рост, большой живот, короткая шея. Фронтальные очертания лица напоминают пятиугольник, само же лицо – широкое, мягкое, закругленное (интереснее, чем у атлетического типа и правильнее пикнического).
Диспластический тип — строение бесформенное, неправильное, непропорциональное. Был выделен как дополнительный.
Для доказательства связи между телесными и психическими особенностями людей указанные типы телосложения были соотнесены с тремя основными видами душевных расстройств.
Маниакально-депрессивный (циркулярный) психоз – периодическая смена гиперактивных, аффективно-приподнятых (маниакальных) состояний больного и состояния подавленности (депрессии), пассивности и уныния.
Шизофрения

Эпилепсия – приступы злобно-тоскливого настроения, повышенная раздражительность, вспыльчивость, эгоцентризм, чрезмерная педантичность.
Результаты соотнесения показали высокую корреляцию между этими типами психических заболеваний: циркулярного психоза с пикническим строением тела, шизофрении – с астеническим. Атлетики, которые менее других предрасположены к психическим заболеваниям, обнаруживают некоторую склонность к эпилепсии.
Шизотимик – астеническое телосложение. При расстройстве психики предрасположен к шизофрении. Замкнут, склонен к колебаниям эмоций от раздражения до сухости, упрям, малоподатлив к изменению установок и взглядов. С трудом приспосабливается к окружению, склонен к абстракции. Свойственны такие черты характера как аристократичность и тонкость чувств, склонность к отвлеченным размышлениям и отчужденность, холодность, эгоистичность и властность.
Циклотимик — пикническое телосложение. При нарушении психики предрасположен к маниакально-депрессивному психозу. Является противоположностью шизотимика. Эмоции легко колеблются между радостью и печалью, свободно контактирует с окружением, реалистичен во взглядах. Обладает веселостью, болтливостью, беспечностью, задушевностью, энергичностью, склонностью к юмору и легкому восприятию жизни.
Иксотимик – атлетическое телосложение. При
психических расстройствах предрасположен
к эпилепсии. Спокойный, мало впечатлительный,
со сдержанными жестами, мимикой. Невысокая
гибкость мышления, трудно приспосабливается
к перемене обстановки, мелочен.
Спокойный, мало впечатлительный,
со сдержанными жестами, мимикой. Невысокая
гибкость мышления, трудно приспосабливается
к перемене обстановки, мелочен.
Хотя типология Кречмера была построена умозрительным путем, она содержала в себе ряд жизненно правдивых наблюдений. Впоследствии действительно обнаружилось, что люди с определенным типом строения тела имеют склонность к заболеваниям, которые сопровождаются акцентуациями соответствующих черт характера. Более поздние классификации характеров строились в основном на описаниях этих акцентуаций. Одна из них принадлежит известному отечественному психиатру А.Е. Личко. Она построена на основе наблюдений за подростками.
Акцентуация
характера, по Личко, — это
чрезмерное усиление отдельных черт
характера, при котором наблюдаются не
выходящие за пределы нормы отклонения
в психологии и поведении человека,
граничащие с патологией. Такие акцентуации
как временные состояния психики чаще
всего наблюдаются в подростковом и
раннем юношеском возрасте. Объясняет
этот факт автор классификации так: «При
действии психогенных факторов,
адресующихся к «месту наименьшего
сопротивления», могут наступать
временные нарушения адаптации, отклонения
в поведении». При повзрослении ребенка
особенности его характера, проявившиеся
в детстве, остаются достаточно выраженными,
теряют свою остроту, но с возрастом
вновь могут проявиться отчетливо
(особенно если возникает заболевание).
Объясняет
этот факт автор классификации так: «При
действии психогенных факторов,
адресующихся к «месту наименьшего
сопротивления», могут наступать
временные нарушения адаптации, отклонения
в поведении». При повзрослении ребенка
особенности его характера, проявившиеся
в детстве, остаются достаточно выраженными,
теряют свою остроту, но с возрастом
вновь могут проявиться отчетливо
(особенно если возникает заболевание).
Классификация акцентуаций характеров у подростков, которую предложил А. Е. Личко, выглядит следующим образом:
Гипертимный
тип. Подростки этого
типа отличаются подвижностью,
общительностью, склонностью к озорству.
В происходящие вокруг события они всегда
вносят много шума, любят неспокойные
компании сверстников, при хороших общих
способностях они обнаруживают
неусидчивость, недостаточную
дисциплинированность, учатся неровно.
Настроение у них всегда хорошее,
приподнятое. С взрослыми, родителями,
педагогами у них нередко возникают
конфликты. Такие подростки имеют много
разнообразных увлечений, но эти увлечения,
как правило, поверхностны и быстро
проходят. Подростки гипертимного типа
зачастую переоценивают свои способности,
бывают слишком самоуверенными, стремятся
показать себя, прихвастнуть, произвести
на окружающих впечатление.
Такие подростки имеют много
разнообразных увлечений, но эти увлечения,
как правило, поверхностны и быстро
проходят. Подростки гипертимного типа
зачастую переоценивают свои способности,
бывают слишком самоуверенными, стремятся
показать себя, прихвастнуть, произвести
на окружающих впечатление.
Циклоидный тип. Он характеризуется повышенной раздражительностью и склонностью к апатии. Подростки данного типа предпочитают находиться дома одни вместо того, чтобы где-то быть со своими сверстниками. Они тяжело переживают даже незначительные неприятности, на замечания реагируют крайне раздражительно. Настроение у них периодически меняется от приподнятого до подавленного (отсюда название данного типа) с периодами примерно в две-три недели.
Лабильный
тип. Этот тип крайне
изменчив в настроении, причем оно
зачастую непредсказуемо. Поводы для
неожиданного изменения настроения
могут быть самые ничтожные, например,
кем-то случайно оброненное обидное
слово, чей-то неприветливый взгляд. Все
они “способны погрузиться в уныние и
мрачное расположение духа при отсутствии
каких-либо серьезных неприятностей и
неудач”. От сиюминутного настроения
этих подростков зависит многое в их
психологии и поведении. Соответственно
этому настроению настоящее и будущее
для них может расцвечиваться то радужными,
то мрачными красками. Такие подростки,
когда они находятся в подавленном
настроении, крайне нуждаются в помощи
и поддержке со стороны тех, кто мог бы
их настроение поправить, способен их
отвлечь, приободрить и развлечь.
Все
они “способны погрузиться в уныние и
мрачное расположение духа при отсутствии
каких-либо серьезных неприятностей и
неудач”. От сиюминутного настроения
этих подростков зависит многое в их
психологии и поведении. Соответственно
этому настроению настоящее и будущее
для них может расцвечиваться то радужными,
то мрачными красками. Такие подростки,
когда они находятся в подавленном
настроении, крайне нуждаются в помощи
и поддержке со стороны тех, кто мог бы
их настроение поправить, способен их
отвлечь, приободрить и развлечь.
Астеноневротический тип. Этот тип характеризуется повышенной мнительностью и капризностью, утомляемостью и раздражительностью. Особенно часто утомляемость проявляется при выполнении трудной умственной работы.
Сензитивный
тип. Ему свойственна
повышенная чувствительность ко всему:
к тому, что радует, и к тому, что огорчает
или пугает. Эти подростки не любят
больших компаний, слишком азартных,
подвижных, озорных игр. Они обычно
застенчивы и робки при посторонних
людях и поэтому часто производят
впечатление замкнутости. Открыты и
общительны они бывают только с теми,
кто им хорошо знаком, общению со
сверстниками предпочитают общение с
малышами и взрослыми. Они отличаются
послушанием и обнаруживают большую
привязанность к родителям. В юношеском
возрасте у таких подростков могут
возникать трудности адаптации к кругу
сверстников, а также “комплекс
неполноценности”. Вместе с тем у этих
же подростков довольно рано формируется
чувство долга, обнаруживаются высокие
моральные требования к себе и окружающим
людям. Недостатки в своих способностях
они часто компенсируют выбором сложных
видов деятельности и повышенным усердием.
Эти подростки разборчивы в нахождении
для себя друзей и приятелей, обнаруживают
большую привязанность в дружбе, обожают
друзей, которые старше их по возрасту.
Они обычно
застенчивы и робки при посторонних
людях и поэтому часто производят
впечатление замкнутости. Открыты и
общительны они бывают только с теми,
кто им хорошо знаком, общению со
сверстниками предпочитают общение с
малышами и взрослыми. Они отличаются
послушанием и обнаруживают большую
привязанность к родителям. В юношеском
возрасте у таких подростков могут
возникать трудности адаптации к кругу
сверстников, а также “комплекс
неполноценности”. Вместе с тем у этих
же подростков довольно рано формируется
чувство долга, обнаруживаются высокие
моральные требования к себе и окружающим
людям. Недостатки в своих способностях
они часто компенсируют выбором сложных
видов деятельности и повышенным усердием.
Эти подростки разборчивы в нахождении
для себя друзей и приятелей, обнаруживают
большую привязанность в дружбе, обожают
друзей, которые старше их по возрасту.
Психастенический
тип. Такие подростки
характеризуются ранним интеллектуальным
развитием, склонностью к размышлениям
и рассуждениям, к самоанализу и оценкам
поведения других людей. Такие подростки,
однако, нередко бывают больше сильны
на словах, чем в деле. Самоуверенность
у них сочетается с нерешительностью, а
безаппеляционность суждений — со
скоропалительными действиями,
предпринимаемых как раз в те моменты,
когда требуется осторожность и
осмотрительность.
Такие подростки,
однако, нередко бывают больше сильны
на словах, чем в деле. Самоуверенность
у них сочетается с нерешительностью, а
безаппеляционность суждений — со
скоропалительными действиями,
предпринимаемых как раз в те моменты,
когда требуется осторожность и
осмотрительность.
Шизоидный
тип. Его наиболее
существенной черта — замкнутость. Эти
подростки не очень тянутся к сверстникам,
предпочитают быть одни, находиться в
компании взрослых. “Душевное одиночество
даже не тяготит шизоидного подростка,
который живет в своем мире, своими
необычными для детей этого возраста
интересами”. Такие подростки нередко
демонстрируют внешнее безразличие к
другим людям, отсутствие к ним интереса.
Они плохо понимают состояния других
людей, их переживания, не умеют
сочувствовать. Их внутренний мир зачастую
наполнен различными фантазиями, особыми
увлечениями. Во внешнем проявлении
своих чувств они достаточно сдержаны,
не всегда понятны окружающим, прежде
всего для своих сверстников, которые
их, как правило, не очень любят.
Эпилептоидный тип. Эти подростки часто плачут, изводят окружающих, особенно в раннем детстве. “ Такие дети, — любят мучить животных, избивать и дразнить младших и слабых, издеваться над беспомощными и неспособными дать отпор. В детской компании они претендуют не просто на лидерство, а на роль властелина. Их типичные черты – жестокость, властность, себялюбие. В группе детей, которыми они управляют, такие подростки устанавливают свои жесткие, почти террористические порядки, причем их личная власть в таких группах держится в основном на добровольной покорности других детей или на страхе. В условиях жесткого дисциплинарного режима они чувствуют себя нередко на высоте, стараются угождать начальству, добиваться определенных преимуществ перед сверстниками, получить власть, установить диктат над окружающими.
Истероидный
тип. Главная черта этого
типа — эгоцентризм, жажда постоянного
внимания к своей особе. У подростков
данного типа выражена склонность к
театральности, позерству, рисовке. Такие
дети с трудом выносят, когда в их
присутствии хвалят их товарища, когда
другим уделяют больше внимания, чем им
самим. “Желание привлекать к себе взоры,
слушать восторги и похвалы становиться
для них насущной потребностью”. Для
таких подростков характерны претензии
на исключительное положение среди
сверстников, и чтобы оказать влияние
на окружающих, привлечь к себе внимание,
они часто выступают в группах в роли
зачинщиков и заводил. Вместе с тем,
будучи неспособными выступить как
настоящие лидеры и организаторы дела,
завоевать себе неформальный авторитет,
они часто и быстро терпят фиаско.
Такие
дети с трудом выносят, когда в их
присутствии хвалят их товарища, когда
другим уделяют больше внимания, чем им
самим. “Желание привлекать к себе взоры,
слушать восторги и похвалы становиться
для них насущной потребностью”. Для
таких подростков характерны претензии
на исключительное положение среди
сверстников, и чтобы оказать влияние
на окружающих, привлечь к себе внимание,
они часто выступают в группах в роли
зачинщиков и заводил. Вместе с тем,
будучи неспособными выступить как
настоящие лидеры и организаторы дела,
завоевать себе неформальный авторитет,
они часто и быстро терпят фиаско.
Неустойчивый тип. Его иногда неверно характеризуют как слабовольный, плывущий по течению. Подростки данного типа обнаруживают повышенную склонность и тягу к развлечениям, причем без разбора, а также к безделью и праздности. У них отсутствуют какие-либо серьезные, в том числе профессиональные интересы, они почти не думают о своем будущем.
Конформный
тип.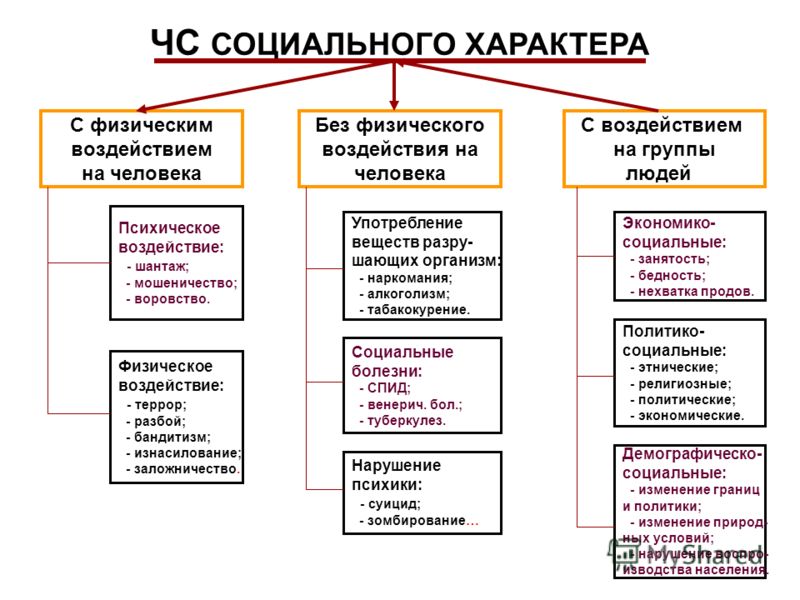 Данный тип демонстрирует
бездумное, некритическое, а часто
конъюнктурное подчинение любым
авторитетам, большинству в группе. Такие
подростки обычно склонны к морализаторству
и консерватизму, а их главное жизненное
кредо — “быть, как все”. Это тип
приспособленца, который ради своих
собственных интересов готов предать
товарища, покинуть его в трудную минуту,
но, что бы он ни совершил, он всегда
найдет оправдание своему поступку,
причем нередко не одно.
Данный тип демонстрирует
бездумное, некритическое, а часто
конъюнктурное подчинение любым
авторитетам, большинству в группе. Такие
подростки обычно склонны к морализаторству
и консерватизму, а их главное жизненное
кредо — “быть, как все”. Это тип
приспособленца, который ради своих
собственных интересов готов предать
товарища, покинуть его в трудную минуту,
но, что бы он ни совершил, он всегда
найдет оправдание своему поступку,
причем нередко не одно.
Классификация А.Е. Личко построена на основе результатов наблюдений и их обобщения и по современным представлениям не является научно точной. Кроме того возникает вопрос, что делать с теми людьми, которые не вписываются в классификацию и не могут быть отнесены однозначно ни к одному из предложенных типов? Это довольно значительная часть – до половины всех людей.
«Понятие и структура правовой информации» (Материал подготовлен специалистами КонсультантПлюс) / КонсультантПлюс
ПОНЯТИЕ И СТРУКТУРА ПРАВОВОЙ ИНФОРМАЦИИ
(материалы подготовлены специалистами
АО «Консультант Плюс»)
КонсультантПлюс: примечание.
Условия и порядок вступления в силу федеральных нормативных правовых актов см. справочную информацию
Условия и порядок вступления в силу международных договоров Российской Федерации. Порядок их опубликования см. справочную информацию
В сфере юридической деятельности и правовой информатизации широко применяется термин «правовая информация». К правовой информации относятся, прежде всего, правовые акты, а также вся информация, которая связана с правом: материалы подготовки законопроектов и других нормативных правовых актов, их обсуждения и принятия, учета и упорядочения, толкования и реализации правовых норм, изучения практики их применения. В правовую информацию включаются также материалы о правовом образовании и разработке научных концепций развития права.
Исходя из сказанного, правовую информацию можно определить как массив правовых актов и тесно связанных с ними справочных, нормативно — технических и научных материалов, охватывающих все сферы правовой деятельности.
Правовую информацию, в зависимости от того, кто является ее «автором», то есть от кого она исходит, и на что направлена, можно разделить на три большие группы: официальная правовая информация, информация индивидуально — правового характера, имеющая юридическое значение, и неофициальная правовая информация.
Официальная правовая информация — это информация, исходящая от полномочных государственных органов, имеющая юридическое значение и направленная на регулирование общественных отношений.
Информация индивидуально — правового характера, имеющая юридическое значение, — это информация, исходящая от различных субъектов права, не имеющих властных полномочий, и направленная на создание (изменение, прекращение) конкретных правоотношений.
Неофициальная правовая информация — это материалы и сведения о законодательстве и практике его осуществления (применения), не влекущие правовых последствий и обеспечивающие эффективную реализацию правовых норм.
Рассмотрим названные группы более подробно.
Открыть полный текст документа
Боль в почках — основные причины, классификация характера боли, диагностика заболеваний почек
Акция! Скидка 20% на первичный прием врача для новых пациентов клиники по промокоду «ПЕРВЫЙ20».
Одна из самых распространенных жалоб на приеме врача-уролога — боль в почках. Однако точно определить беспокоящий орган можно только с помощью тщательной диагностики.
Одна из самых распространенных жалоб на приеме врача-уролога — боль в почках. Однако точно определить беспокоящий орган можно только с помощью тщательной диагностики. Приносить дискомфорт в области поясницы и по бокам нижней части спины могут не только сами почки, но и их ближайшие «соседи»: селезенка, печень, органы мочеполовой системы и брюшной полости, а также заболевания опорно-двигательного аппарата. Далеко не всем известно, что чаще всего почки «болят» в нижнем подреберье (они располагаются чуть выше поясницы).
Заболевания почек, вызывающие боли в поясничной области:
- пиелонефрит
Воспалительное бактериальное заболевание, которое чаще всего возникает у детей до 7-и лет, девушек от 18-и до 30-и лет, а также у пожилых мужчин. Оно сопровождается болями ноющего и тянущего характера, высокой температурой, головными болями. Развивается очень стремительно: первые симптомы становятся ощутимы уже через пару часов. - гломерулонефрит
Почки при заболевании поражаются сразу с двух сторон. Нарушается фильтрационная функция. Оно может быть вызвано аномалиями строения почек, инфекциями и токсикациями, а также онкологией. Человек испытывает сильные и режущие боли, повышение АД, сокращение мочеиспускания, недомогание, слабость, снижение аппетита, работоспособности. - почечная недостаточность
Серьезное заболевание, которое приводит к частичной или полной утрате способности почек образовывать мочу. Это может привести к поражению практически всех органов и систем организма. Данная патология возникает как следствие нарушения гемодинамики почек, сильной интоксикации или инфекции, острых периодов почечных заболеваний, травматических состояний. Основной симптом: резкое сокращение количества мочи. Если заболевание было зафиксировано на поздней стадии, назначается гемодиализ и подготовка к пересадке почки. - нефроптоз (смещение почки)
Причин возникновения патологии много: резкая потеря веса, травмы в области живота, аномальное развитие органа, состояния после беременности. Болевой симптом здесь очень сильный, его не удается устранить при помощи анальгезирующих средств. Боль в большинстве случаев усиливается при принятии вертикального положения, ближе ко второй половине дня. - злокачественные новообразования в почках (рак органа)
На ранней стадии заболевание обнаружить сложно, так как оно протекает бессимптомно. В развитии рак проявляется кровяными выделениями в моче, тупой постоянной болью в разных частях живота, скачками температуры, потерей веса. Для того, чтобы избежать проблему, необходимо регулярно проходить профилактические осмотры. - доброкачественные новообразования в почках (гамартомы, аденомы)
Течение на ранней стадии проходит бессимптомно. В развитии возникают тянущие боли и дискомфорт в области поясницы. Лечение осуществляется хирургическим вмешательством. - мочекаменная болезнь
При образовании камней человек испытывает очень сильные боли, так как при движении объект двигается и повреждает ткани. Данный вид боли называют почечной коликой. Она начинается приступообразно и может «выстрелить» в любой области поясницы, а также нижней части живота и паховой области. - почечные кисты
Патология возникает в зрелом возрасте, но также встречается ее врожденный или приобретенный вид. Большие кисты могут вызывать боль в поясничной области, появление крови в моче, повышение АД.
Определить причину болезненности в области почек без тщательного обследования невозможно. Не менее опасно пытаться лечить симптом самостоятельно.
Любая, даже незначительная патология почек может перерасти в глобальную проблему. Неправильное лечение или его отсутствие способствуют переходу заболевания в хроническую форму.
Нередко присоединяются инфекции, поражаются другие органы и системы.
Отсутствие надлежащей терапии может привести к развитию тяжелых патологий. Среди них наиболее распространенными считаются сердечная недостаточность, энцефалопатия, отек легких и головного мозга. В тяжелых случаях возможны развитие сепсиса, уремическая кома и смерть пациента.
Избежать осложнений и избавиться от болей в области почек довольно просто. Не откладывайте обращение в клинику. Выберите хорошего врача, который поможет выяснить причину дискомфорта и подобрать методы лечения. Приходите на прием к специалистам Кутузовского лечебно-диагностического центра. Мы поможем вам справиться с проблемой и избежать появления серьезных патологий.
Необходимо немедленно обратиться к врачу, если вы замечаете:
- вы чувствуете боли в поясничной области (как отдельно с каждой стороны, так и одновременно с двух сторон)
- дискомфорт в области верхней части поясницы в утренние часы
- боль в пояснице, сопровождающуюся ознобом и повышением температуры тела
- что количество мочеиспусканий, а также самой мочи резко снизились
- частое мочеиспускание небольшим количеством мочи
- изменение консистенции мочи (появление замутнения, крови, мелких камней и песка)
- дискомфорт при мочеиспускании (жжение, боли)
Для диагностики заболеваний почек может потребоваться немало исследований. Чаще всего больному человеку неудобно посещать разные медицинские центры в поисках такой возможности. Кутузовский лечебно-диагностический центр предоставляет своим пациентам возможность пройти полноценное обследование в одном месте. Вам не придется тратить время на ожидание или выстаивать длительные очереди. Все процедуры проводятся по предварительной записи в точно установленное время.
У нас есть все необходимое оборудование для проведения исследований любой сложности. Для диагностики применяются высокоточные приборы, что позволяет избежать ошибочных результатов и подобрать максимально эффективную схему лечения. Ваше здоровье и комфорт для нас приоритетны.
Приходите на прием в клинику, чтобы вернуть себе радость жизни без боли.
Для постановки точного диагноза врач-уролог может назначить следующие диагностические методы:
- лабораторные исследования (общий анализ крови и мочи; биохимическое исследование, бактериологические исследования)
- УЗИ почек
- КТ почек при подозрении на МКБ для исключения новообразований
Если вы хотите до приема к специалисту самостоятельно снизить интенсивность боли, вам может помочь соблюдение диеты: исключите из рациона соленую, острую и копченую пищу, пейте отвары лечебных трав. Держите тело, а в особенности область поясницы и ноги, в тепле, соблюдайте постельный режим.
Помните, что любое заболевание, выявленное на ранней стадии, легче поддается лечению и экономит ваши силы и средства. При появлении первых симптомов заболеваний почек при первой же возможности обратитесь к врачу-урологу или пройти одну из комплексных программ обследования.
В нашем центре вы можете записаться к хорошим специалистам:
Содержание данной статьи проверено и подтверждено на соответствие медицинским стандартам врачом-урологом Горовым Дмитрием Владиславовичем.
Цены
|
Название |
Цена |
|---|---|
| Прием (осмотр, консультация) врача-терапевта первичный | 2 200 ₽ |
| Прием (осмотр, консультация) врача-терапевта повторный | 1 900 ₽ |
Публикацию проверил:
|
№№ |
Наименование вида (типа) |
Код |
|
1 |
Транспортные происшествия, в т.ч. |
01 |
|
1.1. |
на железнодорожном транспорте |
01а |
|
1.2. |
на водном транспорте |
01б |
|
1.3. |
на воздушном транспорте |
01в |
|
1.4. |
на наземном транспорте |
01 г |
|
происшедшие: |
||
|
1.5. |
В пути на работу (с работы) на транспортном средстве работодателя (или сторонней организации на основании договора с работодателем) |
011 |
|
1.6. |
Во время служебных поездок (в т.ч. в пути следования в служебную командировку) на общественном транспорте |
012 |
|
1.7. |
Во время служебных поездок на личном транспортном средстве |
013 |
|
1.8. |
Во время пешеходного передвижения к месту работы |
014 |
|
2. |
Падение пострадавшего с высоты, в т.ч. |
02 |
|
2.1. |
Падение на ровной поверхности одного уровня, включая: |
021 |
|
2.1.1. |
Падение на скользкой поверхности, в том числе покрытой снегом или льдом |
0211 |
|
2.1.2. |
Падение на поверхности одного уровня в результате проскальзывания, ложного шага или спотыкания |
0212 |
|
2.2. |
Падение при разности уровней высот (с деревьев, мебели, со ступеней, приставных лестниц, строительных лесов, зданий, оборудования, транспортных средств и т.д.) и на глубину (в шахты, ямы, рытвины и др.) |
022 |
|
3. |
Падение, обрушение, обвалы предметов, материалов, земли и пр., в т.ч. |
03 |
|
3.1. |
Обрушение и осыпь земляных масс, скал, камней, снега и др. |
031 |
|
3.2. |
Обвалы зданий, стен, строительных лесов, лестниц, складированных товаров и др. |
032 |
|
3.3. |
Удары падающими предметами и деталями (включая их осколки и частицы) при работе (обращении) с ними |
033 |
|
3.4. |
Удары случайными падающими предметами |
034 |
|
4. |
Воздействие движущихся, разлетающихся, вращающихся предметов, деталей, машин и т.д., в т.ч. |
04 |
|
4.1. |
Контактные удары (ушибы) при столкновении с движущимися предметами, деталями и машинами (за исключением случаев падения предметов и деталей), в том числе в результате взрыва |
041 |
|
4.2. |
Контактные удары (ушибы) при столкновении с неподвижными предметами, деталями и машинами, в том числе в результате взрыва |
042 |
|
4.3. |
Защемление между неподвижными и движущимися предметами, деталями и машинами (или между ними) |
043 |
|
4.4. |
Защемление между движущимися предметами, деталями и машинами (за исключением летящих или падающих предметов, деталей и машин) |
044 |
|
4.5. |
Прочие контакты (столкновения) с предметами, деталями и машинами (за исключением ударов (ушибов) от падающих предметов) |
045 |
|
5. |
Попадание инородного тела |
05 |
|
5.1. |
Через естественные отверстия в организме |
051 |
|
5.2. |
Через кожу (край или обломок другого предмета, заноза и т.п.) |
052 |
|
5.3. |
Вдыхание и заглатывание пищи либо инородного предмета, приводящее к закупорке дыхательных путей |
053 |
|
6. |
Физические перегрузки и перенапряжения |
06 |
|
6.1. |
Чрезмерные физические усилия при подъеме предметов и деталей |
061 |
|
6.2. |
Чрезмерные физические усилия при толкании или демонтировании предметов и деталей |
062 |
|
6.3. |
Чрезмерные физические усилия при переноске или бросании предметов |
063 |
|
7. |
Воздействие электрического тока, в т.ч. |
07 |
|
7.1. |
Природного электричества (молнии) |
071 |
|
8. |
Воздействие излучений (ионизирующих и неионизирующих) |
08 |
|
9. |
Воздействие экстремальных температур и других природных факторов |
09 |
|
9.1. |
Воздействие повышенной температуры воздуха окружающей или рабочей среды |
091 |
|
9.2. |
Воздействие пониженной температуры воздуха окружающей или рабочей среды |
092 |
|
9.3. |
Соприкосновение с горячими и раскаленными частями оборудования, предметами или материалами, включая воздействие пара и горячей воды |
093 |
|
9.4. |
Соприкосновение с чрезмерно холодными частями оборудования, предметами и материалами |
094 |
|
9.5. |
Воздействие высокого или низкого атмосферного давления |
095 |
|
10. |
Воздействие дыма, огня и пламени |
10 |
|
10.1. |
Воздействие неконтролируемого огня (пожара) в здании или сооружении |
101 |
|
10.2. |
Воздействие неконтролируемого огня (пожара) вне здания или сооружения, в том числе пламени от костра |
102 |
|
10.3. |
Воздействие контролируемого огня в здании или сооружении (огня в печи, камине и т.д.) |
103 |
|
10.4. |
Повреждения при возгорании легковоспламеняющихся веществ и одежды |
104 |
|
11. |
Воздействие вредных веществ |
11 |
|
11.1. |
Воздействие вредных веществ путем вдыхания, попадания внутрь или абсорбции в результате неправильного их применения или обращения с ними |
111 |
|
11.2. |
Воздействие вредных веществ (в том числе алкоголя, наркотических, токсических или иных психотропных средств) в результате передозировки или злоупотребления при их использовании |
112 |
|
12. |
Повреждения в результате нервно-психологических нагрузок и временных лишений (длительное отсутствие пиши, воды и т.д.) |
12 |
|
13. |
Повреждения в результате контакта с растениями, животными, насекомыми и пресмыкающимися |
13 |
|
13.1. |
Укусы, удары и другие повреждения, нанесенные животными и пресмыкающимися |
131 |
|
13.2. |
Укусы и ужаливания ядовитых животных, насекомых и пресмыкающихся |
132 |
|
13.3. |
Повреждения в результате контакта с колючками и шипами колючих и ядовитых растений |
133 |
|
14. |
Утопление и погружение в воду, в т.ч. |
14 |
|
14.1. |
Во время нахождения в естественном или искусственном водоеме |
141 |
|
14.2. |
В результате падения в естественный или искусственный водоем |
142 |
|
15. |
Повреждения в результате противоправных действий других лиц |
15 |
|
16. |
Повреждения в результате преднамеренных действий по причинению вреда собственному здоровью (самоповреждения и самоубийства) |
16 |
|
17. |
Повреждения при чрезвычайных ситуациях природного, техногенного, криминогенного и иного характера, в т.ч. |
17 |
|
17.1. |
В результате землетрясений, извержений вулканов, снежных обвалов, оползней и подвижек грунта, шторма, наводнения и др. |
171 |
|
17.2. |
В результате аварий, взрывов и катастроф техногенного характера |
172 |
|
17.3. |
В результате взрывов и разрушений криминогенного характера |
173 |
|
17.4. |
При ликвидации последствий стихийных бедствий, катастроф и других чрезвычайных ситуаций природного, техногенного, криминогенного и иного характера |
174 |
|
18. |
Воздействие других неклассифицированных травмирующих факторов |
18 |
Классификация речевых нарушений
Нарушения речи как у взрослых, так и у детей могут быть следствием «неправильного формирования» тех, или иных компонентов психической функции в детском возрасте либо нарушением работы уже сформированной речевой системы вследствие патогенного воздействия на нервную систему человека в более зрелом возрасте.
В зависимости от времени возникновения дисфункции, ее характера и интенсивности изменяются симптомы и качество речевых нарушений. Ниже приведены две наиболее распространенные классификации речевых нарушений, используемые в отечественной системе здравоохранения и образования.
Психолого-педагогическая классификация
Далее приведем пример еще одной классификации речевых нарушений (психолого- педагогическую), разработанную для комплектации детских речевых групп на основании симптома нарушения речи:
Нарушение средств общения
- Фонетико-фонематическое недоразвитие речи (ФФНР)
- Общее недоразвитие речи (ОНР), алалия, афазия
Нарушение применения средств общения
Клинико-педагогическая классификация речевых нарушений
Нарушения устной речи
- Дислалия – нарушение звукопроизношения при сохранном слухе и интеллекте
- Ринолалия (носовая речь) — нарушения звукопроизношения и тембра голоса из-за анатомического дефекта периферического отдела речевого анализатора
- Дизартрия – нарушение звукопроизношения и просодической (интонация, мелодика, ритм, высота) стороны речи при недостаточной иннервации мышц, обеспечивающих речевую функцию
- Дисфония – нарушение голоса (воспаление голосовых связок – ларингиты)
- Заикание – нарушение темпа и ритма речи из-за судорог мышц речевого аппарата
- Алалия – отсутствие или недоразвитие речи из-за органического повреждения мозга до 3-х летнего возраста
- Афазия – отсутствие или распад речи в результате органического повреждения головного мозга после 3-х лет
- Тахилалия – патологически ускоренный темп речи, повтор и пропуск слогов при сохранных грамматическом, лексическом и фонетическом аспектах речи. В чистом виде встречается редко – чаще в составе других речевых нарушений
- Брадилалия – патологически медленный темп речи вследствие поражения головного мозга. Чаще встречается в составе других речевых нарушений
Нарушения письменной речи
- Дисграфия – расстройство письменной речи, проявляющееся в специфических часто повторяющихся ошибках
- Дислексия – недостаточность чтения. Ошибки восприятия букв
- Дизорфография – невозможность автоматического применения на практике правил языка
В приведенной выше классификации расстройства устной речи разграничены в соответствии с органическими нарушениями, являющимися причинами этих речевых расстройств. Данные диагнозы ранее традиционно выставлялись врачами (неврологами), а не логопедами и психологами, несмотря на частую недостаточную компетенцию врачей в диагностике речевых нарушений. В настоящее время ситуация меняется и появляется все больше медицинских учреждений, где подобный речевой диагноз выставляется непосредственно речевым специалистом – логопедом, нейропсихологом.
Классификация отклонений и акцентуаций характера
Стремление расширить исследование индивидуальностей человека порождает интерес к ее пограничным формам, промежуточным между нормой и патологией, т.е. к материалу психиатрии. Для описания этих форм существует два основных понятия – психопатии (П.Б.Ганнушкин) и акцентуации личности и характера (К.Леонгард, А.Е. Личко).
Психопатии – это аномалии характера, которые а) определяют весь психический облик человека, б) не подвергаются значительным изменениям при его жизни, в) мешают ему правильно адаптироваться в окружающей социальной среде. Акцентуации представляют собой крайние варианты нормы, при которых отдельные черты характера чрезмерно усилены (акцентуированы), вследствие чего человек болезненно уязвим по отношению к одним воздействиям, при относительной устойчивости – к другим.
Напомним, что отклонения и акцентуации характера рассматриваются психиатрами как резкие, обостренные проявления черт, присущих и нормальным людям. Поэтому не следует удивляться, если в описаниях психопатий кто-то узнает свои собственные черты, причем нередко не в одной, а сразу в нескольких различных группах.
Эмпирическое разделение психопатий на группы, так же как выделение типов акцентуаций, не имеет единого критерия. Главным из них остается содержательное сходство индивидуальных наборов черт с определенными психическими заболеваниями, не только циркулярным психозом или шизофренией, но и другими – паранойей, эпилепсией, истерией и т.д. Группы же циклоидов и шизоидов – сохраняются как отдельные, а иногда и как объединяющие несколько типовых отклонений. Рассмотрим кратко основные группы психопатий и типы акцентуаций, начиная с тех, которые близки к циклоидным и шизоидным (не повторяя, разумеется, описания последних). Заметим, что психопатические черты (по П.Б.Ганнушкину) характеризуют, прежде всего, взрослых людей, типы акцентуаций (по А.Е.Личко) – подростков, т.е. «переломный» возраст для становления характера и личности.
1. Конституционально-возбужденные (гипертимный тип) – люди, которые характеризуются постоянно приподнятыми, хорошим настроением, т.е. одним из двух крайних состояний циркулярного психоза. Жизнерадостные, общительные, приветливые, остроумные, они могут производить на окружающих самое благоприятное впечатление. Однако при резко выраженных формах симптоматика этой группы включает и характерные отрицательные черты. Стремление к лидерству (чаще – неформальному) делает конституционально-возбужденных заводилами шумных компаний, инициаторами масштабных начинаний, которые редко доводятся до конца. Энергичный гипертимный подросток обычно неусидчив, не систематичен в своих занятиях и обладает лишь поверхностными знаниями, интересами, при хороших способностях он, как правило, плохо успевает в школе, испытывая к тому же большие трудности при соблюдении дисциплинарных норм. В жизни конституционально-возбужденных возможны блестящие взлеты, хотя в деловых вопросах эти люди крайне ненадежны, и резкие падения, которые, впрочем, легко переносятся; гипертомики остаются находчивыми и изобретательными в любых затруднительных положениях. Их деятельная направленность может иметь, наконец, и асоциальные проявления (аферы, мошенничество и пр.).
2. Конституционально-депрессивные характеризуются вторым крайним состоянием циркулярного психоза – постоянно пониженным настроением, подавленностью, которые, как правило, определяют их общее самочувствие. Любая работа требует от них большого напряжения и поэтому быстро утомляет. Именно этих людей называют «тугодумами», несмотря на то, что их интеллектуальные возможности могут быть достаточно высокими. Трудности в общении у конституционально-депрессивных могут, с одной стороны, компенсироваться показным весельем на людях, а с другой – приводить к полной асоциальности, безразличию к окружающим. Показательным признаком данной группы психопатий являются постоянные самообвинения, чувство вины и собственной недостаточности, возникающее даже при незначительных проступках. В подростковом возрасте стабильных отклонений подобного рода обычно не выделяют, хотя по описаниям здесь достаточно близок им чувствительный, или сензитивный тип акцентуаций. Сензитивные подростки отличаются чрезмерной впечатлительностью, они пугливы, капризны (но беззлобны), до слез чувствительны к возможным насмешкам сверстников. В учебе старательны, но боятся любых проверок. Впрочем, подчас они стремятся изменить и даже сверхкомпенсировать свою «неполноценность», причем именно в тех сферах жизни (например, в общении), неудачи в которых переживаются ими особенно остро.
3. Лабильные (эмотивно-лабильные, реактивно-лабильные) отличаются изменчивостью настроения, его резкими перепадами по самым ничтожным поводам. Похвала и порицание, любые внешние события вызывают немедленные эмоциональные реакции, от чрезмерной радости до беспочвенного уныния. У них бывают «хорошие» и «плохие» дни, что нередко зависит от капризов погоды. Лабильных часто считают людьми легкомысленными, но это не так: они способны на глубокие постоянные чувства к родным, близким друзьям, любимому человеку.
Понятно, что к описанным типам примыкают и собственно циклоиды (в классификации П.Б.Ганнушкина все они объединяются в общую группу психопатий под данным названием). Шизоиды, как отдельная группа, определяются аутичностью в эмоциональной и познавательной сферах. Близкой к шизоидам по телесной конституции является группа астеников: речь идет об именно «психической астении», которую отличают два основных признака – раздражительность и утомляемость.
4. Неврастеники (астено-невротический тип) характеризуются чрезмерной возбудимостью, а также мнительностью в отношении своего здоровья. Частые болезненные ощущения соматических нарушений (сердца, органов пищеварения и др.) и повышенное внимание к ним отражают склонность к ипохондрии. Постоянные посетители врачебных кабинетов (подчас различных и сразу нескольких), неврастеники внушаемы и дают сильные психогенные реакции на любой возможный диагноз. Социальная дезадаптация неврастеников проявляется в смущении и робости, которые они могут пытаться скрыть под маской внешней развязности. Подростки астено-невротического типа обычно вспыльчивы, однако приступы бурной раздражительности быстро сменяются раскаянием. Часто они намеренно ищут собеседников, но в процессе общения – быстро устают.
5. Психастеники – другая разновидность астенической группы психопатий и отдельный тип акцентуаций (у подростков). Они отличаются чрезмерной нерешительностью, доходящей о полной неспособности принимать какие-либо решения. При этом длительное ожидание опасных событий в будущем (здоровье и участь близких, собственные неудачи и т.п.) травмируют их сильнее, чем события уже происшедшие. Постоянная тревога при необходимости выбора (даже в мелочах) компенсируется либо уходом в воображение, излишней мечтательностью и верой в приметы, либо – изобретением всякого рода ритуалов, выполнение которых «необходимо» для их осуществления. По тем же причинам психастеники часто склонны к самоанализу и рассуждениям, обстоятельным, но бесплодным.
6. Параноидная группа психопатий имеет своим главным признаком – склонность к образованию сверхценных идей. Особое (объективно неверное, завышенное) значение придает параноид собственной личности. Других людей он оценивает по отношению к своим высказываниям, мыслям, поступкам. Мышление параноидных психопатов характеризуется односторонностью, и понятное здесь резонерство (по сравнению, скажем, с шизоидами) не отличается богатством ассоциаций. В общении они недоверчивы, обидчивы, нередко мстительны и злопамятны. Неадекватны их реакции на успех: в житейских невзгодах (которые нередко возникают по собственной вине) они далеки от разочарования и остаются крайне некритичными к себе. Среди параноидов встречаются и фанатики (так их назвал П.Б.Ганнушкин), которые способны сделать конкретный вопрос (например, об определенной пищевой диете) едва ли не принципом мироздания и критерием моральных оценок. Интересно, что в подростковых типах акцентуаций характера аналог данного вида психопатий отсутствует.
7. Эпилептоидная группа психопатий (и соответствующий тип акцентуаций) характеризуется сочетанием трех основных признаков: а) крайней раздражительностью, вплоть до ярости; б) приступами аффективных расстройств (тоски, гнева, страха) и в) моральными дефектами (асоциальными установками). Впрочем, последняя особенность может быть скрытой и обнаруживаться, напротив, в преувеличенной гипер-социальности, в подчеркнуто строгом соблюдении моральных норм, доходящем до ханжества. Эпилептоиды обычно очень активны, напряженно деятельны, настойчивы и даже упрямы, в общении – эгоистичны, нетерпеливы и крайне нетерпимы к мнениям других, резко реагируя на любые возражения. Характерная для них страстность и любовь к сильным ощущениям нередко выражается в отсутствии чувства меры (в азартных играх, коллекционировании, обогащении и т.д.). Их мышление – инертно, вязко, нечувствительно к новому опыту. Эпилептоидные подростки отличаются аккуратностью, бережливостью, которая может переходить в жадность, ревность, требовательность при разделении как материальных благ, так и дружеского участия. В компаниях они стремятся к авторитарному лидерству, к власти, но если это не удается, жестокие к слабому, они заискивают перед сильными. Охотно упражняют свою физическую силу, тренируют ручные и др. навыки, предпочитая заниматься ими не в коллективе, а наедине и получая при этом особое чувственное удовольствие.
8. Истероиды (истероидный тип) отличаются, прежде всего, желанием обращать на себя постоянное внимание, для чего часто представляют себя и других намеренно неверно. Требующие признания, они любой ценой хотят казаться значительнее (как лучше, так и хуже), чем на самом деле. Это стремление выражается в эксцентричных поступках, оригинальных идеях, в рассказах о своих особых редко встречаемых (но объективно мнимых) заболеваниях, а также в демонстративных обмороках, припадках, попытках к суициду (как правило, «неудачных»). Их привязанности, интересы, чувства – поверхностны и во многом зависят от окружающих, так как рассчитаны на внешний эффект. Истероидные акцентуации часто встречаются у подростков, сопровождаясь инфантильностью и нередко смешиваясь с другими типами, например, гипертимным. Особую группу истероидов составляют (по П.Б. Ганнушкину) так называемые патологические лгуны, которые стремятся привлечь к себе внимание своей неумеренной фантазией.
9. Неустойчивые (неустойчивый тип) характеризуются полной реактивностью в поведении, которое целиком определяется внешней социальной средой. Не имея глубоких интересов и привязанностей, они скучают в одиночестве, но хорошо чувствуют себя в компаниях, умеют поддержать беседу. Неустойчивые легко внушаемы, в манере поведения часто берут пример с наиболее ярких своих приятелей. В работе они несамостоятельны, хотя и способны увлечься ею (но ненадолго), беспорядочны, неаккуратны и, наконец, ленивы. Неустойчивые особо склонны к приему наркотических и подобных им средств, под действием которых становятся, как правило, эгоистичными и жестокими, а по его окончании – горько раскаиваются, сетуя на случайные внешние обстоятельства. Слабоволие является основной чертой и неустойчивых подростков, оно делает их равнодушными к учебе, к любому, требующему усилий труду, к собственному будущему и требует постоянной, достаточно жесткой опеки.
10. Конституционально-глупые (конформный тип) – под этим названием сгруппированы психопатические индивиды с выраженной умственной недостаточностью. Однако это не единственный (а подчас и не главный) отличительный признак этой группы людей, которые, кстати, могут хорошо успевать в школе, средней и даже высшей, благодаря механическому запоминанию материала. Более точной является вторая ее характеристика – чрезмерная конформность, а именно – почти полное отсутствие собственной инициативы. Представители этой группы обычно ориентируются на свое непосредственное социальное окружение, однако не ищут в нем наиболее ярких примеров для подражания (как неустойчивые психопаты), но стремятся думать, действовать, «быть – как все». Неумение противостоять любому внешнему влиянию, внушаемость и консерватизм делают их ревностными слугами общепринятых мнений, дежурной моды и др., способными выражать банальные истины в напыщенной (нередко – усложненной) форме и с самым торжественным видом. Умелое и точное следование шаблону (например, модному фасону одежды или авторитетному, но, как правило, частному, лишенному констекста, предписанию) сопровождается ощущением собственной значительности, доходящим до горделивого самодовольства. Судьба подростков конформного типа определяется их средой, они могут становиться хорошими работниками (если их задания четко регламентированы), а попав в дурную компанию – втянуты в асоциальные действия из групповой «солидарности».
Терапевтическая работа с людьми, обладающими отклонениями или акцентуациями характера, направлена, прежде всего, на их социальную адаптацию. Основное значение приобретает, конечно, знание «уязвимых мест» этих людей. Такие «места», как мы видели, могут быть связаны с влиянием внешних условий или их внутренним тревожным ожиданием (мнительностью). К первым относится, например, отсутствие социальной поддержки со стороны ближайшего окружения (у сензитивов и конформных), ко второму -беспокойство о собственном здоровье (у неврастеников), в том числе – опасение «заразиться» (у эпилептоидов), или страх перед будущим – своим и своих близких (у психоастеников). Знание ситуаций, приводящим к болезненным расстройствам, позволяет моделировать благоприятные условия для нормальной жизни этих людей или их окружения. Так, если эти расстройства чисто реактивного характера, то нужно создать атмосферу доброжелательного, устойчивого социального отношения (для сензитивов и лабильных), допускающую смену основной деятельности (для гипертимиков), или, напротив, ее нормативную регламентацию (для неустойчивых). Если же отклонения и акцентуации характера имеют активные «природные» проявления (как, например, у параноидов и эпилептоидов), можно предупредить их нежелательные социальные последствия с помощью соответствующих фармакологических воздействий.
Завершая характеристику описательного подхода к анализу индивидуальности, можно выделить три его основные особенности.
Первая из них состоит в том, что реальность различных типов индивидуальности раскрывается перед исследователем (и понимается им) как непосредственная природная данность, существующая как бы «сама по себе». Не только потому, что она «живет» по своим законам, неизвестным эмпирику и независимым от него (хотя, быть может, именно поэтому индивидуальных типов характера достаточно много). Эта реальность представляется независимой от конкретного человека, которому дан тот или иной характер. Такие теоретические допущения имеют закономерные следствия в организации индивидуальной терапии. Терапевт (да и сам пациент) пытаются либо приспособиться к неподвластной им натуре, подбирая адекватные внешние условия, либо изменить ее, но также извне – путем внепсихических (например, фармакологических) влияний. Заметим, что при этом исследователь остается лишь участливым наблюдателем и выделяемые им эмпирические закономерности не имеют отношения к нему самому, и их последствия – происходят не с ним.
Вторая особенность касается представления о нормальной индивидуальности, т.е. о том, от чего отклоняется характер и с чем он сравнивается. В данном случае «норма» может быть получена путем статистического усреднения всех названных индивидуальных различий и является совершенно условным понятием. Действительно, поскольку совместить, найти промежуточный образец для столь многообразных индивидуальных отклонений, акцентуаций не представляется возможным, постольку так называемого «нормального характера» (по утверждению П.Б. Ганнушкина) просто не существует. Точнее, подобное усреднение и давало бы в результате – отсутствие характера, так как быть «бесхарактерным», значит не иметь никаких отличительных особенностей, что эмпирически – действительно пустая абстракция.
Третья особенность состоит в том, что в эмпирическую совокупность черт, составляющих ту или иную группу отклонений и акцентуаций, помещаются любые характеристики независимо от их функционального назначения и происхождения. Основные, базовые черты соседствуют здесь с различными своими модификациями, а их набор в целом разделяется, как правило, на черты первичные, т.е. врожденные, конституциональные, и вторичные, полученные при жизни. Полное же функциональное объяснение черт и их сочетаний (зачем и почему они складываются именно так), по существу, не входит в задачу исследователя, хотя и может иметь место в подходящих конкретных случаях.
Перечисленные особенности эмпирико-описательного, а по способу анализа – индуктивного подхода позволяют отличить его от подхода дедуктивного, направленного на выделение общих принципов построения типологии индивидуальностей. Не просто описать индивидуальные типы, но понять, объяснить необходимые закономерности их существования и, тем самым, раскрыть перед человеком возможность управления собственной индивидуальностью – такова общая цель этого подхода, к изложению которого мы и переходим. Понятно, что такая цель определяется радикально иными научно-теоретическими практическими установками
Вконтакте
Одноклассники
Похожие материалы в разделе Дифференциальная психология:
Классификация символов
Классификация символовКЛАССИФИКАЦИЯ ПЕРСОНАЖЕЙ
Общие группы символов I-XII считаются классами символов, которые включают в себя несколько типов символов, каждый из которых определен. Состояния каждого символа расположены в порядке важности и определены в Разделе B этой главы. Такое расположение состояний символов по символам и упорядочение или ранжирование типов символов в классе символов является попыткой сделать эту классификацию сравнительной и точной.См. Главу 5 для основных определений персонажей и типов персонажей, а также типов доказательств.
-
I. ПОЛОЖЕНИЕ И РАСПОЛОЖЕНИЕ (Класс символов с типами символов 1-8, как указано ниже. Состояния каждого типа символов описаны в Разделе B I этой главы).- Расположение. Положение органов или частей по отношению к окружающей среде (см. Раздел B I A, где описаны состояния персонажей этого типа).
- Позиция. Расположение или прикрепление органов или частей по отношению к другим, непохожим органам или основным частям (см. Раздел B I B).
- Расположение. Расположение органов или частей по отношению друг к другу (см. Раздел B I C).
- Ориентация. Расхождение органов или частей относительно центральной оси или точки (см. Раздел B I D).
- Поперечная осанка. Отношение концов одного органа или части к его центральной или поперечной оси (см. Раздел B I E).
- Продольная поза. Отношение краев одного органа или части к его центральной продольной оси (см. Раздел B I F).
- Общее структурное положение. Точка, точка, локальная или общая область или на одной структуре; например, апикальная часть листа, центральная точка лепестка (см. Раздел B I G).
- Эмбриональная позиция. Положение и расположение незрелых органов или частей.
- Праздник или префлорация. Расположение, в строгом смысле I 3, зародышевых частей цветка. Примечание: ростки чашечки и венчика в бутоне могут быть одинаковыми или разными (см. Раздел B I H).
- Ptyxis. Скручивание и складывание зародышевых листьев относительно центральной точки, поперечной оси или продольной оси; сочетание поперечной и продольной позы для эмбриональных частей (см. Раздел B I H).
- Вернация. Расположение зародышевых листьев в строгом смысле I 3. Большинство авторов так трактуют птиксис.
II. НОМЕР И РАЗМЕР- Номер. Любое значение или диапазон значений, выражающий абсолютное количество, сумму или совокупность отдельных единиц; или выражение относительных или сравнительных единиц (см. Раздел B II A).
- Размер. Пространственные размеры или пропорции любого органа или его частей, обычно выражаемые в виде числовых значений, относящихся к длине, ширине и глубине; или выражение относительных или сравнительных сумм (см. Раздел B II B).
- Циклический. Абсолютное количество оборотов частей, например количество оборотов цветочных частей или листьев (см. Раздел B II C).
- Merosity. Абсолютное количество частей внутри оборота, такое как количество лепестков в венчике или количество тычинок в андроциальном обороте (см. Раздел B II D).
- Fusion. Слияние или объединение подобных или непохожих органов или частей (см. Раздел B II E).
- Дивизия. Разделение, расхождение или разветвление на сегменты, части, доли и ветви любого органа или его частей (см. Раздел B II F).
III. ФОРМА И КОНТРОЛЬ- Форма. План определенной формы, плоский или двухмерный; или конкретная трехмерная фигура (см. Раздел B III A).
- Вершина.Кончик двумерной структуры, которая обычно ограничена верхними 5-10% полей; или верх трехмерной конструкции (см. Раздел B III B).
- Маржа. Граничная область стороны двумерной или плоской конструкции (см. Раздел B III C).
- База. Нижняя часть двумерной структуры, которая обычно ограничена нижними 5-10% полей; или дно трехмерной конструкции (см. Раздел B III B).
IV.ПОВЕРХНОСТЬ, ВЕНАЦИЯ, ТЕКСТУРА- Конфигурация. Рисунок на поверхности обычно является результатом внутренней структурной формы, за исключением жилкования (см. Раздел B IV A).
- Жилкование. Расположение жил, видимое на поверхности (см. Раздел B IV B). Особенности внутреннего жилкования см. В разделе «Жилкование» в главе 7.
- Поверхность. Особенности, происходящие из эпидермальных выростов или наростов, за исключением типов покровных трихом (см. Раздел B IV C).
- Одежда или украшения.Типы покрытия трихом (см. Раздел B IV D). Для получения информации об отдельных типах трихом см. Трихомы в главе 7.
- Текстура. Характерное физическое состояние или консистенция органа или его частей (см. Раздел B IV E).
В. СЕКС- Цветок. Половое состояние отдельного цветка (см. Раздел B V A).
- Соцветие. Расположение цветов в соцветии по половому признаку; или полное разнообразие половых условий цветка в соцветии (см. Раздел B V B).
- Завод. Общее разнообразие половых условий цветка в пределах одного растения (см. Раздел B V C).
- Население или вид. Общее разнообразие половых условий цветков в популяции (см. Раздел B V C).
VI. ОПЫЛЕНИЕ И УДОБРЕНИЕ- Тип опыления. Агент, с помощью которого пыльца переносится из пыльцевого мешка или пыльника на рыльце или семяпочку (см. Раздел B VI A).
- Путь опыления.Структурный путь, который проходит пыльцевая трубка, достигая семяпочки (см. Раздел B VI B).
- Тип удобрения. Источник (и) мужских гамет для оплодотворения (см. Раздел B VI C).
- Путь оплодотворения. Структурный путь, по которому пыльцевая трубка проходит к зародышевому мешку после достижения семяпочки (см. Раздел B VI D).
VII. ВРЕМЕННЫЕ ЯВЛЕНИЯ- Периодичность. Повторяемость явлений роста через определенные промежутки времени; или сезонность возникновения явлений роста растений (см. Раздел B VII A).
- Созревание. Относительное время развития различных органов или частей растений (см. Раздел B VII B).
- Продолжительность. Продолжительность существования завода или любой из его составных частей (см. Раздел B VII C).
VIII. РОСТ И РАЗВИТИЕ- Область роста. Расположение меристематической области на или внутри органа или его частей (см. Раздел B VIII A).
- Периодичность роста. Повторение или продолжительность меристематической активности в органе или его частях (см. Раздел B VIII B).
- Общие разработки. Направление созревания внутри растения его органов или его частей; например, от основания вверх или изнутри наружу (см. Раздел B VIII C).
- Типы развивающих побегов. Происхождение и созревание разных побегов (стебель с листьями) (см. Раздел B VIII D).
IX. УЗОРЫ- Симметрия. Соответствие частей по размеру, форме и расположению на противоположных сторонах плоскости, линии или точки (см. Раздел B IX A).
- Системы размещения. Общее расположение органов относительно друг друга, основанное на угле расхождения между следующими друг за другом схожими частями (см. Раздел B IX B).
- Паттерны ветвления. Положение ответвлений на главной оси и расположение боковых ответвлений (см. Раздел B IX C).
X. СЕКРЕТОРИЯ И ИЗБИРАТЕЛЬНЫЕ СТРУКТУРЫ- Функциональные типы. Химическая природа выделяемого или выделяемого вещества (см. Раздел B X A).
- Позиционные типы. Расположение желез на органах или частях (см. Раздел B X B).
XI. ЦВЕТ- Стандарт. Определение цвета на основе принятых цветовых таблиц и кодов (см. Раздел B XI A).
- Распределение. Образцы пестрого цвета на органе или частях (см. Раздел B XI B).
XII. ОБЩЕЕ- Общие. Дескрипторы, применимые к любому персонажу.
Классификация символов — Real Python
В этом уроке вы изучите строковых метода , которые классифицируют строку на основе символов , которые она содержит.Вот методы классификации персонажей:
-
str.isalnum () -
str.isalpha () -
str.isdigit () -
str.isidentifier ()* -
- ключевое слово (*) -
ул. Печатная () -
ул. Пробел () -
str.istitle () -
ул. Нижняя () -
ул. Верхняя () -
ул.isascii ()*
Метод .isidentifier () определяет, является ли целевая строка допустимым идентификатором. Что такое идентификатор Python ? Идентификатор — это имя, используемое для определения переменной, функции, класса или какого-либо другого типа объекта.
Идентификаторы Python:
- Должен начинаться с буквенного символа или символа подчеркивания (
_) - Может быть одним символом
- Может сопровождаться любым буквенно-цифровым символом или знаком подчеркивания
- Не может быть других знаков пунктуации
Еще одна потенциальная ловушка, на которую следует обратить внимание при именовании собственных идентификаторов, заключается в том, что вы не можете использовать существующее ключевое слово Python .Чтобы проверить, является ли имя, которое вы собираетесь использовать, существующим ключевым словом, вы можете импортировать функцию под названием iskeyword () из модуля под названием keyword :
>>> from keyword import iskeyword
>>> iskeyword ('и')
Правда
Вот ключевые слова Python:
| Ключевые слова Python | |||||
|---|---|---|---|---|---|
Ложь | перерыв | остальное | если | не | в то время как |
Истинно | класс | кроме | импорт | или | с |
Нет | продолжить | наконец | дюйм | проход | доход |
и | деф | для | это | поднять | по всему миру |
as | del | из | лямбда | возврат | нелокальный |
assert | Элиф | попробовать |
Дополнительную информацию о модулях Python см. На странице
Модули и пакеты Python — Введение.Метод .isascii () был представлен в Python 3.7.
Вот как использовать str.isalnum () :
>>> s = 'abc123'
>>> s.isalnum ()
Правда
>>> '' .isalnum ()
Ложь
>>> s = 'abc $ 123'
>>> s.isalnum ()
Ложь
Вот как использовать str.isalpha () :
>>> s = 'ABCabc'
>>> s.isalpha ()
Правда
>>> s = 'ABC123'
>>> с.isalpha ()
Ложь
Вот как использовать str.isdigit () :
>>> s = '123456'
>>> s.isdigit ()
Правда
>>> s = '123abc'
>>> s.isdigit ()
Ложь
Вот как использовать str.isidentifier () :
>>> 'spam32'.isidentifier ()
Правда
>>> '32spam'.isidentifier ()
Ложь
>>> 'foo $ 32'.isidentifier ()
Ложь
>>> 'def'.identifier ()
Правда
Вот как использовать iskeyword () :
>>> from keyword import iskeyword
>>> 'def'.isidentifier ()
Правда
>>> 'def'.iskeyword ()
Отслеживание (последний вызов последний):
Файл "", строка 1, в
'def'.iskeyword ()
AttributeError: объект 'str' не имеет атрибута 'iskeyword'
>>> iskeyword ('def')
Правда
>>> iskeyword ('и')
Правда
>>> iskeyword ('spam32')
Ложь
Вот как использовать str.isprintable () :
>>> s = 'a \ tb'
>>> s.isprintable ()
Ложь
>>> s = 'a b'
>>> с.isprintable ()
Правда
>>> s = ''
>>> s.isprintable ()
Правда
>>> s = 'а \ п б'
>>> s.isprintable ()
Ложь
Вот как использовать str.isspace () :
>>> s = 'a \ n b'
>>> s.isspace ()
Ложь
>>> s = '\ t \ n'
>>> s.isspace ()
Правда
Вот как использовать str.istitle () :
>>> s = 'И восходит солнце'
>>> с.istitle ()
Правда
>>> s = "Бургеры Боба!"
>>> s.istitle ()
Ложь
Вот как использовать str.islower () :
>>> s = 'asdlkjgadb'
>>> s.islower ()
Правда
>>> s = "spamIsgood"
>>> s.islower ()
Ложь
Вот как использовать str.isupper () :
>>> s = 'SPAMBACON'
>>> s.isupper ()
Правда
>>> s = "СПАМБЕКОН №1!"
>>> с.isupper ()
Правда
Вот как использовать str.isascii () :
>>> s = 'ABCabc # $%'
>>> s.isascii ()
Правда
>>> '' .isascii ()
Правда
>>> '' .isascii ()
Правда
>>> '∑'.isascii ()
Ложь
Классификация символов | Документы Microsoft
- 2 минуты на чтение
В этой статье
Каждая из этих подпрограмм проверяет указанный однобайтовый символ, широкий символ или многобайтовый символ на соответствие условию.(По определению набор символов ASCII от 0 до 127 является подмножеством всех наборов многобайтовых символов. Например, японская катакана включает символы ASCII, а также символы, отличные от ASCII.)
На условия тестирования влияет параметр LC_CTYPE категории параметра локали; см. setlocale для получения дополнительной информации. Версии этих функций без суффикса _l используют текущий языковой стандарт для этого зависящего от языкового стандарта поведения; версии с суффиксом _l идентичны, за исключением того, что вместо этого они используют переданный параметр локали.
Обычно эти процедуры выполняются быстрее, чем тесты, которые вы могли бы написать, и им следует отдавать предпочтение. Например, следующий код выполняется медленнее, чем вызов isalpha (c) :
if ((c> = 'A') && (c <= 'Z')) || ((c> = 'a') && (c <= 'z'))
вернуть ИСТИНА;
Процедуры классификации персонажей
| Обычный | Условие проверки символов |
|---|---|
| isalnum, iswalnum, _isalnum_l, _iswalnum_l, _ismbcalnum, _ismbcalnum_l, _ismbcalpha, _ismbcalpha_l, _ismbcdigit, _ismbcdigit_l | Буквенно-цифровой |
| _ismbcalnum, _ismbcalnum_l, _ismbcalpha, _ismbcalpha_l, _ismbcdigit, _ismbcdigit_l | Многобайтный буквенно-цифровой |
| isalpha, iswalpha, _isalpha_l, _iswalpha_l, _ismbcalnum, _ismbcalnum_l, _ismbcalpha, _ismbcalpha_l, _ismbcdigit, _ismbcdigit_l | По алфавиту |
| isascii, __isascii, iswascii | ASCII |
| isblank, iswblank, _isblank_l, _iswblank_l, _ismbcsblank, _ismbcsblank_l | Пробел (пробел или горизонтальная табуляция) |
| iscntrl, iswcntrl, _iscntrl_l, _iswcntrl_l | Контроль |
| iscsym, iscsymf, __iscsym, __iswcsym, __iscsymf, __iswcsymf, _iscsym_l, _iswcsym_l, _iscsymf_l, _iswcsymf_l | Буква, подчеркивание или цифра |
| iscsym, iscsymf, __iscsym, __iswcsym, __iscsymf, __iswcsymf, _iscsym_l, _iswcsym_l, _iscsymf_l, _iswcsymf_l | Буква или подчеркивание |
| isdigit, iswdigit, _isdigit_l, _iswdigit_l, _ismbcalnum, _ismbcalnum_l, _ismbcalpha, _ismbcalpha_l, _ismbcdigit, _ismbcdigit_l | Десятичная цифра |
| isgraph, iswgraph, _isgraph_l, _iswgraph_l, _ismbcgraph, _ismbcgraph_l, _ismbcprint, _ismbcprint_l, _ismbcpunct, _ismbcpunct_l, _ismbcblank, _ismbcblank_l, _ismbcspace, _ismbcspace | Для печати кроме места |
| islower, iswlower, _islower_l, _iswlower_l, _ismbclower, _ismbclower_l, _ismbcupper, _ismbcupper_l | Строчные |
| _ismbchira, _ismbchira_l, _ismbckata, _ismbckata_l | Хирагана |
| _ismbchira, _ismbchira_l, _ismbckata, _ismbckata_l | Катакана |
| _ismbclegal, _ismbclegal_l, _ismbcsymbol, _ismbcsymbol_l | Допустимый многобайтовый символ |
| _ismbcl0, _ismbcl0_l, _ismbcl1, _ismbcl1_l, _ismbcl2, _ismbcl2_l | Многобайтовый символ уровня Японии 0 |
| _ismbcl0, _ismbcl0_l, _ismbcl1, _ismbcl1_l, _ismbcl2, _ismbcl2_l | Многобайтовый символ уровня Японии 1 |
| _ismbcl0, _ismbcl0_l, _ismbcl1, _ismbcl1_l, _ismbcl2, _ismbcl2_l | Многобайтовый символ уровня Японии 2 |
| _ismbclegal, _ismbclegal_l, _ismbcsymbol, _ismbcsymbol_l | Неалфавитно-цифровой многобайтный символ |
| isprint, iswprint, _isprint_l, _iswprint_l, _ismbcgraph, _ismbcgraph_l, _ismbcprint, _ismbcprint_l, _ismbcpunct, _ismbcpunct_l, _ismbcblank, _ismbcblank_l, _ismbcspace, _ismbcspace | Для печати |
| ispunct, iswpunct, _ispunct_l, _iswpunct_l, _ismbcgraph, _ismbcgraph_l, _ismbcprint, _ismbcprint_l, _ismbcpunct, _ismbcpunct_l, _ismbcblank_space, _ismbcpunct_l, _ismbcblank_space, _ismbcpace | Пунктуация |
| isspace, iswspace, _isspace_l, _iswspace_l, _ismbcgraph, _ismbcgraph_l, _ismbcprint, _ismbcprint_l, _ismbcpunct, _ismbcpunct_l, _ismbcblank, _ismbcblank_l, _ismbcspace, _ismbcspace | Белое пространство |
| isupper, iswupper, _ismbclower, _ismbclower_l, _ismbcupper, _ismbcupper_l | Заглавные |
| _isctype, iswctype, _isctype_l, _iswctype_l | Свойство, заданное параметром desc argument |
| isxdigit, iswxdigit, _isxdigit_l, _iswxdigit_l | Шестнадцатеричная цифра |
| _mbclen, mblen, _mblen_l | Возвращает длину допустимого многобайтового символа; результат зависит от установки категории LC_CTYPE текущей локали |
См. Также
Универсальные подпрограммы выполнения C по категориям
Как разработать CNN для классификации рукописных цифр MNIST
Последнее обновление 24 августа 2020 г.
Как разработать сверточную нейронную сеть с нуля для классификации рукописных цифр MNIST.
Задача классификации рукописных цифр MNIST - это стандартный набор данных, используемый в компьютерном зрении и глубоком обучении.
Хотя набор данных эффективно решен, его можно использовать в качестве основы для обучения и практики разработки, оценки и использования сверточных нейронных сетей с глубоким обучением для классификации изображений с нуля. Это включает в себя то, как разработать надежную систему тестирования для оценки производительности модели, как изучить улучшения модели и как сохранить модель, а затем загрузить ее, чтобы делать прогнозы на новых данных.
В этом руководстве вы узнаете, как с нуля разработать сверточную нейронную сеть для классификации рукописных цифр.
После прохождения этого руководства вы будете знать:
- Как разработать тестовую программу для разработки надежной оценки модели и установления базового уровня производительности для задачи классификации.
- Как изучить расширения базовой модели для улучшения обучения и возможностей модели.
- Как разработать окончательную модель, оценить производительность окончательной модели и использовать ее для прогнозирования новых изображений.
Начните свой проект с моей новой книги «Глубокое обучение для компьютерного зрения», включающей пошаговых руководств и файлов исходного кода Python для всех примеров.
Приступим.
- Обновлено декабрь 2019 г. : обновленные примеры для TensorFlow 2.0 и Keras 2.3.
- Обновлено январь 2020 г. : исправлена ошибка, из-за которой модели определялись вне цикла перекрестной проверки.
Как разработать сверточную нейронную сеть с нуля для классификации рукописных цифр MNIST
Фотография Ричарда Аллавея, некоторые права защищены.
Обзор учебного пособия
Это руководство разделено на пять частей; их:
- Набор данных классификации рукописных цифр MNIST
- Методология оценки модели
- Как разработать базовую модель
- Как разработать улучшенную модель
- Как завершить модель и сделать прогнозы
Хотите результатов с помощью глубокого обучения для компьютерного зрения?
Пройдите мой бесплатный 7-дневный ускоренный курс электронной почты (с образцом кода).
Нажмите, чтобы зарегистрироваться, а также получите бесплатную электронную версию курса в формате PDF.
Нажмите здесь, чтобы подписаться
Среда разработки
В этом руководстве предполагается, что вы используете автономные Keras, работающие поверх TensorFlow с Python 3. Если вам нужна помощь в настройке среды разработки, см. Этот учебник:
Набор данных классификации рукописных цифр MNIST
Набор данных MNIST - это аббревиатура, обозначающая модифицированный набор данных Национального института стандартов и технологий.
Это набор данных из 60000 небольших квадратных изображений размером 28 × 28 пикселей в оттенках серого, состоящих из рукописных одиночных цифр от 0 до 9.
Задача состоит в том, чтобы отнести данное изображение рукописной цифры к одному из 10 классов, представляющих целые числа от 0 до 9 включительно.
Это широко используемый и хорошо изученный набор данных, по большей части это « решено, ». Самые эффективные модели - это сверточные нейронные сети с глубоким обучением, которые достигают точности классификации выше 99% с коэффициентом ошибок от 0.4% и 0,2% в тестовом наборе данных.
В приведенном ниже примере загружается набор данных MNIST с помощью API Keras и создается график первых девяти изображений в наборе обучающих данных.
# пример загрузки набора данных mnist from keras.datasets import mnist из matplotlib import pyplot # загрузить набор данных (trainX, trainy), (testX, testy) = mnist.load_data () # суммировать загруженный набор данных print ('Поезд: X =% s, y =% s'% (trainX.shape, trainy.shape)) print ('Тест: X =% s, y =% s'% (testX.shape, testy.shape)) # построить первые несколько изображений для i в диапазоне (9): # определить подзаговор pyplot.subplot (330 + 1 + я) # построить необработанные данные пикселей pyplot.imshow (trainX [i], cmap = pyplot.get_cmap ('серый')) # показать рисунок pyplot.show ()
# пример загрузки набора данных mnist из keras.datasets import mnist from matplotlib import pyplot # load dataset (trainX, trainy), (testX, testy) = mnist.load_data () # суммировать загруженный набор данных print ('Train: X =% s, y =% s'% (trainX.shape, trainy.shape)) print ('Test: X =% s, y =% s '% (testX.shape, testy.shape)) # построить первые несколько изображений для i в диапазоне (9): # определить подзаголовок pyplot.subplot (330 + 1 + i) # построить необработанные данные пикселей pyplot.imshow (trainX [i], cmap = pyplot.get_cmap ('gray')) # показать рисунок pyplot.show () |
При выполнении примера загружается набор данных для обучения и тестирования MNIST и распечатывается их форма.
Мы видим, что есть 60 000 примеров в наборе обучающих данных и 10 000 в наборе тестовых данных, и что изображения действительно квадратные с размером 28 × 28 пикселей.
Поезд: X = (60000, 28, 28), y = (60000,) Тест: X = (10000, 28, 28), y = (10000,)
Поезд: X = (60000, 28, 28), y = (60000,) Тест: X = (10000, 28, 28), y = (10000,) |
Также создается график первых девяти изображений в наборе данных, показывающий естественный рукописный характер изображений, подлежащих классификации.
График подмножества изображений из набора данных MNIST
Методология оценки модели
Хотя набор данных MNIST эффективно решен, он может быть полезной отправной точкой для разработки и практики методологии решения задач классификации изображений с использованием сверточных нейронных сетей.
Вместо того, чтобы изучать литературу по хорошо работающим моделям в наборе данных, мы можем разработать новую модель с нуля.
В наборе данных уже есть четко определенный набор данных для обучения и тестирования, который мы можем использовать.
Чтобы оценить производительность модели для данного обучающего прогона, мы можем дополнительно разделить обучающий набор на набор данных для обучения и проверки. Затем можно построить график производительности набора данных по обучению и валидации для каждого прогона, чтобы представить кривые обучения и понять, насколько хорошо модель изучает проблему.
API Keras поддерживает это, указав аргумент « validation_data » функции model.fit () при обучении модели, которая, в свою очередь, вернет объект, описывающий производительность модели для выбранных потерь и метрики на каждую тренировочную эпоху.
# запись производительности модели в наборе данных проверки во время обучения history = model.fit (..., validation_data = (valX, valY))
# запись производительности модели в наборе данных проверки во время обучения history = model.fit (..., validation_data = (valX, valY)) |
Чтобы оценить производительность модели по проблеме в целом, мы можем использовать k-кратную перекрестную проверку, возможно, пятикратную перекрестную проверку.Это даст некоторый учет дисперсии моделей как в отношении различий в наборах данных для обучения и тестирования, так и в отношении стохастической природы алгоритма обучения. Производительность модели может быть принята как средняя производительность в k-кратном масштабе с учетом стандартного отклонения, которое при желании может быть использовано для оценки доверительного интервала.
Мы можем использовать класс KFold из scikit-learn API, чтобы реализовать k-кратную оценку перекрестной проверки данной модели нейронной сети.Есть много способов добиться этого, хотя мы можем выбрать гибкий подход, при котором класс KFold используется только для указания индексов строк, используемых для каждого вертела.
# пример k-кратного резюме для нейронной сети данные = ... # подготовить перекрестную проверку kfold = KFold (5, shuffle = True, random_state = 1) # перечислить разбиения для train_ix, test_ix в kfold.split (данные): модель = ... ...
# пример k-кратного cv для нейронной сети data =... # подготовить перекрестную проверку kfold = KFold (5, shuffle = True, random_state = 1) # перечислить разбиения для train_ix, test_ix в kfold.split (данные): model = ... ... |
Мы воздержимся от фактического набора тестовых данных и будем использовать его для оценки нашей окончательной модели.
Как разработать базовую модель
Первым шагом является разработка базовой модели.
Это критически важно, поскольку оно включает в себя разработку инфраструктуры для тестовой оснастки, чтобы любую модель, которую мы разрабатываем, можно было оценить в наборе данных, и устанавливает базовый уровень производительности модели по проблеме, с помощью которого можно сравнивать все улучшения.
Испытательная привязь имеет модульную конструкцию, и мы можем разработать отдельную функцию для каждой детали. Это позволяет при желании модифицировать или заменять данный аспект тестовой оснастки отдельно от остальных.
Мы можем разработать эту испытательную систему с пятью ключевыми элементами. Это загрузка набора данных, подготовка набора данных, определение модели, оценка модели и представление результатов.
Загрузить набор данных
Мы кое-что знаем о наборе данных.
Например, мы знаем, что все изображения предварительно выровнены (например, каждое изображение содержит только нарисованную вручную цифру), что все изображения имеют одинаковый квадратный размер 28 × 28 пикселей и что изображения имеют оттенки серого.
Следовательно, мы можем загружать изображения и изменять форму массивов данных, чтобы они имели единственный цветовой канал.
# загрузить набор данных (trainX, trainY), (testX, testY) = mnist.load_data () # преобразовать набор данных в один канал trainX = поездX.изменить форму ((trainX.shape [0], 28, 28, 1)) testX = testX.reshape ((testX.shape [0], 28, 28, 1))
# загрузить набор данных (trainX, trainY), (testX, testY) = mnist.load_data () # преобразовать набор данных в один канал trainX = trainX.reshape ((trainX.shape [0], 28, 28, 1)) testX = testX.reshape ((testX.shape [0], 28, 28, 1)) |
Мы также знаем, что существует 10 классов и что классы представлены как уникальные целые числа.
Таким образом, мы можем использовать одно горячее кодирование для элемента класса каждой выборки, преобразовывая целое число в двоичный вектор из 10 элементов с 1 для индекса значения класса и 0 значений для всех других классов. Этого можно добиться с помощью служебной функции to_categorical () .
# одно горячее кодирование целевых значений trainY = to_categorical (trainY) testY = to_categorical (testY)
# one целевые значения горячего кодирования trainY = to_categorical (trainY) testY = to_categorical (testY) |
Функция load_dataset () реализует это поведение и может использоваться для загрузки набора данных.
# загрузить поезд и тестовый набор данных def load_dataset (): # загрузить набор данных (trainX, trainY), (testX, testY) = mnist.load_data () # преобразовать набор данных в один канал trainX = trainX.reshape ((trainX.shape [0], 28, 28, 1)) testX = testX.reshape ((testX.shape [0], 28, 28, 1)) # одно горячее кодирование целевых значений trainY = to_categorical (trainY) testY = to_categorical (testY) возврат trainX, trainY, testX, testY
# загрузить поезд и тестовый набор данных def load_dataset (): # загрузить набор данных (trainX, trainY), (testX, testY) = mnist.load_data () # преобразовать набор данных в один канал trainX = trainX.reshape ((trainX.shape [0], 28, 28, 1)) testX = testX.reshape ((testX.shape [0 ], 28, 28, 1)) # one целевые значения горячего кодирования trainY = to_categorical (trainY) testY = to_categorical (testY) return trainX, trainY, testX, testY |
Подготовка пиксельных данных
Мы знаем, что значения пикселей для каждого изображения в наборе данных представляют собой целые числа без знака в диапазоне от черного до белого или от 0 до 255.
Мы не знаем наилучшего способа масштабирования значений пикселей для моделирования, но мы знаем, что потребуется некоторое масштабирование.
Хорошей отправной точкой является нормализация значений пикселей изображений в градациях серого, например масштабируйте их до диапазона [0,1]. Это включает в себя сначала преобразование типа данных из целых чисел без знака в числа с плавающей запятой, а затем деление значений пикселей на максимальное значение.
# преобразовать целые числа в числа с плавающей запятой train_norm = train.astype ('float32') test_norm = тест.astype ('float32') # нормализовать до диапазона 0-1 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0
# преобразовать целые числа в числа с плавающей запятой train_norm = train.astype ('float32') test_norm = test.astype ('float32') # нормализовать до диапазона 0-1 train_norm = train_norm / 255.0 test_norm = test_norm / 255,0 |
Функция Prep_pixels () ниже реализует это поведение и предоставляет значения пикселей как для обучающего, так и для тестового наборов данных, которые необходимо масштабировать.
# масштабный пиксель def Prep_pixels (поезд, тест): # преобразовать целые числа в числа с плавающей запятой train_norm = train.astype ('float32') test_norm = test.astype ('float32') # нормализовать до диапазона 0-1 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # вернуть нормализованные изображения возврат train_norm, test_norm
# масштабировать пиксели def Prep_pixels (train, test): # преобразовать целые числа в числа с плавающей запятой train_norm = train.astype ('float32') test_norm = test.astype ('float32') # нормализовать до диапазона 0-1 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # вернуть нормализованные изображения return train_norm, test_norm |
Эта функция должна быть вызвана для подготовки значений пикселей перед любым моделированием.
Определить модель
Затем нам нужно определить базовую модель сверточной нейронной сети для проблемы.
Модель имеет два основных аспекта: интерфейс извлечения признаков, состоящий из сверточных слоев и слоев пула, и серверный модуль классификатора, который будет делать прогноз.
Для сверточного интерфейса мы можем начать с одного сверточного слоя с небольшим размером фильтра (3,3) и скромным количеством фильтров (32), за которым следует максимальный слой объединения. Затем карты фильтров могут быть сглажены, чтобы предоставить классификатору функции.
Учитывая, что проблема заключается в задаче классификации нескольких классов, мы знаем, что нам потребуется выходной слой с 10 узлами, чтобы предсказать распределение вероятностей изображения, принадлежащего каждому из 10 классов.Это также потребует использования функции активации softmax. Между экстрактором признаков и выходным слоем мы можем добавить плотный слой для интерпретации признаков, в данном случае со 100 узлами.
Все уровни будут использовать функцию активации ReLU и схему инициализации веса He, оба являются передовыми методами.
Мы будем использовать консервативную конфигурацию оптимизатора стохастического градиентного спуска со скоростью обучения 0,01 и импульсом 0,9. Категориальная функция кросс-энтропийных потерь будет оптимизирована, подходящая для мультиклассовой классификации, и мы будем отслеживать метрику точности классификации, которая подходит, учитывая, что у нас одинаковое количество примеров в каждом из 10 классов.
Функция define_model () ниже определит и вернет эту модель.
# определить модель cnn def define_model (): model = Последовательный () model.add (Conv2D (32, (3, 3), активация = 'relu', kernel_initializer = 'he_uniform', input_shape = (28, 28, 1))) model.add (MaxPooling2D ((2, 2))) model.add (Сглаживание ()) model.add (Dense (100, активация = 'relu', kernel_initializer = 'he_uniform')) model.add (Плотный (10, активация = 'softmax')) # скомпилировать модель opt = SGD (lr = 0.01, импульс = 0,9) model.compile (optimizer = opt, loss = 'category_crossentropy', metrics = ['precision']) вернуть модель
# define cnn model def define_model (): model = Sequential () model.add (Conv2D (32, (3, 3), activate = 'relu', kernel_initializer = 'he_uniform', input_shape = (28, 28, 1))) model.add (MaxPooling2D ((2, 2))) model.add (Flatten ()) model.add (Dense (100, activate = 'relu', kernel_initializer = 'he_uniform')) model.add (Dense (10, activate = 'softmax')) # скомпилировать модель opt = SGD (lr = 0,01 , импульс = 0,9) model.compile (optimizer = opt, loss ='ategorical_crossentropy ', metrics = [' precision ']) return model |
Оценить модель
После того, как модель определена, нам нужно ее оценить.
Модель будет оцениваться с использованием пятикратной перекрестной проверки.Значение k = 5 было выбрано, чтобы обеспечить основу как для повторной оценки, так и не быть настолько большим, чтобы требовать длительного времени. Каждый набор тестов будет составлять 20% обучающего набора данных или около 12 000 примеров, что близко к размеру фактического набора тестов для этой задачи.
Обучающий набор данных перетасовывается перед разделением, и выборка перетасовывается каждый раз, так что любая модель, которую мы оцениваем, будет иметь одни и те же обучающие и тестовые наборы данных в каждом сгибе, обеспечивая сравнение моделей между яблоками и яблоками.
Мы обучим базовую модель для скромных 10 эпох обучения с размером пакета по умолчанию из 32 примеров. Набор тестов для каждой свертки будет использоваться для оценки модели как в каждую эпоху тренировочного прогона, чтобы мы могли позже создать кривые обучения, так и в конце прогона, чтобы мы могли оценить производительность модели. Таким образом, мы будем отслеживать итоговую историю каждого запуска, а также точность классификации сгиба.
Функция extract_model () ниже реализует это поведение, принимая набор обучающих данных в качестве аргументов и возвращая список оценок точности и историй обучения, которые могут быть затем обобщены.
# оценить модель с помощью k-кратной перекрестной проверки def оценивать_модель (dataX, dataY, n_folds = 5): оценки, истории = список (), список () # подготовить перекрестную проверку kfold = KFold (n_folds, shuffle = True, random_state = 1) # перечислить разбиения для train_ix, test_ix в kfold.split (dataX): # определить модель модель = define_model () # выбираем строки для обучения и тестирования trainX, trainY, testX, testY = dataX [train_ix], dataY [train_ix], dataX [test_ix], dataY [test_ix] # подходящая модель история = модель.fit (trainX, trainY, epochs = 10, batch_size = 32, validation_data = (testX, testY), verbose = 0) # оценить модель _, acc = model.evaluate (testX, testY, verbose = 0) print ('>% .3f'% (согласно * 100.0)) Результаты в # магазинах scores.append (acc) history.append (история) вернуть результаты, истории
1 2 3 4 5 6 7 8 9 10 11 12 13 14 14 18 19 20 | # оценить модель с помощью k-кратной перекрестной проверки def Assessment_model (dataX, dataY, n_folds = 5): scores, history = list (), list () # подготовить перекрестную проверку kfold = KFold (n_folds, shuffle = True, random_state = 1) # перечислить разбиения для train_ix, test_ix в kfold.split (dataX): # определить модель model = define_model () # выбрать строки для обучения и тестирования trainX, trainY, testX, testY = dataX [train_ix], dataY [train_ix], dataX [test_ix] , dataY [test_ix] # fit model history = model.fit (trainX, trainY, epochs = 10, batch_size = 32, validation_data = (testX, testY), verbose = 0) # оценить модель _ , acc = model.evaluate (testX, testY, verbose = 0) print ('>%.3f '% (acc * 100.0)) # сохраняет оценки scores.append (acc) histories.append (history) результатов возврата, истории |
Представить результаты
После того, как модель будет оценена, мы можем представить результаты.
Необходимо представить два ключевых аспекта: диагностику обучающего поведения модели во время обучения и оценку производительности модели. Их можно реализовать с помощью отдельных функций.
Во-первых, диагностика включает создание линейного графика, показывающего производительность модели на поезде и наборе тестов во время каждого раза k-кратной перекрестной проверки. Эти графики полезны для понимания того, соответствует ли модель избыточному, недостаточному или хорошо подходит для набора данных.
Мы создадим одну фигуру с двумя частями графика, одна для потерь, а другая для точности. Синие линии будут указывать на производительность модели в наборе обучающих данных, а оранжевые линии - на производительность на удерживаемом наборе тестовых данных.Функция summarize_diagnostics () ниже создает и показывает этот график с учетом собранных историй обучения.
# построить диагностические кривые обучения def summarize_diagnostics (истории): для i в диапазоне (len (истории)): # потеря сюжета pyplot.subplot (2, 1, 1) pyplot.title ('потеря перекрестной энтропии') pyplot.plot (history [i] .history ['loss'], color = 'blue', label = 'train') pyplot.plot (history [i] .history ['val_loss'], color = 'orange', label = 'test') # точность сюжета пиплот.подзаговор (2, 1, 2) pyplot.title ('Точность классификации') pyplot.plot (history [i] .history ['точность'], color = 'blue', label = 'train') pyplot.plot (history [i] .history ['val_accuracy'], color = 'orange', label = 'test') pyplot.show ()
# plot диагностические кривые обучения def summarize_diagnostics (stories): for i in range (len (stories)): # plot loss pyplot.subplot (2, 1, 1) pyplot.title ('Перекрестная потеря энтропии') pyplot.plot (history [i] .history ['loss'], color = 'blue', label = 'train') pyplot.plot (history [i] .history ['val_loss'], color = 'orange', label = 'test') # точность графика pyplot.subplot (2, 1, 2) pyplot .title ('Точность классификации') pyplot.plot (history [i] .history ['precision'], color = 'blue', label = 'train') pyplot.plot (history [i] .history ['val_accuracy'], color = 'orange', label = 'test') pyplot.показать () |
Затем оценки точности классификации, полученные во время каждой кратности, можно суммировать, вычислив среднее значение и стандартное отклонение. Это обеспечивает оценку средней ожидаемой производительности модели, обученной на этом наборе данных, с оценкой средней дисперсии в среднем. Мы также подведем итоги распределения оценок, создав и отобразив график в виде прямоугольников и усов.
Функция summarize_performance () ниже реализует это для заданного списка оценок, собранных во время оценки модели.
# подвести итоги работы модели def summarize_performance (баллы): # распечатать сводку print ('Точность: среднее =%. 3f std =%. 3f, n =% d'% (среднее (баллы) * 100, стандартное (баллы) * 100, len (баллы))) # график результатов в виде квадратов и усов pyplot.boxplot (баллы) pyplot.show ()
# summarize model performance def summarize_performance (scores): # print summary print ('Точность: среднее =%.3f std =%. 3f, n =% d '% (среднее (баллы) * 100, std (баллы) * 100, len (баллы))) # графики результатов в виде прямоугольников и усов pyplot.boxplot (баллы ) pyplot.show () |
Полный пример
Нам нужна функция, которая будет управлять тестовым жгутом.
Это включает вызов всех функций определения.
# запускаем тестовую программу для оценки модели def run_test_harness (): # загрузить набор данных trainX, trainY, testX, testY = load_dataset () # подготовить данные пикселей trainX, testX = Prep_pixels (trainX, testX) # оценить модель оценки, истории = оценка_модель (trainX, trainY) # кривые обучения summarize_diagnostics (истории) # подвести итоги расчетной производительности summarize_performance (баллы)
# запустить тестовый набор для оценки модели def run_test_harness (): # загрузить набор данных trainX, trainY, testX, testY = load_dataset () # подготовить данные пикселей trainX, testX = Prep_pixels trainX, testX) # оцените модель баллов, history = eval_model (trainX, trainY) # кривые обучения summarize_diagnostics (истории) # суммируйте оценочную производительность summarize_performance ( | баллов)
Теперь у нас есть все необходимое; Полный пример кода для базовой модели сверточной нейронной сети в наборе данных MNIST приведен ниже.
# базовая модель cnn для mnist из среднего значения импорта из numpy import std из matplotlib import pyplot из sklearn.model_selection импорт KFold from keras.datasets import mnist from keras.utils import to_categorical из keras.models импортировать Последовательный из keras.layers импортировать Conv2D из keras.layers импорт MaxPooling2D из keras.layers import Плотный из keras.layers import Flatten от keras.optimizers импортные SGD # загрузить поезд и тестовый набор данных def load_dataset (): # загрузить набор данных (trainX, trainY), (testX, testY) = mnist.load_data () # преобразовать набор данных в один канал trainX = trainX.reshape ((trainX.shape [0], 28, 28, 1)) testX = testX.reshape ((testX.shape [0], 28, 28, 1)) # одно горячее кодирование целевых значений trainY = to_categorical (trainY) testY = to_categorical (testY) вернуть trainX, trainY, testX, testY # масштабный пиксель def Prep_pixels (поезд, тест): # преобразовать целые числа в числа с плавающей запятой train_norm = train.astype ('float32') test_norm = test.astype ('float32') # нормализовать до диапазона 0-1 поезд_норм = поезд_норм / 255.0 test_norm = test_norm / 255.0 # вернуть нормализованные изображения вернуть train_norm, test_norm # определить модель cnn def define_model (): model = Последовательный () model.add (Conv2D (32, (3, 3), активация = 'relu', kernel_initializer = 'he_uniform', input_shape = (28, 28, 1))) model.add (MaxPooling2D ((2, 2))) model.add (Сглаживание ()) model.add (Dense (100, активация = 'relu', kernel_initializer = 'he_uniform')) model.add (Плотный (10, активация = 'softmax')) # скомпилировать модель opt = SGD (lr = 0.01, импульс = 0,9) model.compile (optimizer = opt, loss = 'category_crossentropy', metrics = ['precision']) модель возврата # оценить модель с помощью k-кратной перекрестной проверки def оценивать_модель (dataX, dataY, n_folds = 5): оценки, истории = список (), список () # подготовить перекрестную проверку kfold = KFold (n_folds, shuffle = True, random_state = 1) # перечислить разбиения для train_ix, test_ix в kfold.split (dataX): # определить модель модель = define_model () # выбираем строки для обучения и тестирования trainX, trainY, testX, testY = dataX [train_ix], dataY [train_ix], dataX [test_ix], dataY [test_ix] # подходящая модель история = модель.fit (trainX, trainY, epochs = 10, batch_size = 32, validation_data = (testX, testY), verbose = 0) # оценить модель _, acc = model.evaluate (testX, testY, verbose = 0) print ('>% .3f'% (согласно * 100.0)) Результаты в # магазинах scores.append (acc) history.append (история) вернуть оценки, истории # построить диагностические кривые обучения def summarize_diagnostics (истории): для i в диапазоне (len (истории)): # потеря сюжета pyplot.subplot (2, 1, 1) пиплот.title («Перекрестная потеря энтропии») pyplot.plot (history [i] .history ['loss'], color = 'blue', label = 'train') pyplot.plot (history [i] .history ['val_loss'], color = 'orange', label = 'test') # точность сюжета pyplot.subplot (2, 1, 2) pyplot.title ('Точность классификации') pyplot.plot (history [i] .history ['точность'], color = 'blue', label = 'train') pyplot.plot (history [i] .history ['val_accuracy'], color = 'orange', label = 'test') pyplot.show () # подвести итоги работы модели def summarize_performance (баллы): # распечатать сводку print ('Точность: среднее =%.3f std =%. 3f, n =% d '% (среднее (баллы) * 100, стандартное (баллы) * 100, len (баллы))) # график результатов в виде квадратов и усов pyplot.boxplot (баллы) pyplot.show () # запускаем тестовую программу для оценки модели def run_test_harness (): # загрузить набор данных trainX, trainY, testX, testY = load_dataset () # подготовить данные пикселей trainX, testX = Prep_pixels (trainX, testX) # оценить модель оценки, истории = оценка_модель (trainX, trainY) # кривые обучения summarize_diagnostics (истории) # подвести итоги расчетной производительности summarize_performance (баллы) # точка входа, запускаем тестовый жгут run_test_harness ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 14 18 19 20 21 22 23 24 25 26 27 28 29 30 3435 36 37 38 39 40 41 42 43 44 45 46 47 51 52 53 54 55 56 57 58 59 60 61 62 63 9 0005 6465 66 67 68 69 70 71 72 73 74 75 76 79 79 81 82 83 84 85 86 87 88 89 90 91 92 94 9798 99 100 101 102 103 104 105 106 107 108 109 | # базовая модель cnn для mnist из numpy import mean из numpy import std из matplotlib import pyplot из sklearn.model_selection import KFold from keras.datasets import mnist from keras.utils import to_categorical from keras.models import Sequential from keras.layers import Conv2D from keras.layers import d max6 Denseиз keras.layers import Flatten from keras.optimizers import SGD # load train and test dataset def load_dataset (): # load dataset (trainX, trainY), (test testY) = mnist.load_data () # преобразовать набор данных в один канал trainX = trainX.reshape ((trainX.shape [0], 28, 28, 1)) testX = testX.reshape ((testX.shape [0 ], 28, 28, 1)) # one целевые значения горячего кодирования trainY = to_categorical (trainY) testY = to_categorical (testY) return trainX, trainY, testX, testY # scale def Prep_pixels (train, test): # преобразовать целые числа в числа с плавающей запятой train_norm = train.astype ('float32') test_norm = test.astype ('float32') # нормализовать до диапазона 0-1 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # вернуть нормализованные изображения return train_norm, test_norm # define cnn model def define_model (): model = Sequential () model.add (Conv2D (32, (3, 3), activate = 'relu', kernel_initializer = ' he_uniform ', input_shape = (28, 28, 1))) модель.add (MaxPooling2D ((2, 2))) model.add (Flatten ()) model.add (Dense (100, Activation = 'relu', kernel_initializer = 'he_uniform')) model.add ( Dense (10, Activation = 'softmax')) # скомпилировать модель opt = SGD (lr = 0,01, импульс = 0,9) model.compile (optimizer = opt, loss = 'categoryorical_crossentropy', metrics = [' точность ']) return model # оценить модель с помощью k-кратной перекрестной проверки def Assessment_model (dataX, dataY, n_folds = 5): оценок, history = list (), list () # подготовить перекрестную проверку kfold = KFold (n_folds, shuffle = True, random_state = 1) # перечислить разбиения для train_ix, test_ix в kfold.split (dataX): # определить модель model = define_model () # выбрать строки для обучения и тестирования trainX, trainY, testX, testY = dataX [train_ix], dataY [train_ix], dataX [test_ix] , dataY [test_ix] # fit model history = model.fit (trainX, trainY, epochs = 10, batch_size = 32, validation_data = (testX, testY), verbose = 0) # оценить модель _ , acc = model.evaluate (testX, testY, verbose = 0) print ('>%.3f '% (acc * 100.0)) # сохраняет оценки scores.append (acc) history.append (history) return scores, history # plot диагностические кривые обучения def summarize_diagnostics ( историй): для i в диапазоне (len (истории)): # потеря графика pyplot.subplot (2, 1, 1) pyplot.title ('Cross Entropy Loss') pyplot.plot (history [i] .history ['loss'], color = 'blue', label = 'train') pyplot.plot (history [i] .history ['val_loss'], color = 'orange', label = 'test') # точность графика pyplot.subplot (2, 1, 2) pyplot.title (' Точность классификации ') pyplot.plot (history [i] .history [' precision '], color =' blue ', label =' train ') pyplot.plot (history [i] .history [' val_accuracy ' ], color = 'orange', label = 'test') pyplot.show () # суммировать производительность модели def summarize_performance (scores): # print summary print ('Accuracy: mean знак равно3f std =%. 3f, n =% d '% (среднее (баллы) * 100, std (баллы) * 100, len (баллы))) # графики результатов в виде прямоугольников и усов pyplot.boxplot (баллы ) pyplot.show () # запустить тестовую программу для оценки модели def run_test_harness (): # загрузить набор данных trainX, trainY, testX, testY = load_dataset () пиксельные данные trainX, testX = Prep_pixels (trainX, testX) # оцените модель баллов, history = eval_model (trainX, trainY) # кривые обучения summarize_diagnostics (history) # суммируйте # суммируйте оценочную производительность summarize_performance (scores) # точка входа, запустить тестовую программу run_test_harness () |
При выполнении примера печатается точность классификации для каждого этапа процесса перекрестной проверки.Это помогает понять, что оценка модели продолжается.
Примечание : Ваши результаты могут отличаться из-за стохастической природы алгоритма или процедуры оценки или различий в числовой точности. Попробуйте запустить пример несколько раз и сравните средний результат.
Мы можем видеть два случая, когда модель достигает безупречного мастерства, и один случай, когда она достигла точности ниже 98%. Это хорошие результаты.
> 98.550 > 98,600 > 98,642 > 98,850 > 98,742
> 98,550 > 98,600 > 98,642 > 98,850 > 98,742 |
Затем показан диагностический график, дающий представление о поведении модели при обучении по каждой складке.
В этом случае мы видим, что модель в целом хорошо подходит, с сходящимися кривыми обучения и тестирования.Нет явных признаков переоборудования или недостаточного оснащения.
Кривые потерь и обучения точности для базовой модели во время перекрестной проверки k-Fold
Затем рассчитывается сводная характеристика модели.
Мы видим, что в этом случае оценка модели составляет около 98,6%, что является разумным.
Точность: среднее значение = 98,677 стандартное отклонение = 0,107, n = 5
Точность: среднее = 98,677 стандартное = 0.107, п = 5 |
Наконец, создается диаграмма в виде прямоугольников и усов, чтобы суммировать распределение оценок точности.
Ящик и диаграмма усов для оценок точности для базовой модели, оцененных с помощью перекрестной проверки k-Fold
Теперь у нас есть надежная испытательная система и хорошо работающая базовая модель.
Как разработать улучшенную модель
Есть много способов улучшить базовую модель.
Мы рассмотрим области конфигурации модели, которые часто приводят к улучшениям, так называемым низко висящим плодам.Первый - это изменение алгоритма обучения, а второй - увеличение глубины модели.
Улучшение обучения
Есть много аспектов алгоритма обучения, которые можно изучить для улучшения.
Возможно, наиболее важным преимуществом является скорость обучения, например оценка влияния меньших или больших значений скорости обучения, а также расписания, которые изменяют скорость обучения во время обучения.
Другой подход, который может быстро ускорить изучение модели и привести к значительному повышению производительности, - это пакетная нормализация.Мы оценим влияние пакетной нормализации на нашу базовую модель.
Пакетную нормализацию можно использовать после сверточных и полносвязных слоев. Это имеет эффект изменения распределения выходных данных слоя, в частности, путем стандартизации выходных данных. Это стабилизирует и ускоряет процесс обучения.
Мы можем обновить определение модели, чтобы использовать пакетную нормализацию после функции активации для сверточных и плотных слоев нашей базовой модели.Обновленная версия функции define_model () с пакетной нормализацией приведена ниже.
# определить модель cnn def define_model (): model = Последовательный () model.add (Conv2D (32, (3, 3), активация = 'relu', kernel_initializer = 'he_uniform', input_shape = (28, 28, 1))) model.add (BatchNormalization ()) model.add (MaxPooling2D ((2, 2))) model.add (Сглаживание ()) model.add (Dense (100, активация = 'relu', kernel_initializer = 'he_uniform')) модель.добавить (BatchNormalization ()) model.add (Плотный (10, активация = 'softmax')) # скомпилировать модель opt = SGD (lr = 0,01, импульс = 0,9) model.compile (optimizer = opt, loss = 'category_crossentropy', metrics = ['precision']) вернуть модель
# define cnn model def define_model (): model = Sequential () model.add (Conv2D (32, (3, 3), activate = 'relu', kernel_initializer = 'he_uniform', input_shape = (28, 28, 1))) модель.add (BatchNormalization ()) model.add (MaxPooling2D ((2, 2))) model.add (Flatten ()) model.add (Dense (100, активация = 'relu', kernel_initializer = ' he_uniform ')) model.add (BatchNormalization ()) model.add (Dense (10, activate =' softmax ')) # скомпилировать модель opt = SGD (lr = 0,01, импульс = 0,9) model.compile (optimizer = opt, loss ='ategorical_crossentropy ', metrics = [' precision ']) return model |
Полный список кода с этим изменением представлен ниже.
# модель cnn с пакетной нормализацией для mnist из среднего значения импорта из numpy import std из matplotlib import pyplot из sklearn.model_selection импорт KFold from keras.datasets import mnist from keras.utils import to_categorical из keras.models импортировать Последовательный из keras.layers импортировать Conv2D из keras.layers импорт MaxPooling2D из keras.layers import Плотный из keras.layers import Flatten из кераса.оптимизаторы импортируют SGD из keras.layers import BatchNormalization # загрузить поезд и тестовый набор данных def load_dataset (): # загрузить набор данных (trainX, trainY), (testX, testY) = mnist.load_data () # преобразовать набор данных в один канал trainX = trainX.reshape ((trainX.shape [0], 28, 28, 1)) testX = testX.reshape ((testX.shape [0], 28, 28, 1)) # одно горячее кодирование целевых значений trainY = to_categorical (trainY) testY = to_categorical (testY) вернуть trainX, trainY, testX, testY # масштабный пиксель def Prep_pixels (поезд, тест): # преобразовать целые числа в числа с плавающей запятой train_norm = поезд.astype ('float32') test_norm = test.astype ('float32') # нормализовать до диапазона 0-1 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # вернуть нормализованные изображения вернуть train_norm, test_norm # определить модель cnn def define_model (): model = Последовательный () model.add (Conv2D (32, (3, 3), активация = 'relu', kernel_initializer = 'he_uniform', input_shape = (28, 28, 1))) model.add (BatchNormalization ()) model.add (MaxPooling2D ((2, 2))) модель.добавить (Flatten ()) model.add (Dense (100, активация = 'relu', kernel_initializer = 'he_uniform')) model.add (BatchNormalization ()) model.add (Плотный (10, активация = 'softmax')) # скомпилировать модель opt = SGD (lr = 0,01, импульс = 0,9) model.compile (optimizer = opt, loss = 'category_crossentropy', metrics = ['precision']) модель возврата # оценить модель с помощью k-кратной перекрестной проверки def оценивать_модель (dataX, dataY, n_folds = 5): оценки, истории = список (), список () # подготовить перекрестную проверку kfold = KFold (n_folds, shuffle = True, random_state = 1) # перечислить разбиения для train_ix, test_ix в kfold.split (dataX): # определить модель модель = define_model () # выбираем строки для обучения и тестирования trainX, trainY, testX, testY = dataX [train_ix], dataY [train_ix], dataX [test_ix], dataY [test_ix] # подходящая модель history = model.fit (trainX, trainY, epochs = 10, batch_size = 32, validation_data = (testX, testY), verbose = 0) # оценить модель _, acc = model.evaluate (testX, testY, verbose = 0) print ('>% .3f'% (согласно * 100.0)) Результаты в # магазинах scores.append (acc) истории.добавить (история) вернуть оценки, истории # построить диагностические кривые обучения def summarize_diagnostics (истории): для i в диапазоне (len (истории)): # потеря сюжета pyplot.subplot (2, 1, 1) pyplot.title ('потеря перекрестной энтропии') pyplot.plot (history [i] .history ['loss'], color = 'blue', label = 'train') pyplot.plot (history [i] .history ['val_loss'], color = 'orange', label = 'test') # точность сюжета pyplot.subplot (2, 1, 2) pyplot.title ('Точность классификации') пиплот.сюжет (истории [i]. история ['точность'], цвет = 'синий', метка = 'поезд') pyplot.plot (history [i] .history ['val_accuracy'], color = 'orange', label = 'test') pyplot.show () # подвести итоги работы модели def summarize_performance (баллы): # распечатать сводку print ('Точность: среднее =%. 3f std =%. 3f, n =% d'% (среднее (баллы) * 100, стандартное (баллы) * 100, len (баллы))) # график результатов в виде квадратов и усов pyplot.boxplot (баллы) pyplot.show () # запускаем тестовую программу для оценки модели def run_test_harness (): # загрузить набор данных trainX, trainY, testX, testY = load_dataset () # подготовить данные пикселей trainX, testX = Prep_pixels (trainX, testX) # оценить модель оценки, истории = оценка_модель (trainX, trainY) # кривые обучения summarize_diagnostics (истории) # подвести итоги расчетной производительности summarize_performance (баллы) # точка входа, запускаем тестовый жгут run_test_harness ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 14 18 19 20 21 22 23 24 25 26 27 28 29 30 3435 36 37 38 39 40 41 42 43 44 45 46 47 51 52 53 54 55 56 57 58 59 60 61 62 63 9 0005 6465 66 67 68 69 70 71 72 73 74 75 76 79 79 81 82 83 84 85 86 87 88 89 90 91 92 94 94 9798 99 100 101 102 103 104 105 106 107 108 109 110 | # cnn модель с пакетной нормализацией для mnist из numpy import mean из numpy import std из matplotlib import pyplot из sklearn.model_selection import KFold from keras.datasets import mnist from keras.utils import to_categorical from keras.models import Sequential from keras.layers import Conv2D from keras.layers import from keras. Dense из keras.layers import Flatten from keras.optimizers import SGD from keras.layers import BatchNormalization # load train and test dataset def load_dataset (): # load dataset (): # load dataset trainX, trainY), (testX, testY) = mnist.load_data () # преобразовать набор данных в один канал trainX = trainX.reshape ((trainX.shape [0], 28, 28, 1)) testX = testX.reshape ((testX.shape [0 ], 28, 28, 1)) # one целевые значения горячего кодирования trainY = to_categorical (trainY) testY = to_categorical (testY) return trainX, trainY, testX, testY # scale def Prep_pixels (train, test): # преобразовать целые числа в числа с плавающей запятой train_norm = train.astype ('float32') test_norm = test.astype ('float32') # нормализовать до диапазона 0-1 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # вернуть нормализованные изображения return train_norm, test_norm # define cnn model def define_model (): model = Sequential () model.add (Conv2D (32, (3, 3), activate = 'relu', kernel_initializer = ' he_uniform ', input_shape = (28, 28, 1))) модель.add (BatchNormalization ()) model.add (MaxPooling2D ((2, 2))) model.add (Flatten ()) model.add (Dense (100, активация = 'relu', kernel_initializer = ' he_uniform ')) model.add (BatchNormalization ()) model.add (Dense (10, activate =' softmax ')) # скомпилировать модель opt = SGD (lr = 0,01, импульс = 0,9) model.compile (optimizer = opt, loss ='ategorical_crossentropy ', metrics = [' precision ']) return model # оценить модель с помощью k-кратной перекрестной проверки def Assessment_model (dataX, dataY, n_folds = 5): баллов, history = list (), list () # подготовить перекрестную проверку kfold = KFold (n_folds, shuffle = True, random_state = 1) # перечислить разбиения для train_ix, test_ix в kfold.split (dataX): # определить модель model = define_model () # выбрать строки для обучения и тестирования trainX, trainY, testX, testY = dataX [train_ix], dataY [train_ix], dataX [test_ix] , dataY [test_ix] # fit model history = model.fit (trainX, trainY, epochs = 10, batch_size = 32, validation_data = (testX, testY), verbose = 0) # оценить модель _ , acc = model.evaluate (testX, testY, verbose = 0) print ('>%.3f '% (acc * 100.0)) # сохраняет оценки scores.append (acc) history.append (history) return scores, history # plot диагностические кривые обучения def summarize_diagnostics ( историй): для i в диапазоне (len (истории)): # потеря графика pyplot.subplot (2, 1, 1) pyplot.title ('Cross Entropy Loss') pyplot.plot (history [i] .history ['loss'], color = 'blue', label = 'train') pyplot.plot (history [i] .history ['val_loss'], color = 'orange', label = 'test') # точность графика pyplot.subplot (2, 1, 2) pyplot.title (' Точность классификации ') pyplot.plot (history [i] .history [' precision '], color =' blue ', label =' train ') pyplot.plot (history [i] .history [' val_accuracy ' ], color = 'orange', label = 'test') pyplot.show () # суммировать производительность модели def summarize_performance (scores): # print summary print ('Accuracy: mean знак равно3f std =%. 3f, n =% d '% (среднее (баллы) * 100, std (баллы) * 100, len (баллы))) # графики результатов в виде прямоугольников и усов pyplot.boxplot (баллы ) pyplot.show () # запустить тестовую программу для оценки модели def run_test_harness (): # загрузить набор данных trainX, trainY, testX, testY = load_dataset () пиксельные данные trainX, testX = Prep_pixels (trainX, testX) # оцените модель баллов, history = eval_model (trainX, trainY) # кривые обучения summarize_diagnostics (history) # суммируйте # суммируйте оценочную производительность summarize_performance (scores) # точка входа, запустить тестовую программу run_test_harness () |
Повторный запуск примера сообщает о производительности модели для каждого этапа процесса перекрестной проверки.
Примечание : Ваши результаты могут отличаться из-за стохастической природы алгоритма или процедуры оценки или различий в числовой точности. Попробуйте запустить пример несколько раз и сравните средний результат.
Мы можем увидеть, возможно, небольшое снижение производительности модели по сравнению с базовой линией во всех сегментах перекрестной проверки.
> 98,475 > 98,608 > 98,683 > 98,783 > 98,667
> 98.475 > 98,608 > 98,683 > 98,783 > 98,667 |
Создается график кривых обучения, в данном случае показывающий, что скорость обучения (улучшение по эпохам) не отличается от базовой модели.
Графики показывают, что пакетная нормализация, по крайней мере, реализованная в этом случае, не дает никаких преимуществ.
Кривые потерь и точности для модели BatchNormalization во время перекрестной проверки k-Fold
Далее представлена расчетная производительность модели, показывающая производительность с небольшим снижением средней точности модели: 98.643 по сравнению с 98,677 в базовой модели.
Точность: среднее значение = 98,643 стандартное отклонение = 0,101, n = 5
Точность: среднее = 98,643 стандартное = 0,101, n = 5 |
Ящик и усовидный график оценок точности для модели BatchNormalization, оцененной с использованием перекрестной проверки k-Fold
Увеличение глубины модели
Есть много способов изменить конфигурацию модели, чтобы изучить улучшения по сравнению с базовой моделью.
Два общих подхода включают изменение емкости части модели извлечения признаков или изменение емкости или функции части классификатора модели. Возможно, наибольшее влияние оказало изменение средства извлечения признаков.
Мы можем увеличить глубину части модели экстрактора признаков, следуя VGG-подобному шаблону добавления дополнительных сверточных и объединяющих слоев с фильтром того же размера, увеличивая при этом количество фильтров. В этом случае мы добавим двойной сверточный слой с 64 фильтрами каждый, а затем еще один слой максимального объединения.
Обновленная версия функции define_model () с этим изменением приведена ниже.
# определить модель cnn def define_model (): model = Последовательный () model.add (Conv2D (32, (3, 3), активация = 'relu', kernel_initializer = 'he_uniform', input_shape = (28, 28, 1))) model.add (MaxPooling2D ((2, 2))) model.add (Conv2D (64, (3, 3), активация = 'relu', kernel_initializer = 'he_uniform')) model.add (Conv2D (64, (3, 3), активация = 'relu', kernel_initializer = 'he_uniform')) модель.добавить (MaxPooling2D ((2, 2))) model.add (Сглаживание ()) model.add (Dense (100, активация = 'relu', kernel_initializer = 'he_uniform')) model.add (Плотный (10, активация = 'softmax')) # скомпилировать модель opt = SGD (lr = 0,01, импульс = 0,9) model.compile (optimizer = opt, loss = 'category_crossentropy', metrics = ['precision']) вернуть модель
# define cnn model def define_model (): model = Sequential () model.add (Conv2D (32, (3, 3), Activation = 'relu', kernel_initializer = 'he_uniform', input_shape = (28, 28, 1))) model.add (MaxPooling2D ((2, 2))) model.add (Conv2D (64, (3, 3), Activation = 'relu', kernel_initializer = 'he_uniform')) model.add (Conv2D (64, (3, 3), activate = 'relu' , kernel_initializer = 'he_uniform')) model.add (MaxPooling2D ((2, 2))) model.add (Flatten ()) model.add (Dense (100, активация = 'relu', kernel_initializer = 'he_uniform')) модель.add (Dense (10, activate = 'softmax')) # скомпилировать модель opt = SGD (lr = 0,01, импульс = 0,9) model.compile (optimizer = opt, loss = 'categoryorical_crossentropy', metrics = ['точность']) модель возврата |
Для полноты, ниже приведен полный листинг кода, включая это изменение.
# более глубокая модель cnn для mnist из среднего значения импорта из numpy import std из matplotlib import pyplot из склеарна.model_selection импорт KFold from keras.datasets import mnist from keras.utils import to_categorical из keras.models импортировать Последовательный из keras.layers импортировать Conv2D из keras.layers импорт MaxPooling2D из keras.layers import Плотный из keras.layers import Flatten от keras.optimizers импортные SGD # загрузить поезд и тестовый набор данных def load_dataset (): # загрузить набор данных (trainX, trainY), (testX, testY) = mnist.load_data () # преобразовать набор данных в один канал trainX = поездX.изменить форму ((trainX.shape [0], 28, 28, 1)) testX = testX.reshape ((testX.shape [0], 28, 28, 1)) # одно горячее кодирование целевых значений trainY = to_categorical (trainY) testY = to_categorical (testY) вернуть trainX, trainY, testX, testY # масштабный пиксель def Prep_pixels (поезд, тест): # преобразовать целые числа в числа с плавающей запятой train_norm = train.astype ('float32') test_norm = test.astype ('float32') # нормализовать до диапазона 0-1 train_norm = train_norm / 255.0 тест_норма = тест_норм / 255.0 # вернуть нормализованные изображения вернуть train_norm, test_norm # определить модель cnn def define_model (): model = Последовательный () model.add (Conv2D (32, (3, 3), активация = 'relu', kernel_initializer = 'he_uniform', input_shape = (28, 28, 1))) model.add (MaxPooling2D ((2, 2))) model.add (Conv2D (64, (3, 3), активация = 'relu', kernel_initializer = 'he_uniform')) model.add (Conv2D (64, (3, 3), активация = 'relu', kernel_initializer = 'he_uniform')) model.add (MaxPooling2D ((2, 2))) модель.добавить (Flatten ()) model.add (Dense (100, активация = 'relu', kernel_initializer = 'he_uniform')) model.add (Плотный (10, активация = 'softmax')) # скомпилировать модель opt = SGD (lr = 0,01, импульс = 0,9) model.compile (optimizer = opt, loss = 'category_crossentropy', metrics = ['precision']) модель возврата # оценить модель с помощью k-кратной перекрестной проверки def оценивать_модель (dataX, dataY, n_folds = 5): оценки, истории = список (), список () # подготовить перекрестную проверку kfold = KFold (n_folds, shuffle = True, random_state = 1) # перечислить разбиения для train_ix, test_ix в kfold.split (dataX): # определить модель модель = define_model () # выбираем строки для обучения и тестирования trainX, trainY, testX, testY = dataX [train_ix], dataY [train_ix], dataX [test_ix], dataY [test_ix] # подходящая модель history = model.fit (trainX, trainY, epochs = 10, batch_size = 32, validation_data = (testX, testY), verbose = 0) # оценить модель _, acc = model.evaluate (testX, testY, verbose = 0) print ('>% .3f'% (согласно * 100.0)) Результаты в # магазинах scores.append (acc) истории.добавить (история) вернуть оценки, истории # построить диагностические кривые обучения def summarize_diagnostics (истории): для i в диапазоне (len (истории)): # потеря сюжета pyplot.subplot (2, 1, 1) pyplot.title ('потеря перекрестной энтропии') pyplot.plot (history [i] .history ['loss'], color = 'blue', label = 'train') pyplot.plot (history [i] .history ['val_loss'], color = 'orange', label = 'test') # точность сюжета pyplot.subplot (2, 1, 2) pyplot.title ('Точность классификации') пиплот.сюжет (истории [i]. история ['точность'], цвет = 'синий', метка = 'поезд') pyplot.plot (history [i] .history ['val_accuracy'], color = 'orange', label = 'test') pyplot.show () # подвести итоги работы модели def summarize_performance (баллы): # распечатать сводку print ('Точность: среднее =%. 3f std =%. 3f, n =% d'% (среднее (баллы) * 100, стандартное (баллы) * 100, len (баллы))) # график результатов в виде квадратов и усов pyplot.boxplot (баллы) pyplot.show () # запускаем тестовую программу для оценки модели def run_test_harness (): # загрузить набор данных trainX, trainY, testX, testY = load_dataset () # подготовить данные пикселей trainX, testX = Prep_pixels (trainX, testX) # оценить модель оценки, истории = оценка_модель (trainX, trainY) # кривые обучения summarize_diagnostics (истории) # подвести итоги расчетной производительности summarize_performance (баллы) # точка входа, запускаем тестовый жгут run_test_harness ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 14 18 19 20 21 22 23 24 25 26 27 28 29 30 3435 36 37 38 39 40 41 42 43 44 45 46 47 51 52 53 54 55 56 57 58 59 60 61 62 63 9 0005 6465 66 67 68 69 70 71 72 73 74 75 76 79 79 81 82 83 84 85 86 87 88 89 90 91 92 94 94 9798 99 100 101 102 103 104 105 106 107 108 109 110 | # более глубокая модель cnn для mnist из numpy import mean из numpy import std из matplotlib import pyplot из sklearn.model_selection import KFold from keras.datasets import mnist from keras.utils import to_categorical from keras.models import Sequential from keras.layers import Conv2D from keras.layers import d max6 Denseиз keras.layers import Flatten from keras.optimizers import SGD # load train and test dataset def load_dataset (): # load dataset (trainX, trainY), (test testY) = mnist.load_data () # преобразовать набор данных в один канал trainX = trainX.reshape ((trainX.shape [0], 28, 28, 1)) testX = testX.reshape ((testX.shape [0 ], 28, 28, 1)) # one целевые значения горячего кодирования trainY = to_categorical (trainY) testY = to_categorical (testY) return trainX, trainY, testX, testY # scale def Prep_pixels (train, test): # преобразовать целые числа в числа с плавающей запятой train_norm = train.astype ('float32') test_norm = test.astype ('float32') # нормализовать до диапазона 0-1 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # вернуть нормализованные изображения return train_norm, test_norm # define cnn model def define_model (): model = Sequential () model.add (Conv2D (32, (3, 3), activate = 'relu', kernel_initializer = ' he_uniform ', input_shape = (28, 28, 1))) модель.add (MaxPooling2D ((2, 2))) model.add (Conv2D (64, (3, 3), Activation = 'relu', kernel_initializer = 'he_uniform')) model.add (Conv2D (64, (3, 3), Activation = 'relu', kernel_initializer = 'he_uniform')) model.add (MaxPooling2D ((2, 2))) model.add (Flatten ()) model.add ( Dense (100, Activation = 'relu', kernel_initializer = 'he_uniform')) model.add (Dense (10, activate = 'softmax')) # скомпилировать модель opt = SGD (lr = 0.01, импульс = 0,9) model.compile (optimizer = opt, loss ='ategorical_crossentropy ', metrics = [' precision ']) return model # оценить модель с помощью k-кратной перекрестной проверки def Assessment_model (dataX, dataY, n_folds = 5): баллов, history = list (), list () # подготовить перекрестную проверку kfold = KFold (n_folds, shuffle = True, random_state = 1) # перечислить разбиения для train_ix, test_ix в kfold.split (dataX): # определить модель model = define_model () # выбрать строки для обучения и тестирования trainX, trainY, testX, testY = dataX [train_ix], dataY [train_ix], dataX [test_ix] , dataY [test_ix] # fit model history = model.fit (trainX, trainY, epochs = 10, batch_size = 32, validation_data = (testX, testY), verbose = 0) # оценить модель _ , acc = model.evaluate (testX, testY, verbose = 0) print ('>%.3f '% (acc * 100.0)) # сохраняет оценки scores.append (acc) history.append (history) return scores, history # plot диагностические кривые обучения def summarize_diagnostics ( историй): для i в диапазоне (len (истории)): # потеря графика pyplot.subplot (2, 1, 1) pyplot.title ('Cross Entropy Loss') pyplot.plot (history [i] .history ['loss'], color = 'blue', label = 'train') pyplot.plot (history [i] .history ['val_loss'], color = 'orange', label = 'test') # точность графика pyplot.subplot (2, 1, 2) pyplot.title (' Точность классификации ') pyplot.plot (history [i] .history [' precision '], color =' blue ', label =' train ') pyplot.plot (history [i] .history [' val_accuracy ' ], color = 'orange', label = 'test') pyplot.show () # суммировать производительность модели def summarize_performance (scores): # print summary print ('Accuracy: mean знак равно3f std =%. 3f, n =% d '% (среднее (баллы) * 100, std (баллы) * 100, len (баллы))) # графики результатов в виде прямоугольников и усов pyplot.boxplot (баллы ) pyplot.show () # запустить тестовую программу для оценки модели def run_test_harness (): # загрузить набор данных trainX, trainY, testX, testY = load_dataset () пиксельные данные trainX, testX = Prep_pixels (trainX, testX) # оцените модель баллов, history = eval_model (trainX, trainY) # кривые обучения summarize_diagnostics (history) # суммируйте # суммируйте оценочную производительность summarize_performance (scores) # точка входа, запустить тестовую программу run_test_harness () |
Запуск примера показывает производительность модели для каждого этапа процесса перекрестной проверки.
Примечание : Ваши результаты могут отличаться из-за стохастической природы алгоритма или процедуры оценки или различий в числовой точности. Попробуйте запустить пример несколько раз и сравните средний результат.
Оценка на кратность может указывать на некоторое улучшение по сравнению с исходным уровнем.
> 99,058 > 99,042 > 98,883 > 99,192 > 99,133
> 99.058 > 99.042 > 98.883 > 99.192 > 99.133 |
Создается график кривых обучения, в данном случае показывающий, что модели по-прежнему хорошо подходят для задачи без явных признаков переобучения. Сюжеты могут даже предполагать, что дальнейшие тренировочные эпохи могут быть полезны.
Кривые потерь и обучения точности для более глубокой модели во время перекрестной проверки k-Fold
Далее представлена расчетная производительность модели, показывающая небольшое улучшение производительности по сравнению с базовой версией 98.От 677 до 99,062, с небольшим падением стандартного отклонения.
Точность: среднее значение = 99,062 стандартное отклонение = 0,104, n = 5
Точность: среднее = 99,062 стандартное = 0,104, n = 5 |
Ящик и диаграмма усов для оценок точности для более глубокой модели, оцененных с помощью перекрестной проверки k-Fold
Как завершить модель и сделать прогнозы
Процесс улучшения модели может продолжаться до тех пор, пока у нас есть идеи, а также время и ресурсы для их проверки.
В какой-то момент должна быть выбрана и принята окончательная конфигурация модели. В этом случае мы выберем более глубокую модель в качестве нашей окончательной модели.
Сначала мы завершим нашу модель, но подгоним модель ко всему набору обучающих данных и сохраним модель в файл для дальнейшего использования. Затем мы загрузим модель и оценим ее производительность на имеющемся тестовом наборе данных, чтобы получить представление о том, насколько хорошо выбранная модель действительно работает на практике. Наконец, мы будем использовать сохраненную модель, чтобы сделать прогноз на одном изображении.
Сохранить окончательную модель
Окончательная модель обычно подходит для всех доступных данных, таких как комбинация всех наборов данных для поездов и тестов.
В этом руководстве мы намеренно удерживаем тестовый набор данных, чтобы мы могли оценить производительность окончательной модели, что может быть хорошей идеей на практике. Таким образом, мы подгоним нашу модель только к набору обучающих данных.
# подходящая модель model.fit (trainX, trainY, epochs = 10, batch_size = 32, verbose = 0)
# подходит модель модель.fit (trainX, trainY, эпохи = 10, размер_пакета = 32, подробный = 0) |
После подгонки мы можем сохранить окончательную модель в файл H5, вызвав для модели функцию save () и передав выбранное имя файла.
# сохранить модель model.save ('final_model.h5')
# save model model.save ('final_model.h5') |
Обратите внимание, что для сохранения и загрузки модели Keras требуется, чтобы на вашей рабочей станции была установлена библиотека h5py.
Полный пример подгонки окончательной глубинной модели к набору обучающих данных и ее сохранения в файл приведен ниже.
# сохраняем окончательную модель в файл from keras.datasets import mnist from keras.utils import to_categorical из keras.models импортировать Последовательный из keras.layers импортировать Conv2D из keras.layers импорт MaxPooling2D из keras.layers import Плотный из keras.layers import Flatten от keras.optimizers импортные SGD # загрузить поезд и тестовый набор данных def load_dataset (): # загрузить набор данных (trainX, trainY), (testX, testY) = mnist.load_data () # преобразовать набор данных в один канал trainX = trainX.reshape ((trainX.shape [0], 28, 28, 1)) testX = testX.reshape ((testX.shape [0], 28, 28, 1)) # одно горячее кодирование целевых значений trainY = to_categorical (trainY) testY = to_categorical (testY) вернуть trainX, trainY, testX, testY # масштабный пиксель def Prep_pixels (поезд, тест): # преобразовать целые числа в числа с плавающей запятой train_norm = train.astype ('float32') test_norm = test.astype ('float32') # нормализовать до диапазона 0-1 поезд_норм = поезд_норм / 255.0 test_norm = test_norm / 255.0 # вернуть нормализованные изображения вернуть train_norm, test_norm # определить модель cnn def define_model (): model = Последовательный () model.add (Conv2D (32, (3, 3), активация = 'relu', kernel_initializer = 'he_uniform', input_shape = (28, 28, 1))) model.add (MaxPooling2D ((2, 2))) model.add (Conv2D (64, (3, 3), активация = 'relu', kernel_initializer = 'he_uniform')) model.add (Conv2D (64, (3, 3), активация = 'relu', kernel_initializer = 'he_uniform')) модель.добавить (MaxPooling2D ((2, 2))) model.add (Сглаживание ()) model.add (Dense (100, активация = 'relu', kernel_initializer = 'he_uniform')) model.add (Плотный (10, активация = 'softmax')) # скомпилировать модель opt = SGD (lr = 0,01, импульс = 0,9) model.compile (optimizer = opt, loss = 'category_crossentropy', metrics = ['precision']) модель возврата # запускаем тестовую программу для оценки модели def run_test_harness (): # загрузить набор данных trainX, trainY, testX, testY = load_dataset () # подготовить данные пикселей trainX, testX = Prep_pixels (trainX, testX) # определить модель модель = define_model () # подходящая модель модель.fit (trainX, trainY, эпохи = 10, размер_пакета = 32, подробный = 0) # сохранить модель model.save ('final_model.h5') # точка входа, запускаем тестовый жгут run_test_harness ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 14 18 19 20 21 22 23 24 25 26 27 28 29 30 3435 36 37 38 39 40 41 42 43 44 45 46 47 51 52 53 54 55 56 57 58 59 60 61 62 63 9 0005 64 | # сохраняем окончательную модель в файл из keras.наборы данных import mnist from keras.utils import to_categorical from keras.models import Sequential from keras.layers import Conv2D from keras.layers import MaxPooling2D from keras.layers import Dense5 Flatten из keras.optimizers import SGD # загрузить поезд и тестовый набор данных def load_dataset (): # загрузить набор данных (trainX, trainY), (testX, testY) = mnist.load_data () # преобразовать набор данных в один канал trainX = trainX.reshape ((trainX.shape [0], 28, 28, 1)) testX = testX.reshape ((testX.shape [0 ], 28, 28, 1)) # one целевые значения горячего кодирования trainY = to_categorical (trainY) testY = to_categorical (testY) return trainX, trainY, testX, testY # scale def Prep_pixels (train, test): # преобразовать целые числа в числа с плавающей запятой train_norm = train.astype ('float32') test_norm = test.astype ('float32') # нормализовать до диапазона 0-1 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # вернуть нормализованные изображения return train_norm, test_norm # define cnn model def define_model (): model = Sequential () model.add (Conv2D (32, (3, 3), activate = 'relu', kernel_initializer = ' he_uniform ', input_shape = (28, 28, 1))) модель.add (MaxPooling2D ((2, 2))) model.add (Conv2D (64, (3, 3), Activation = 'relu', kernel_initializer = 'he_uniform')) model.add (Conv2D (64, (3, 3), Activation = 'relu', kernel_initializer = 'he_uniform')) model.add (MaxPooling2D ((2, 2))) model.add (Flatten ()) model.add ( Dense (100, Activation = 'relu', kernel_initializer = 'he_uniform')) model.add (Dense (10, activate = 'softmax')) # скомпилировать модель opt = SGD (lr = 0.01, импульс = 0,9) model.compile (optimizer = opt, loss ='ategorical_crossentropy ', metrics = [' precision ']) return model # запустить тестовый набор для оценки модели def run_test_harness (): # загрузить набор данных trainX, trainY, testX, testY = load_dataset () # подготовить данные пикселей trainX, testX = Prep_pixels (trainX, testX) # определить модель model5 () # подходит модель модель.fit (trainX, trainY, epochs = 10, batch_size = 32, verbose = 0) # save model model.save ('final_model.h5') # entry point, run the test harness run_test_harness () |
После выполнения этого примера в вашем текущем рабочем каталоге будет файл размером 1,2 мегабайта с именем « final_model.h5 ».
Оценка окончательной модели
Теперь мы можем загрузить окончательную модель и оценить ее на имеющемся тестовом наборе данных.
Это то, что мы могли бы сделать, если бы были заинтересованы в представлении эффективности выбранной модели заинтересованным сторонам проекта.
Модель может быть загружена с помощью функции load_model () .
Полный пример загрузки сохраненной модели и ее оценки в тестовом наборе данных приведен ниже.
# оценить глубинную модель на тестовом наборе данных from keras.datasets import mnist из keras.models импортировать load_model из кераса.utils import to_categorical # загрузить поезд и тестовый набор данных def load_dataset (): # загрузить набор данных (trainX, trainY), (testX, testY) = mnist.load_data () # преобразовать набор данных в один канал trainX = trainX.reshape ((trainX.shape [0], 28, 28, 1)) testX = testX.reshape ((testX.shape [0], 28, 28, 1)) # одно горячее кодирование целевых значений trainY = to_categorical (trainY) testY = to_categorical (testY) вернуть trainX, trainY, testX, testY # масштабный пиксель def Prep_pixels (поезд, тест): # преобразовать целые числа в числа с плавающей запятой train_norm = поезд.astype ('float32') test_norm = test.astype ('float32') # нормализовать до диапазона 0-1 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # вернуть нормализованные изображения вернуть train_norm, test_norm # запускаем тестовую программу для оценки модели def run_test_harness (): # загрузить набор данных trainX, trainY, testX, testY = load_dataset () # подготовить данные пикселей trainX, testX = Prep_pixels (trainX, testX) # модель нагрузки model = load_model ('final_model.h5 ') # оценить модель на тестовом наборе данных _, acc = model.evaluate (testX, testY, verbose = 0) print ('>% .3f'% (согласно * 100.0)) # точка входа, запускаем тестовый жгут run_test_harness ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 14 18 19 20 21 22 23 24 25 26 27 28 29 30 3435 36 37 38 39 40 41 42 | # оценить глубокую модель на тестовом наборе данных от keras.наборы данных import mnist from keras.models import load_model from keras.utils import to_categorical # load train and test dataset def load_dataset (): # load dataset ( ) testX, testY) = mnist.load_data ()# преобразовать набор данных в один канал trainX = trainX.reshape ((trainX.shape [0], 28, 28, 1)) testX = testX.reshape ((testX.shape [0], 28, 28, 1)) # целевые значения one hot encode trainY = to_categorical (trainY) testY = to_categorical (testY) return trainX, trainY, testX, testY # масштабировать пиксели def Prep_pixels (train, test): # преобразовать из целых чисел в числа с плавающей запятой train_norm = train.astype ('float32') test_norm = test.astype ('float32') # нормализовать до диапазона 0-1 train_norm = train_norm / 255.0 test_norm = test_norm / 255.0 # вернуть нормализованные изображения return train_norm, test_norm # запустить тестовую программу для оценки модели def run_test_harness (): # загрузить набор данных trainX, trainY, testX, testY = load_dataset () # подготовить данные пикселей , testX = Prep_pixels (trainX, testX)# загрузить модель model = load_model ('final_model.h5 ') # оценить модель в наборе тестовых данных _, acc = model.evaluate (testX, testY, verbose = 0) print ('>% .3f '% (acc * 100.0)) # точка входа, запускаем тестовый жгут run_test_harness () |
При выполнении примера загружается сохраненная модель и оценивается модель в удерживаемом наборе тестовых данных.
Примечание : Ваши результаты могут отличаться из-за стохастической природы алгоритма или процедуры оценки или различий в числовой точности.Попробуйте запустить пример несколько раз и сравните средний результат.
Вычисляется и распечатывается точность классификации модели в тестовом наборе данных. В этом случае мы видим, что модель достигла точности 99,090% или чуть меньше 1%, что совсем неплохо и достаточно близко к расчетным 99,753% со стандартным отклонением около половины процента (например, 99 % баллов).
Сделать прогноз
Мы можем использовать нашу сохраненную модель, чтобы делать прогнозы на новых изображениях.
Модель предполагает, что новые изображения имеют оттенки серого, что они были выровнены так, что одно изображение содержит одну центрированную рукописную цифру, и что размер изображения квадратный с размером 28 × 28 пикселей.
Ниже приведено изображение, извлеченное из тестового набора данных MNIST. Вы можете сохранить его в текущем рабочем каталоге с именем файла « sample_image.png ».
Пример рукописной цифры
Мы представим, что это совершенно новое и невидимое изображение, подготовленное должным образом, и посмотрим, как мы можем использовать нашу сохраненную модель, чтобы предсказать целое число, которое представляет изображение (например,грамм. мы ожидаем « 7 »).
Во-первых, мы можем загрузить изображение, заставить его быть в формате оттенков серого и установить размер 28 × 28 пикселей. Затем загруженное изображение может быть изменено, чтобы иметь один канал и представлять одну выборку в наборе данных. Функция load_image () реализует это и возвращает загруженное изображение, готовое для классификации.
Важно отметить, что значения пикселей подготавливаются таким же образом, как значения пикселей были подготовлены для обучающего набора данных при подгонке окончательной модели, в данном случае нормализованной.
# загрузить и подготовить изображение def load_image (имя файла): # загрузить изображение img = load_img (имя файла, оттенки серого = True, target_size = (28, 28)) # преобразовать в массив img = img_to_array (img) # преобразовать в один сэмпл с 1 каналом img = img.reshape (1, 28, 28, 1) # подготовить данные пикселей img = img.astype ('float32') img = img / 255,0 вернуть img
# загрузить и подготовить изображение def load_image (filename): # загрузить изображение img = load_img (filename, grayscale = True, target_size = (28, 28)) # преобразовать в массив img = img_to_array (img) # преобразовать в один образец с 1 каналом img = img.reshape (1, 28, 28, 1) # подготовить данные пикселей img = img.astype ('float32') img = img / 255.0 return img |
Затем мы можем загрузить модель, как в предыдущем разделе, и вызвать функцию pred_classes () , чтобы предсказать цифру, которую представляет изображение.
# предсказать класс digit = model.predict_classes (img)
# прогнозировать класс цифр = модель.pred_classes (img) |
Полный пример приведен ниже.
# сделать прогноз для нового изображения. из keras.preprocessing.image import load_img из keras.preprocessing.image import img_to_array из keras.models импортировать load_model # загрузить и подготовить изображение def load_image (имя файла): # загрузить изображение img = load_img (имя файла, оттенки серого = True, target_size = (28, 28)) # преобразовать в массив img = img_to_array (img) # преобразовать в один сэмпл с 1 каналом img = img.изменить форму (1, 28, 28, 1) # подготовить данные пикселей img = img.astype ('float32') img = img / 255,0 вернуть img # загружаем изображение и прогнозируем класс def run_example (): # загрузить изображение img = load_image ('sample_image.png') # модель нагрузки модель = load_model ('final_model.h5') # предсказать класс digit = model.predict_classes (img) печать (цифра [0]) # точка входа, запустим пример run_example ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 14 18 19 20 21 22 23 24 25 26 27 28 29 30 | # сделать прогноз для нового изображения. из keras.preprocessing.image import load_img из keras.preprocessing.image import img_to_array из keras.models import load_model # загрузить и подготовить изображение def load_image (имя файла) def load_image изображение img = load_img (filename, grayscale = True, target_size = (28, 28)) # преобразовать в массив img = img_to_array (img) # преобразовать в один образец с 1 каналом img = img.reshape (1, 28, 28, 1) # подготовить данные пикселей img = img.astype ('float32') img = img / 255.0 return img # загрузить изображение и спрогнозировать class def run_example (): # загрузить изображение img = load_image ('sample_image.png') # загрузить модель model = load_model ('final_model.h5') # предсказать класс digit = model.predict_classes (img) print (digit [0]) # точка входа, запустите пример run_example () |
При выполнении примера сначала загружается и подготавливается изображение, загружается модель, а затем правильно прогнозируется, что загруженное изображение представляет собой цифру « 7 ».
Расширения
В этом разделе перечислены некоторые идеи по расширению учебника, которые вы, возможно, захотите изучить.
- Настроить масштабирование пикселей . Узнайте, как альтернативные методы масштабирования пикселей влияют на производительность модели по сравнению с базовой моделью, включая центрирование и стандартизацию.
- Настройте скорость обучения . Узнайте, как разные скорости обучения влияют на производительность модели по сравнению с базовой моделью, например 0,001 и 0.0001.
- Глубина настройки модели . Изучите, как добавление дополнительных слоев к модели влияет на производительность модели по сравнению с базовой моделью, такой как другой блок сверточных и объединяющих слоев или другой плотный слой в части классификатора модели.
Если вы изучите какое-либо из этих расширений, я хотел бы знать.
Разместите свои выводы в комментариях ниже.
Дополнительная литература
В этом разделе представлены дополнительные ресурсы по теме, если вы хотите углубиться.
API
Статьи
Сводка
В этом руководстве вы узнали, как с нуля разработать сверточную нейронную сеть для классификации рукописных цифр.
В частности, вы выучили:
- Как разработать тестовую программу для разработки надежной оценки модели и установления базового уровня производительности для задачи классификации.
- Как изучить расширения базовой модели для улучшения обучения и возможностей модели.
- Как разработать окончательную модель, оценить производительность окончательной модели и использовать ее для прогнозирования новых изображений.
Есть вопросы?
Задайте свои вопросы в комментариях ниже, и я постараюсь ответить.
Разрабатывайте модели глубокого обучения для Vision сегодня!
Развивайте свои собственные модели видения за считанные минуты
... всего несколькими строками кода Python
Узнайте, как в моей новой электронной книге:
Deep Learning for Computer Vision
Он предоставляет руководств для самообучения по таким темам, как:
классификация , обнаружение объектов (yolo и rcnn) , распознавание лиц (vggface и facenet) , подготовка данных и многое другое...
Наконец-то привнесите глубокое обучение в ваши проекты видения
Пропустить академики. Только результаты.
Посмотрите, что внутриКлассификация сильных сторон и добродетелей характера
«Сильные стороны и добродетели характера» - это новаторское руководство, в котором собраны результаты работы исследователей по созданию системы классификации широко ценимых положительных качеств.
Это руководство также призвано предоставить эмпирическую теоретическую основу, которая поможет практикующим позитивным психологам в разработке практических приложений в этой области.
Есть 6 классов добродетелей, состоящих из 24 сильных сторон персонажа:
- Мудрость и знания
- Мужество
- Человечество
- Правосудие
- Умеренность
- Превосходство
Исследователи подошли к измерению «хорошего характера», основываясь на сильных сторонах подлинности, настойчивости, доброты, благодарности, надежды, юмора и многого другого.
Прежде чем вы продолжите, мы подумали, что вы можете бесплатно загрузить наши три упражнения на развитие сильных сторон.Эти подробные научно обоснованные упражнения помогут вам или вашим клиентам реализовать свой уникальный потенциал и создать жизнь, наполненную энергией и подлинную.
Что делает нас сильными и добродетельными?
Культуры всего мира высоко ценят изучение человеческой силы и добродетели. Психологи проявляют к нему особый интерес, поскольку они работают над тем, чтобы побудить людей развивать эти качества. В то время как все культуры ценят человеческие добродетели, разные культуры выражают добродетели или действуют в соответствии с ними по-разному, основываясь на различных социальных ценностях и нормах.
Мартин Селигман и его коллеги изучили все основные религии и философские традиции и обнаружили, что одни и те же шесть добродетелей (то есть храбрость, гуманность, справедливость и т. Д.) Были общими практически во всех культурах на протяжении трех тысячелетий.
Поскольку эти добродетели считаются слишком абстрактными, чтобы их можно было изучать с научной точки зрения, практики позитивной психологии сосредоточили свое внимание на сильных сторонах характера, созданных добродетелями, и создали инструменты для их измерения.
Основными инструментами оценки, которые они использовали для измерения этих сильных сторон, были:
- Структурированные интервью
- Анкеты
- Отчеты информатора
- Поведенческие эксперименты
- Наблюдения
Основными критериями сильных сторон персонажей, которые они придумали, является то, что каждая черта должна:
- Будьте стабильны во времени и ситуациях
- Оцениваться самостоятельно, даже при отсутствии других преимуществ
- Быть признанным и ценным почти в каждой культуре, считаться непротиворечивым и независимым от политики.
- Культуры предоставляют образцы для подражания, обладающие этой чертой, чтобы другие люди могли признать ее ценность.
- Родители стремятся привить детям эти качества или ценности.
Список
Справочника CSVСправочник углубляется в каждую из этих шести черт. Здесь мы суммировали ключевые моменты.
1. Добродетель мудрости и знания
Чем более любопытными и творческими мы позволяем себе стать, тем больше мы обретаем перспективу и мудрость и, в свою очередь, будем любить то, что изучаем.Это развивает мудрость и знания.
Сильные стороны, которые сопровождают эту добродетель, включают приобретение и использование знаний:
- Творчество (например, творчество Альберта Эйнштейна привело его к приобретению знаний и мудрости о Вселенной)
- Любопытство
- Открытость
- Любовь к учебе
- Перспектива и мудрость (Интересный факт: многие исследования показали, что самооценка взрослых людей в отношении точки зрения и мудрости не зависит от возраста, что противоречит популярной идее о том, что наша мудрость увеличивается с возрастом).
2. Мужество
Чем смелее и настойчивее мы станем, тем больше будет расти наша целостность, потому что мы достигнем состояния жизненных сил, а это приведет к более смелому характеру.
Сильные стороны, которые сопровождают эту добродетель, включают достижение целей вопреки вещам, которые ей противостоят:
- Храбрость
- Стойкость
- Целостность
- Живучесть
3.Добродетель человечества
Есть причина, по которой Опра Уинфри рассматривается как символ добродетели для гуманитариев: на каждом шоу она подходит к своим гостям с уважением, признательностью и интересом (социальный интеллект), она проявляет доброту через свою благотворительную деятельность и показывает свое любовь к ее друзьям и семье.
Сильные стороны, которые сопровождают эту добродетель, включают заботу о других и дружбу с ними:
- Любовь
- Доброта
- Социальный интеллект
4.Добродетель правосудия
Махатма Ганди был лидером движения за независимость Индии в управляемой британцами Индии. Он привел Индию к независимости и помог создать движения за гражданские права и свободу, будучи активным гражданином в ненасильственном неповиновении. Его работы получили признание во всем мире благодаря своей универсальности.
Сильные стороны, которые сопровождают эту добродетель, включают те, которые создают здоровое и стабильное сообщество:
- Быть активным гражданином, социально ответственным, лояльным и членом коллектива.
- Справедливость
- Лидерство
5. Добродетель воздержания
Проявляя снисходительность, милосердие, смирение, рассудительность и способность контролировать свое поведение и инстинкты, мы не позволяем нам быть высокомерными, эгоистичными или любыми другими чертами, которые являются чрезмерными или неуравновешенными.
Сильные стороны, которые включены в это достоинство, - это те, которые защищают от излишеств:
- Прощение и милосердие
- Смирение и скромность
- Пруденс
- Саморегуляция и самоконтроль
6.Превосходная добродетель
Далай-лама - трансцендентное существо, которое открыто говорит, почему он никогда не теряет надежды на человеческий потенциал. Он также ценит природу в ее совершенстве и живет в соответствии с тем, что, по его мнению, является его предполагаемой целью.
Сильные стороны, которые сопровождают эту добродетель, включают те, которые налаживают связи с большой вселенной и придают значение:
- Признание красоты и совершенства
- Благодарность
- Надежда
- Юмор и игривость
- Духовность или целеустремленность
Позитивная психология и сильные стороны и добродетели характера
Практики позитивной психологии могут рассчитывать на практическое применение, которое поможет отдельным лицам и организациям выявить свои сильные стороны и использовать их для повышения и поддержания своего уровня благополучия.
Они также подчеркивают, что эти сильные стороны характера существуют непрерывно; положительные черты рассматриваются как индивидуальные различия, которые существуют в степени, а не в категориях "все или ничего".
Фактически, у справочника есть внутренний подзаголовок, озаглавленный «Руководство по здравомыслию», потому что он предназначен для психологического благополучия того же, что DSM делает для психологических расстройств: для добавления систематических знаний и способов овладения новыми навыками и темами.
Исследования показывают, что эти сильные стороны человека могут действовать как буфер против психических заболеваний.Например, оптимизм предотвращает попадание в депрессию. Отсутствие определенных сильных сторон может быть признаком психопатологии. Психотерапевты, консультанты, тренеры и представители других психологических профессий используют эти новые методы и техники, чтобы помочь людям укрепить свои силы и расширить их жизнь.
Следует отметить, что многие исследователи рекомендуют сгруппировать эти 24 черты всего в четыре класса силы (интеллектуальная, социальная, умеренность и трансцендентность) или даже три класса (исключая трансцендентность), поскольку данные показывают, что эти классы выполняют адекватную работу. захвата всех 24 оригинальных черт.
Другие предупреждают, что люди иногда чрезмерно используют эти черты, что может стать обузой для человека. Например, некоторые люди могут использовать юмор как защитный механизм, чтобы избежать трагедии или комы.
Какие сильные стороны у женщин выше?
Есть интерес к выявлению доминирующих сильных сторон характера у мужчин и женщин и к тому, как они проявляются.
Поскольку Мартин Селигман и его коллеги изучали все основные религии и философские традиции, чтобы найти универсальные добродетели, большая часть исследований гендерных и сильных сторон характера также была межкультурной.
В исследовании Brdar, Anic и Rijavec, посвященном гендерным различиям и сильным сторонам характера, женщины получили самые высокие оценки по таким сильным сторонам, как честность, доброта, любовь, благодарность и справедливость.
Удовлетворенность жизнью женщин была предсказана энтузиазмом, благодарностью, надеждой, признательностью к красоте / совершенству и любовью к другим женщинам. Недавнее исследование Манна показало, что женщины, как правило, получают больше благодарностей, чем мужчины. Алекс Линли и его коллеги сообщили в британском исследовании, что женщины имеют более высокие показатели не только в межличностных отношениях, таких как любовь и доброта, но и в социальном интеллекте.
В кросс-культурном исследовании, проведенном Овехеро и Карденалом в Испании, они обнаружили, что женственность положительно коррелирует с любовью, социальным интеллектом, признанием красоты, любовью к учебе, прощением, духовностью и творчеством. Чем более мужественным был мужчина, тем сильнее он коррелировал с этими сильными сторонами характера.
Какие сильные стороны у мужчин выше?
Brdar, Anic & Rijavac сообщили, что мужчины получают самые высокие оценки за честность, надежду, юмор, благодарность и любопытство.
Их удовлетворенность жизнью была предсказана творчеством, перспективой, справедливостью и юмором. Исследование Алекса Линли и его коллег показало, что мужчины набирают больше креативности, чем женщины.
Исследование Милькович и Риявец выявило половые различия в выборке студентов колледжа. Мужчины показали больше не только творческих способностей, но также лидерских качеств, самообладания и энтузиазма. Эти результаты согласуются с гендерными стереотипами, поскольку исследование Овехеро и Карденала в Испании показало, что мужчины не приравнивают типичные мужские сильные стороны к любви, прощению, любви к учебе и так далее.
В хорватской выборке Брдар и его коллеги обнаружили, что мужчины рассматривают когнитивные способности как лучший показатель удовлетворенности жизнью. Мужчины видели такие сильные стороны, как командная работа, доброта, перспективность и смелость, как более сильную связь с удовлетворением жизнью, чем другие сильные стороны. У этой выборки есть важное ограничение, так как большинство участников были женщинами.
Чему мы можем научиться у обоих?
Хотя есть различия в сильных сторонах характера между мужчинами и женщинами, есть много их общих черт.Оба пола считали, что благодарность, надежда и энтузиазм связаны с более высоким уровнем удовлетворенности жизнью, а также со стремлением жить в соответствии с сильными сторонами, которые ценятся в их конкретной культуре.
Исследования подтверждают, что существует двойственность между полами, но только тогда, когда оба пола четко идентифицируются с гендерными стереотипами. Это заставляет задуматься, являются ли мужчины и женщины от рождения с определенными сильными сторонами, или же культурное влияние определенных черт ставит во главу угла разные черты, основанные на гендерных нормах.
Узнайте больше о тестах на сильные и слабые стороны здесь.
Развитие сильных сторон характера у детей
Петерсон и Селигман в справочнике «Сильные стороны характера в действии» (2004) предположили, что некоторые маленькие дети нечасто демонстрируют благодарность, открытость, искренность и прощение.Дети и сильные стороны. Изображение Шерил Холт на Pixaby.
Исследование Парка и Петерсона (2006) подтвердило это теоретическое предположение, сделав вывод о том, что эти сложные сильные стороны характера обычно требуют определенной степени когнитивного созревания, которая развивается в подростковом возрасте.Таким образом, хотя благодарность ассоциируется со счастьем в подростковом и взрослом возрасте, это не относится к маленьким детям.
Исследование Парка и Петерсона показало, что чувство благодарности и счастья начинается с семи лет.
«Благодарность рассматривается как человеческая сила, которая повышает личное благополучие и благополучие в отношениях и приносит пользу обществу в целом».
Зиммель
Хотя большинство детей младшего возраста еще недостаточно когнитивно зрелы для сложных сильных сторон характера, есть много фундаментальных сильных сторон характера, которые развиваются на очень ранней стадии.
Сила любви, энтузиазма и надежды ассоциируется со счастьем с самого раннего возраста. Сила любви и надежды зависит от взаимоотношений младенца и опекуна. Надежная привязанность к опекуну в младенчестве с большей вероятностью приведет к психологической и социальной адаптации на протяжении всей жизни.
Воспитание ребенка играет важную роль в его развитии, а ролевое моделирование - важный способ научить ребенка определенным сильным сторонам характера, поскольку они имитируют поведение и затем могут принять эту силу как свою собственную.
Большинство детей младшего возраста не обладают когнитивной зрелостью, чтобы проявлять благодарность, но обладают способностью выражать любовь и надежду. Следовательно, от маленького ребенка нельзя ожидать благодарности, ее нужно учить.
Позитивные образовательные программы были разработаны, чтобы помочь детям и подросткам сосредоточиться на сильных сторонах характера. У подростков есть определенные сильные стороны характера, которые более отчетливо влияют на психологическое благополучие. Эти сильные стороны необходимо развивать, чтобы обеспечить удовлетворение и удовлетворение на всю жизнь.
«На сильные стороны характера влияют семья, сообщество, социальные и другие контекстуальные факторы. По крайней мере теоретически, сильные стороны характера податливы; их можно научить и усвоить на практике ».
Gillham, et al.
Сильные стороны характера и благополучие подростков
Сегодня большая часть исследований сильных сторон характера сосредоточена на взрослых, несмотря на известную важность детства и юности для развития характера.
Исследование сильных сторон характера показывает, что способствует позитивному развитию и предотвращает психопатологию.
Дальсгаард, Парк и Петерсон обнаружили, что подростки с более высоким уровнем энтузиазма, надежды и лидерства демонстрируют более низкий уровень тревожности и депрессии по сравнению с их сверстниками с более низким уровнем этих сильных сторон. Другие результаты исследования показали, что сильные стороны характера подростка способствуют благополучию (Gillham, et al, 2011).
Исследование предполагает, что трансцендентность (напр.благодарность, смысл и надежда) предсказывает удовлетворение жизнью, демонстрируя важность развития подростками позитивных отношений, создания мечтаний и обретения чувства цели.
VIA Опрос молодежи о сильных сторонах характера
Родители, учителя и исследователи обратились в VIA: институт сильных сторон характера с просьбой разработать исследование VIA, специально предназначенное для молодежи. Если вам от 10 до 17 лет, возьмите психометрические данные VIA - опрос молодежи.
Заключение
Измерение сильных сторон характера и различных черт, которые их формируют, имеет множество применений, от удовлетворенности жизнью до счастья и других показателей благополучия. Эти инструменты измерения использовались для изучения того, как эти сильные стороны развивались в разных гендерных и возрастных группах.
Какими сильными сторонами вы обладаете? Какое значение, по вашему мнению, может иметь это исследование в современном мире? Вы видите, как это применимо к вашей жизни?
Пожалуйста, поделитесь своими мыслями в разделе комментариев ниже.
Видео о сильных сторонах характера
В заключение, вот несколько полезных видео, которые могут вам понравиться, если вы хотите узнать больше о сильных сторонах и достоинствах персонажей:
Надеемся, вам понравилась эта статья. Не забудьте бесплатно скачать наши три упражнения на развитие сильных сторон.
Если вы хотите помочь большему количеству людей реализовать свои сильные стороны, наш Мастер-класс по максимальному использованию сильных сторон © представляет собой комплексный шаблон обучения, который содержит все необходимое, чтобы стать практиком, основанным на силе, и помочь другим выявить и развить свои уникальные качества таким образом, чтобы оптимальное функционирование.
- Bowlby, J. (1969). Пристрастие и потеря , (Том I). Вложение . Основные книги, Нью-Йорк.
- Дальсгаард, К.К. (2005). Неужели добродетель больше, чем сама награда? Сильные стороны характера и их связь с благополучием в проспективном продольном исследовании подростков среднего школьного возраста (неопубликованная докторская диссертация) . Пенсильванский университет, Филадельфия, Пенсильвания.
- Gillham, J., Adams-Deutsch, Z., Werner, J., Reivich, K., Coulter-Heindl, V., Линкинс, М., Селигман, М. (2011). Сильные стороны характера предсказывают субъективное благополучие в подростковом возрасте. Журнал позитивной психологии , 6 (1), 31-44.
- Jolly, M., & Academia. (2006). Позитивная психология: наука о человеческих силах . Получено с https://www.academia.edu/6442081/Positive_Psychology_The_Science_of_Human_Strengths .
- Кочанская, Г. (2001). Эмоциональное развитие у детей с разным анамнезом привязанности: первые три года. Психология развития 72, стр. 474–490.
- Маккалоу, М. Э., Килпатрик, С. Д., Эммонс, Р. А., и Ларсон, Д. Б. (2001). Является ли благодарность моральным аффектом? Психологический бюллетень , 127, 249-266.
- Park, N., & Peterson, C. (2006, а). Сильные стороны характера и счастье среди маленьких детей: контент-анализ родительских описаний. Journal of Happiness Studie s, 7 (3), 323-341.
- Park, N., & Peterson, C. (2006, b). Моральная компетентность и сильные стороны характера среди подростков: разработка и проверка ценностей в действии. Перечень сильных сторон молодежи. Журнал подросткового возраста , 29 (6), 891-909.
- Петерсон, К. и Селигман, М. (2004). Сильные стороны и достоинства характера Справочник и классификация .
- Вашингтон, округ Колумбия: Американская психологическая ассоциация. Зиммель, Г. (1950). Социология Георга Зиммеля . Гленко, Иллинойс: Свободная пресса.
- Тартаковский, М. (2011). Измерение сильных сторон вашего характера | Мир психологии . Получено с http://psychcentral.com/blog/archives/2011/01/05/measuring-your-character-strengths/ .
Классификация рукописных цифр с использованием нейронной сети
Давным-давно, когда у нас возникали более простые вопросы, такие как «В чем проблема?», Для составления отчетов использовались структурированные наборы данных.Перенесемся на несколько десятилетий вперед, и у нас появятся более сложные вопросы, например: «Почему возникает эта проблема?» а со сложными проблемами приходят сложные наборы данных или неструктурированные наборы данных. Чтобы спасти нас от всей этой сложности, используется нейронная сеть, которая заставляет машины учиться и решать все эти сложности за нас, масштабируясь с каждым уровнем сложности.
Одной из таких сложных проблем является распознавание рукописного ввода, представьте себе, что почерк на бумаге или планшете и переводят его в компьютерный печатный текст, больше не нужно повторять! Представьте, что вы не ломаете голову, пытаясь расшифровать почерк врача.Представьте себе ребенка с дисграфией, состоянием, которое приводит к плохому почерку, а не с трудностями в классе.
Зарегистрируйтесь на наш семинар о том, как начать свою карьеру в области науки о данных?
Все это можно сделать с помощью инструмента распознавания рукописного ввода, который классифицирует текст по изображению. Этот инструмент имеет графический интерфейс пользователя, где внутри холста пользователь может написать любое английское слово от руки, а модель, сидящая на бэкэнде, сможет распознать это слово.Для этого инструмента был использован классификатор Multi-Layer Perceptron (MLP) с решателем Адама и сигмоидной функцией для достижения значительных результатов.
Набор данныхИспользуемый набор данных был создан Национальным институтом стандартов и технологий (NIST). Специальная база данных NIST 19 состоит из примерно 0,7 миллиона образцов изображений в формате PNG. Текущая модель обучена только для прописных букв (A-Z). В следующей таблице указано количество наблюдений на символ:
Таблица 1: Число наблюдений на символ
| A: 7,010 | Q: 2,566 | g: 3,839 | w: 2,699 | |||||
| B: 4,091 | R: 4,536 | h: 9,713 | x: 2 2,792 | S: 23,827 | i: 2,788 | y: 5,088 | ||
| D: 4,945 | T: 10,927 | j: 1,920 | z: 2,726 | 14461|||||
| k: 2,562 | 0: 34,803 | |||||||
| F: 10,203 | V: 4,951 | л: 16,937 | 1: 38,049 | |||||
| G: 2,575 | м: 2,62: 34,184 | |||||||
| H: 3,271 | X: 2,731 | n: 12,856 | 3: 35,293 | |||||
| I: 13,179 | Y: | |||||||
| J: 3,962 | Z: 2,698 | p: 2,401 | 5: 31,067 | |||||
| K: 2,473 | a: 11,196 | q: 3,115 | 6: 34,037 | |||||
| L: 5,390 | b: 5,551 | : 35,796|||||||
| M: 10,027 | c: 11315 | s: 2,698 | 8: 33,884 | |||||
| N: 9,149 | d: 11,421 | t: 20,793 | O: 28,680 | e: 28,299 | u: 2,837 | |||
| P: 9,277 | f: 2,493 | v: 2,854 |
Каждый символ в исходном наборе данных занимает 128 × 128 пикселей на растр (рис. 1 a), чтобы избежать тяжелых вычислений, размер изображения был уменьшен до 56 x 56 пикселей (рис. 1 b).Кроме того, размер холста был уменьшен до 28 × 28 пикселей за счет удаления заполнения (рис. 1 c), что привело к набору данных конфигурации 784 функций. Каждый символ был помечен последовательно от «A» до «Z».
Рисунок 1: (a) Исходный растр 128 x 128 пикселей, полученный из базы данных NIST, (b) растр 56 x 56 пикселей при изменении размера изображения, (c) растр 28 x 28 пикселей после удаления отступ из измененного изображенияПакет tkinter использовался для создания пользовательского интерфейса, подобного холсту.Как только пользователь пишет слово на холсте, инструмент преобразует изображение в двухмерный массив NumPy, а затем просматривает массив по столбцам в поисках заполненного пикселя, чтобы отметить начало буквы. Для слов модель продолжает перемещаться и искать столбец, в котором есть значительный относительный пробел, чтобы отметить начало второго символа. Инструмент достаточно умен, чтобы отличить разрыв букв от начала второй буквы.
Рисунок 2: Интерпретация пользовательского ввода моделью Рисунок 3 : Пользовательский интерфейс ВызовыПри разработке и создании этого инструмента возникло несколько проблем, перечисленных ниже:
# 1 : Исходный набор данных требовал больших вычислительных мощностей для гипер-настройки модели для различных комбинаций.Чтобы преодолеть это ограничение с помощью персонального компьютера, который использовался для построения этой модели, набор данных был разделен на пакеты из пяти символов (то есть буквы A-E, F-I и т. Д.), И модель была обучена и протестирована с использованием этих пакетов.
# 2 : Несбалансированность количества наблюдений среди символов в наборе данных привела к осложнениям на этапе тестирования и обучения (например, 10k и 2,5k изображений для J и K соответственно). Чтобы преодолеть это, был создан сценарий, который разделил тестовый и обучающий набор данных для каждого персонажа индивидуально, а затем объединил их, чтобы обеспечить хорошо сбалансированный набор данных.
# 3 : английские алфавиты содержат буквы, которые выглядят очень похожими друг на друга (то есть B и P, D и O). Во время обучения и тестирования модель изо всех сил пыталась правильно классифицировать эти буквы. Чтобы свести к минимуму ошибочную классификацию этих букв, модель была обучена и настроена для этих букв отдельно с большим набором данных.
Смотрите также Конфигурация модели нейронной сетиКлассификатор Multi-Layer Perceptron (MLP) для этого инструмента был обучен с использованием обратного распространения ошибки для достижения значительных результатов.Ниже представлена конфигурация нейронной сети:
- Размер скрытого слоя: (100,100,100), т. Е. 3 скрытых слоя по 100 нейронов в каждом
- Функция активации: логистическая сигмоида, возвращает f (x) = 1 / (1 + exp (-x))
- Решатель для оптимизации веса: оптимизатор на основе стохастического градиента («Адам»)
- Ранняя остановка (во избежание переобучения): True
Рисунок 4 : Архитектура модели
РезультатыТаблица 2: Сводка результатов
| Количество образцов (тестовый набор): | 74,491 | |||
| Правильно классифицировано: | 71,227 | |||
| Точность: | .4% | 'B', 'H', 'K', 'N', 'R', 'X' | ||
| B | 1,734 | 1,572 | 90,7% | 'A', 'D', E, G, H, R, S |
| C | 4,682 | 4,544 | 97.1% | 'E', 'G', 'L', 'O' |
| D | 2,027 | 1,776 | 87,6% | 'B', 'O', 'P', 'Q ' |
| E | 2288 | 2115 | 92,4% | ' B ',' C ',' F ',' G ',' K ',' S ' |
| F | 233 | 210 | 90,4% | 'E', 'P', 'T' |
| G | 1,152 | 1050 | 91,1% | 'B', 'C', 'E', 'O ',' Q ' |
| H | 1,444 | 1,278 | 88.5% | 'A', 'B', 'K', 'N', 'R' |
| I | 224 | 196 | 87,4% | 'J', 'L', 'T ',' Z ' |
| J | 1,699 | 1,589 | 93,5% | ' I ',' T ',' Z ' |
| K | 1,121 | 1,008 | % 'A', 'E', 'H', 'M', 'N', 'R', 'X', Y | |
| L | 2,317 | 2,255 | 97,3% | 'C', «I» |
| M | 2,467 | 2,337 | 94.7% | 'K', 'N', 'W' |
| N | 3,802 | 3,606 | 94,9% | 'A', 'H', 'K', 'M', 'R ' |
| O | 11565 | 11338 | 98,0% | ' C ',' D ',' G ',' Q ' |
| P | 3,868 | 3,778 | % 'D', 'F', 'R'||
| Q | 1,162 | 1,009 | 86,8% | 'D', 'G', 'O' |
| R | 2,313 | 2,113 | 92.7% | 'A', 'B', 'H', 'K', 'N', 'P' |
| S | 9,684 | 9,481 | 97,9% | 'B', 'E ' |
| T | 4,499 | 4,430 | 98,5% | ' F ',' I ',' J ' |
| U | 5,802 | 5,658 | , 97,5 'W'||
| V | 836 | 810 | 96,8% | 'U', 'W', 'Y' |
| W | 2,157 | 2,017 | 93.5% | 'M', 'U', 'V' |
| X | 1,254 | 1,163 | 92,7% | 'A', 'K', 'Y' |
| Y | 2,172 | 2,055 | 94,6% | 'K', 'X' |
| Z | 1,215 | 1,162 | 95,6% | 'I', 'J' |
Хотя этот инструмент служит базовой моделью для преодоления разрыва в коммуникации, необходимо проделать еще больше работы.В настоящее время модель может расшифровывать буквы и слова, но способна обрабатывать фразы и абзацы с правильным расширением. Кроме того, UI / UX может быть доработан для использования более широкой пользовательской аудиторией.
Подпишитесь на нашу рассылку новостей
Получайте последние обновления и актуальные предложения, поделившись своей электронной почтой.Присоединяйтесь к нашей группе Telegram. Станьте частью интересного сообщества
Уткарш Нигам
Начинающий специалист по данным, в настоящее время изучающий степень магистра наук о данных в Университете Джорджа Вашингтона, который также имеет степень бакалавра наук.Tech. Кандидат компьютерных наук и степень MBA по маркетингу. Он имеет опыт работы в области машинного обучения, статистического моделирования, автоматизации и анализа данных и хочет специализироваться в области глубокого обучения.
Улучшение распознавания персонажей сцены на основе ансамбля с помощью вероятности классификации - Университет Тохоку
TY - GEN
T1 - Улучшение распознавания персонажей сцены на основе ансамбля с помощью вероятности классификации
AU - Horie, Fuma
Hideaki
AU - Suganuma, Takuo
N1 - Авторское право издателя: © 2020, Springer Nature Switzerland AG.
PY - 2020
Y1 - 2020
N2 - Исследования в области распознавания символов сцены были популярны благодаря своему потенциалу во многих приложениях, включая автоматический переводчик, распознавание вывесок и помощник по чтению для слабовидящих. Распознавание персонажей сцены является сложной задачей из-за различных факторов окружающей среды при захвате изображения и сложного дизайна персонажей. Современные системы оптического распознавания символов не достигли практической точности для произвольных персонажей сцены, хотя некоторые эффективные методы были предложены в прошлом.Чтобы улучшить существующие системы распознавания, мы предлагаем метод иерархического распознавания, использующий методы вероятности классификации и предварительной обработки изображений. Показано, что точность нашей последней ансамблевой системы была улучшена с 80,7% до 82,3% за счет применения предложенных методов.
AB - Исследования в области распознавания символов сцены были популярны из-за своего потенциала во многих приложениях, включая автоматический переводчик, распознавание вывесок и помощник по чтению для слабовидящих.Распознавание персонажей сцены является сложной задачей из-за различных факторов окружающей среды при захвате изображения и сложного дизайна персонажей. Современные системы оптического распознавания символов не достигли практической точности для произвольных персонажей сцены, хотя некоторые эффективные методы были предложены в прошлом. Чтобы улучшить существующие системы распознавания, мы предлагаем метод иерархического распознавания, использующий методы вероятности классификации и предварительной обработки изображений. Показано, что точность нашей последней ансамблевой системы была улучшена с 80.От 7% до 82,3% за счет применения предложенных методов.
KW - Классификатор голосования по ансамблю
KW - Метод иерархического распознавания
KW - Синтетические данные символов сцены
UR - http://www.scopus.com/inward/record.url?scp=85081578373&partnerID=8YFLogxK
- http://www.scopus.com/inward/citedby.url?scp=85081578373&partnerID=8YFLogxKU2 - 10.1007 / 978-3-030-41299-9_10
DO - 10.