6. Характеристика непроизвольного, произвольного и послепроизвольного внимания
Внимание – состояние психологической концентрации, сосредоточенности на каком – либо объекте. Это процесс сознательного или бессознательного (полусознательного) отбора одной информации, поступающей через органы чувств, и игнорирование другой.
Непроизвольное
внимание – это внимание, которое включается,
функционирует, переключается с объекта
на объект и отключается автоматически,
без
участия сознания и воли человека.
Его вызывают
раздражители,
соответствующие потребностям индивида,
значимые для него.
Оно связано и с общей направленностью
личности. Непроизвольное внимание
возникает независимо от сознательных
намерений субъекта, без каких – либо
волевых усилий с его стороны. Основная
функция НВ заключается в быстрой и
правильной
ориентации
в постоянно меняющихся условиях среды,
в выделении тех его объектов, которые
могут иметь в данный момент наибольший
жизненный смысл.
Произвольное внимание – это внимание, которое, напротив, регулируется волей человека, находится под его сознательным контролем. Оно возникает, если в деятельности человек ставит перед собой определенную задачу и сознательно вырабатывает программу действий. В ПВ проявляется активность личности, при этом внимании интересы носят опосредованный характер (это интересы цели, результата деятельности). Основной функцией ПВ является активное регулирование протекания психических процессов. Именно благодаря наличию ПВ человек способен активно, избирательно «извлекать» из памяти нужные ему сведения, выделять главное, существенное, принимать правильные решения, осуществлять задачи, возникающие в деятельности.
Послепроизвольное
внимание. Это
понятие было введено Н.Ф.Добрыниным. Если в
целенаправленной деятельности для
личности интересными и значимыми
становятся содержание и сам процесс
деятельности, а не только его результат,
как при произвольном сосредоточении,
то говорят о послепроизвольном внимании. Деятельность так захватывает в этом
случае человека, что ему не требуется
заметных волевых усилий для поддержания
внимания. Послепроизвольное внимание,
появляясь
вслед за произвольным,
не может быть сведено к нему. Так как
это внимание связано с сознательно
поставленной целью, оно не может быть
сведено и к непроизвольному вниманию.
Послепроизвольное внимание характеризуется
длительной
высокой сосредоточенностью,
с ним обоснованно связывают наиболее
интенсивную и плодотворную умственную
деятельность.
Деятельность так захватывает в этом
случае человека, что ему не требуется
заметных волевых усилий для поддержания
внимания. Послепроизвольное внимание,
появляясь
вслед за произвольным,
не может быть сведено к нему. Так как
это внимание связано с сознательно
поставленной целью, оно не может быть
сведено и к непроизвольному вниманию.
Послепроизвольное внимание характеризуется
длительной
высокой сосредоточенностью,
с ним обоснованно связывают наиболее
интенсивную и плодотворную умственную
деятельность.
свойства внимания:
Устойчивость
— проявляется в способности в течение
длительного времени сохранять состояние
внимания,
на каком – либо объекте, предмете
деятельности, не отвлекаясь и не ослабляя
внимание. Устойчивость внимания может
определяться различными причинами.
Одни из них связаны с индивидуальными
физиологическими особенностями человека,
в частности со свойствами его нервной
системы, общим состоянием организма в
данный момент времени; другие характеризуют
психические состояния (возбужденность,
заторможенность), третьи соотносятся
с мотивацией (наличием или отсутствием
интереса к предмету деятельности, его
значимостью для личности) четвертые –
с внешними обстоятельствами осуществления
деятельности.
Люди со слабой нервной системой или перевозбужденные могут быстро утомляться, становиться импульсивными. Человек, который не очень хорошо чувствует себя физически, как правило, характеризуется неустойчивым вниманием. Отсутствие интереса к предмету способствует частому отвлечению внимания от него, и, напротив, наличие интереса сохраняет внимание в повышенном состоянии в течение длительного времени. Если отсутствуют внешне отвлекающие моменты, внимание бывает достаточно устойчивым.
Сосредоточенность – проявляется в различиях, которые имеются в степени концентрированности внимания на одних объектах и его отвлечение от других.
Распределение
– оно
состоит в способности рассредоточить
внимание на значительном пространстве,
параллельно выполнять несколько видов
деятельности или совершать несколько
различных действий. Известно, что память
на прерванные действия способна
сохраняться в течение определенного
времени. В течение этого периода человек
может без труда возвратиться к продолжению
прерванной деятельности.
Объем внимания – определяет количество информации, одновременно способной сохраняться в сфере повышенного внимания человека. Численная характеристика среднего объема внимания людей 5-7 единиц информации. Она обычно устанавливается посредством опыта, в ходе которого человеку на очень короткое время предъявляется большое количество информации. То, что он за это время успевает заметить, и характеризует его объем внимания. Основным условием расширения объема внимания является формирование умений группировать, систематизировать, объединять по смыслу воспринимаемый материал.
Переключаемость
– понимается
как перевод
внимания с одного объекта на другой, с
одного вида деятельности на иной. Данная характеристика человеческого
внимания проявляется в скорости, с
которой он может переводить свое внимание
с одного объекта на другой, причем такой
перевод может быть как не произвольным,
так и произвольным. В первом случае
индивид невольно переводит свое внимание
на что-либо такое, что его случайно
заинтересовало, а во втором – сознательно,
усилием воли заставляет себя сосредоточиться
на каком-нибудь, даже не очень интересном
объекте. Переключаемость внимания, если
она происходит на непроизвольной основе,
может свидетельствовать о его
неустойчивости, но такую неустойчивость
не всегда есть основание рассматривать
как отрицательное качество. Она нередко
способствует временному отдыху организма,
анализатора, сохранению и восстановлению
работоспособности нервной системы и
организма в целом.
Данная характеристика человеческого
внимания проявляется в скорости, с
которой он может переводить свое внимание
с одного объекта на другой, причем такой
перевод может быть как не произвольным,
так и произвольным. В первом случае
индивид невольно переводит свое внимание
на что-либо такое, что его случайно
заинтересовало, а во втором – сознательно,
усилием воли заставляет себя сосредоточиться
на каком-нибудь, даже не очень интересном
объекте. Переключаемость внимания, если
она происходит на непроизвольной основе,
может свидетельствовать о его
неустойчивости, но такую неустойчивость
не всегда есть основание рассматривать
как отрицательное качество. Она нередко
способствует временному отдыху организма,
анализатора, сохранению и восстановлению
работоспособности нервной системы и
организма в целом.
С переключаемостью
внимания функционально связаны два
разнонаправленных процесса: включение
и отвлечение внимания. Первый
характеризуется тем, как человек
переключает внимание на нечто и полностью
сосредотачивается на нем; второй – тем,
как осуществляется процесс отвлечения
внимания.
Особенности и условия формирования внимания ребенка раннего, дошкольного и школьного возрастов.
Историю развития внимания пытался проследить Л.С. Выготский в русле своей культурно – исторической концепции. Он писал, что история внимания ребенка есть история развития организованности его поведения, что ключ к генетическому пониманию внимания следует искать не внутри, а вне личности ребенка.
Произвольное
внимание возникает из того, что окружающие
ребенка люди « начинают при помощи ряда
стимулов и средств направлять внимание
ребенка, руководить его вниманием,
подчинять его своей власти и тем самым
дают в руки ребенка те средства, с помощью
которых он впоследствии и сам овладевает
своим вниманием.» Культурное развитие
внимания заключается в том, что при
помощи взрослого ребенок усваивает ряд
искусственных стимулов – средств
(знаков),
посредством которых он дальше направляет
свое собственное поведение и внимание.
Процесс возрастного развития внимания
по идеям Выготского Л.
Различия в характеристиках произвольного и непроизвольного внимания возрастают, начиная с дошкольного возраста, и достигают максимума в школьном возрасте, а затем вновь обнаруживают тенденцию к уравниванию.
Л.С.
Выготский пишет, что с самых первых дней
жизни ребенка развитие его внимания
происходит в среде, включающий так
называемый двойной ряд стимулов,
вызывающих внимание. Первый ряд – это
сами окружающие предметы, которые своими
яркими необычными свойствами приковывают
внимание ребенка. С другой стороны, это
речь взрослого человека, произносимые
им слова, которые первоначально выступают
в роли стимулов – указаний, направляющих
непроизвольное внимание ребенка. Таким
образом, с первых дней жизни ребенка
его внимание в значительной его части
оказывается
направляемым с помощью слов – стимулов.
С другой стороны, это
речь взрослого человека, произносимые
им слова, которые первоначально выступают
в роли стимулов – указаний, направляющих
непроизвольное внимание ребенка. Таким
образом, с первых дней жизни ребенка
его внимание в значительной его части
оказывается
направляемым с помощью слов – стимулов.
Вместе с постепенным овладением активной речью ребенок начинает управлять и первичным процессом собственного внимания, причем сначала – в отношении других людей, ориентируя их собственное внимание обращенным к ним словом в нужную сторону, а затем — и в отношении самого себя.
Общая
последовательность культурного развития
внимания по Л.С.Выготскому состоит в
следующем: «Сначала люди действуют по
отношению к ребенку, затем он сам вступает
во взаимодействие с окружающими, наконец,
он начинает действовать на других и
только в конце начинает действовать на
себя » Вначале
взрослый направляет его внимание словами
на окружающие его вещи и вырабатывает,
таким образом, из слов могущественные
стимулы – указания; затем ребенок
начинает активно участвовать в этом
указании и сам начинает пользоваться
словом и звуком как средством указания,
т. е. обращать внимание взрослых на
интересующий его предмет.
е. обращать внимание взрослых на
интересующий его предмет.
Слово,
которым пользуется взрослый, обращаясь
к ребенку, появляется первоначально в
роли указателя, выделяющего для ребенка
те или иные признаки в предмете,
обращающего его внимание на эти признаки.
При обучении слово все более направляется
в сторону выделения абстрактных отношений
и приводит к образованию абстрактных
понятий. Л.С.Выготский считал, что
управление языка как средства направления
внимания и указателя к образованию
представлений имеет для педагогики
огромное значение, поскольку с помощью
слов ребенок выходит в сферу межличностного
отношения, где открывается простор для
личностного развития. Первоначально
процессы произвольного внимания,
направляемого речью взрослого, являются
для ребенка скорее процессами его
внешнего дисциплинирования, чем
саморегуляции. Постепенно, употребляя
то же самое средство овладения вниманием
отношению к самому себе, ребенок переходит
к самоуправлению поведением, т.е. к
произвольному вниманию.
Этапы развития детского внимания:
Первые недели – месяцы жизни. Появление ориентировочного рефлекса как объективного, врожденного признака непроизвольного внимания ребенка.
Конец первого года жизни. Возникновение ориентировочно – исследовательской деятельности как средства будущего развития произвольного внимания.
Начало второго года жизни. Обнаружение зачатков произвольного внимания под влиянием речевых инструкций взрослого, направление взора на названный взрослым предмет.
Второй – третий год жизни. Достаточно хорошее развитие указанной выше первоначальной формы произвольного внимания.
Четыре с половиной – пять лет. Появление способности направлять внимание под влиянием сложной инструкции взрослого.
Пять – шесть лет. Возникновение элементарной формы произвольной внимания под влиянием самоинструкции (с опорой на внешние вспомогательные средства).
Школьный возраст.
 Дальнейшее развитие и
совершенствование произвольного
внимания, включая волевое.
Дальнейшее развитие и
совершенствование произвольного
внимания, включая волевое.
 Дальнейшее развитие и
совершенствование произвольного
внимания, включая волевое.
Дальнейшее развитие и
совершенствование произвольного
внимания, включая волевое.Теоретическая концепция внимания П.Я.Гальперина. Основные положения:
Внимание является одним из моментов ориентировочно – исследовательской деятельности. Оно представляет собой психологическое действие, направленное на содержание образа, мысли, другого феномена, имеющегося в данный момент времени в психике человека.
По своей функции внимание представляет собой контроль за этим содержанием. В каждом действии человека есть ориентировочная, исполнительская и контрольная части. Эта последняя и представляется вниманием как таковым.
В отличие от других действий, которые производят определенный продукт, деятельность контроля, или внимание, не имеет отдельного, особенного результата.
Внимание как самостоятельный, конкретный акт выделяется лишь тогда, когда действие становится не только умственным, но и сокращенным.
Не всякий контроль стоит
рассматривать как внимание. Контроль
лишь оценивает действие, в то время как
внимание способствует его улучшению.Во внимании контроль осуществляется при помощи критерия, меры, образа, что создает возможность сравнения результатов действия и его уточнения.
Произвольное внимание есть планомерно осуществляемое внимание, т.е. форма контроля, выполняемого по заранее составленному плану, образцу.
Для того чтобы сформировать новый прием произвольного внимания, мы должны наряду с основной деятельностью предложить человеку задание проверить ее ход и результаты, разработать и реализовать соответствующий план.
Все известные акты внимания, выполняющие функцию контроля как произвольного, так и непроизвольного, являются результатом формирования новых умственных действий.
 Не всякий контроль стоит
рассматривать как внимание. Контроль
лишь оценивает действие, в то время как
внимание способствует его улучшению.
Не всякий контроль стоит
рассматривать как внимание. Контроль
лишь оценивает действие, в то время как
внимание способствует его улучшению.Методы исследования внимания
Исследование
внимания имеет большое значение в работе
школьных психологов, в частности при
анализе причин неуспеваемости и при
выработке индивидуальных
психолого-педагогических мероприятий.
При исследовании внимания следует учитывать, что качества внимания у одного и того же человека зависят от многих факторов: возможны колебания внимания в зависимости от утомления и общего состояния организма, отношения человека к тому или иному виду деятельности, его эмоционального состояния. С другой стороны, внимание всегда «включено» в самые разнообразные психические явления, при его исследовании существует необходимость вычленения, «извлечения» его из этих процессов. Большинство разработанных проб на испытание внимания имеют варианты, позволяющие не только выявлять, но и количественно выражать различные свойства внимания: объем, переключаемость, устойчивость, концентрацию, избирательность и другие.
Объем
внимания. Все методы для изучения объема
внимания можно подразделить на прямые
и косвенные. Прямой метод предусматривает
предъявление материала (например, слов,
букв, изображений предметов) в короткие
промежутки времени с помощью тахистоскопа
с последующим подсчетом замеченного
испытуемым. Индивидуальные оценки
результатов сравниваются со
среднегрупповыми.
Индивидуальные оценки
результатов сравниваются со
среднегрупповыми.
Расстройства внимания выявляются как во время беседы (отвлекается на посторонние раздражители, не может сосредоточиться, быстро утомляется, не может переключиться и т.д.), так и в ходе специального психодиагностического исследования. Из методик исследования внимания наиболее известны и широко применяются: корректурные пробы, счет по Крепелину, отыскивание чисел по таблицам Шульте, поочередное сложение, поочередное вычитание, тест Мюнстерберга и др.
Общая психопатология | Обучение | РОП
В норме внимание помогает индивиду воспринимать наиболее важные для него стимулы, игнорируя неважные, кроме того, внимание дает индивиду способность произвольно направлять и удерживать фокус своего внимания на интересующих его объектах, что позволяет продуктивно решать стоящие перед ним задачи.
Нарушения внимания могут быть достаточно разнообразными. Выделяют нарушения внимания, связанные с изменением состояния бодрствования (в этих случаях может быть нарушено, как произвольное, так и непроизвольное внимание), и нарушения характеристик произвольного внимания (его селективности, устойчивости, переключаемости, объема и пр. ).
).
Невнимание (апрозексия) — этот термин часто применятся сразу по отношению ко всей группе нарушений внимания, однако при более дифференцированном подходе его правильно использовать лишь в случаях общего угнетения процессов внимания, т.е. при отсутствии или затруднении фокусировки внимания как на важных, так и на неважных стимулах; в связи с этим восприятие всех стимулов нарушено, они игнорируются. В основе лежит снижение тонуса нервной системы, уровня бодрствования и готовности действовать. В таких состояниях человек выглядит вялым, недостаточно реагирующим на происходящее вокруг, его внимание трудно или невозможно чем-либо привлечь. Невнимание в той или иной степени выраженности наблюдается при угнетении сознания, интоксикациях седативными веществами, выраженном утомлении, апатии, грубых нарушениях интеллекта, органических поражениях головного мозга определенных локализаций. Например, при оглушении пациент воспринимает лишь малую часть окружающих его стимулов, он вял, аспонтанен, врачу приходится многократно повторять свой вопрос, чтобы пациент мог сфокусировать свое внимание на нем и на попытках на него ответить. Врач из-за чрезмерного утомления и сонливости, например во время ночного дежурства, может упустить признаки болезни у своего пациента, в том числе как важные, так и неважные, допустить ошибку в своих действиях. Водитель в состоянии алкогольного опьянения или под действием седативных препаратов из-за невнимательности может «просмотреть» изменение ситуации на дороге.
Врач из-за чрезмерного утомления и сонливости, например во время ночного дежурства, может упустить признаки болезни у своего пациента, в том числе как важные, так и неважные, допустить ошибку в своих действиях. Водитель в состоянии алкогольного опьянения или под действием седативных препаратов из-за невнимательности может «просмотреть» изменение ситуации на дороге.
Сверхотвлекаемость (гиперметаморфоз, сверхбодрствование) — фокусировка внимания сразу на всех действующих на человека стимулах, как на важных, так и на неважных. В основе — состояние, противоположное невниманию, — повышенная активация нервной системы и «чрезмерный» уровень бодрствования. В результате внимание становится крайне неустойчивым, сверхизменчивым, человек постоянно отвлекается на каждый новый стимул. В выраженных случаях нарушаются последовательность, цельность мыслительной деятельности, вплоть до развития состояния растерянности, недоумения. Наблюдается при маниакальных состояниях, интоксикациях стимуляторами и психодислептиками, иногда при галлюцинаторно-бредовых состояниях, органических поражениях головного мозга определенных локализаций.
Неустойчивость внимания (патологическая отвлекаемость) — неспособность человека удерживать фокус произвольного внимания на нужном ему объекте, в связи с чем страдает продуктивность его деятельности. При слабости произвольного внимания ведущую роль начинает занимать внимание непроизвольное, из-за этого человек постоянно отвлекается на посторонние стимулы, случайно попадающие в поле его внимания, случайные мысли («витает в облаках», «считает ворон»). Выраженность расстройства может в значительной степени варьировать.
Синдром дефицита внимания с гиперактивностью (СДВГ), основу которого составляет неустойчивость произвольного внимания, может проявляться целым спектром относительно негрубых нарушений внимания, отражающихся преимущественно на успеваемости в школе и работоспособности. Необходимо учитывать, что способность к удержанию фокуса произвольного внимания постепенно формируется у ребенка по мере его развития, поэтому для оценки этого нарушения у детей нужно принимать во внимание возрастные нормы.
При некоторых случаях органических поражений головного мозга (особенно дорсальной поверхности лобных долей) неустойчивость внимания может достигать такой степени, что она полностью дезорганизует деятельность взрослого человека.
Больной К. 35 лет несколько лет назад перенес тяжелую травму головного мозга во время погрузочных работ в порту, последние годы находится в психиатрической больнице. В отделении, если кто-то из медсестер громко вызывает любого из пациентов, К. тут же откликается, бросает свои дела и бежит к этой медсестре через весь коридор. Таким же образом встречает каждого, кто входит в отделение, начинает бойко и громко с ним разговаривать, но потом также быстро отходит, обратив внимание на что-то новое. Полноценно побеседовать с лечащим врачом он не в состоянии — ответив на один-два вопроса, он переключается на случайные темы, сам начинает задавать вопросы, а если рядом что-то происходит, теряет всякое внимание к беседе с врачом и, не завершив беседу, уходит в интересующем его направлении, например, посмотреть, как стригут других больных или что принесла процедурная медсестра из аптеки.
Истощаемость внимания — неспособность человека длительное время удерживать фокус произвольного внимания; первоначально внимание направлено на нужный индивиду объект, но по мере утомления оно все более истощается, а следовательно, непроизвольное внимание выходит на первый план. Является достаточно характерным признаком утомления и астении. Например, студент, утомленный недосыпанием на ночных дежурствах, садится заниматься: какое-то время он сосредоточенно читает учебник, но через несколько страниц замечает, что думает о чем-то постороннем, пытается вспомнить, что он только что читал, но не может. В специальных психологических тестах истощаемость внимания проявляется увеличением количества ошибок в монотонном задании по ходу его выполнения. Истощаемость внимания также наблюдается при синдроме дефицита внимания с гиперактивностью, органическом поражении головного мозга.
Тугоподвижность внимания (вязкость, патологическая прикованность) — трудности с переключением внимания с одной темы или объекта на другую тему или объект. Рассматривается как проявление замедленного мышления, или брадифрении. Отмечается при органических заболеваниях головного мозга, в том числе эпилепсии, сосудистых заболеваниях и пр.
Рассматривается как проявление замедленного мышления, или брадифрении. Отмечается при органических заболеваниях головного мозга, в том числе эпилепсии, сосудистых заболеваниях и пр.
Про чрезмерную прикованность внимания к той или иной теме, от которой человек не может отвлечься и которая заслоняет для него все происходящее вокруг, говорят также, когда описывают патологические суждения (бред, сверхценные идеи и навязчивые явления).
Сужение объема внимания — возможность одновременно удержать в фокусе внимания лишь небольшое количество объектов. Достаточно яркий пример — аффекты (аффективно суженное сознание) — остро развивающееся состояние, когда на фоне сильного эмоционального волнения, происходит резкое ограничение объема воспринимаемой информации (в том числе так называемое туннельное зрение) с сохранением фокуса внимания только на эмоционально значимых объектах; другие объекты, окружающие человека (в том числе те, которые помогли бы найти выход из сложившейся ситуации или дали бы возможность альтернативному пути действий), не воспринимаются (подробнее см. аффекты, аффективно-шоковые реакции).
аффекты, аффективно-шоковые реакции).
В случаях, когда у человека всегда отмечается некоторый недостаток объема и распределения внимания, проявляющиеся в виде невозможности удерживать в фокусе внимания необходимое для выполнения той или иной деятельности количество информации, эти нарушения в настоящее время часто трактуют, как недостаточность объема рабочей памяти. Существует целый ряд подходов к тренингу рабочей памяти, для повышения когнитивной эффективности, включая компьютеризированные варианты, доступные для мобильных устройств (н., n-back test).
избирательность и переключение. Что такое внимание. Виды внимания
По активности человека в организации внимания различают три вида внимания: непроизвольное, произвольное и послепроизвольное.
Непроизвольное внимание – это сосредоточение сознания на объекте в силу его особенности как раздражителя.
Более сильный раздражитель на фоне действующих привлекает внимание человека. Вызывает непроизвольное внимание новизна раздражителя, начало и прекращение действия раздражителя.
Перечисленные особенности раздражителя ненадолго превращают его в объект внимания. Длительное сосредоточение непроизвольного внимания на предмете связано с потребностями в нем, с его значимостью для личности.
Предметы, создающие в процессе познания яркий эмоциональный тон, вызывают непроизвольное сосредоточение внимания. Еще большее значение для возникновения непроизвольного внимания имеют интеллектуальные, эстетические и моральные чувства.
Интерес выступает одной из важнейших причин длительного непроизвольного внимания к предметам.
В процессе познания интересным для человека является не то, что вовсе неизвестно, и не то, о чем уже все известно. Новое в известном вызывает познавательный интерес.
Произвольное внимание – это сознательно регулируемое сосредоточение на объекте, направляемое требованиями деятельности.
При произвольном внимании сосредоточение происходит не только на том, что эмоционально приятно, а в большей мере на том, что должно делать. Поэтому психологическое содержание произвольного внимания связано с постановкой цели деятельности и волевым усилием.
Поэтому психологическое содержание произвольного внимания связано с постановкой цели деятельности и волевым усилием.
Произвольное сосредоточение на объекте предполагает волевое усилие, которое и поддерживает внимание. Волевое усилие переживается как напряжение, мобилизация сил на решение поставленной цели. Оно помогает удерживать внимание на объекте, не отвлекаться, не ошибаться в действиях.
Произвольное внимание как свойство личности не может быть сформировано независимо от самой личности.
В послепроизвольном внимании снижается волевое напряжение, необходимое при сосредоточении в произвольном внимании. После-произвольное внимание – сосредоточение на объекте в силу его ценности для личности.
Послепроизвольное внимание возникает на основе интереса, но это не заинтересованность, стимулированная особенностями предмета, а проявление направленности личности. При таком внимании сама деятельность переживается как потребность, а ее результат личностно значим.
Переход к контролю деятельности на уровне послепроизвольного внимания в значительной степени определяется особенностями личности. Если произвольное внимание перешло в послепроизвольное, то до наступления общей усталости не чувствуется напряжения.
Вниманием называют способность человека выделять те или иные объекты из множества других и реагировать на них.
Виды и отличия
Существует несколько типологий внимания. Одна из основных делит его на следующие виды:
- Непроизвольное – с возникновением без усилия со стороны человека, вызванное свойствами самого объекта. Непроизвольное внимание (НВ) присуще как людям, так и животным, и является природным качеством. Оно является результатом так называемого ориентировочного рефлекса: комплексной реакции организма на новизну раздражителя. Со временем, по мере того, как раздражитель раз за разом воздействует на сознание, реакция притупляется. Однако, информация, полученная в контакте с раздражителем, запоминается сама собой, без усилия со стороны человека. Непроизвольное внимание возникает в силу неожиданности появления раздражителя, его силы, новизны, контраста с окружающей средой, а также состояния психики и эмоций самого наблюдателя.
- Произвольное – в отличие от непроизвольного, оно не присуще животным и является прерогативой человека. Оно всегда связано с волевым усилием и целенаправленной мыслительной деятельностью наблюдателя. Произвольное внимание (ПВ) одновременно является условием и результатом труда и общественной деятельности. С одной стороны, последовательная, целенаправленная работа невозможна без произвольного внимания. С другой стороны, его развитие происходит именно в результате осознанных действий, требующих умственных усилий и сосредоточенности.
- Постпроизвольное – естественное продолжение произвольного внимания, если деятельность является не только необходимой, но и вызывает интерес исполнителя. В таком случае волевого усилия для выполнения тех или иных действий уже не требуется: человек увлечен и способен без труда сконцентрироваться на работе.
 Непроизвольное внимание возникает в силу неожиданности появления раздражителя, его силы, новизны, контраста с окружающей средой, а также состояния психики и эмоций самого наблюдателя.
Непроизвольное внимание возникает в силу неожиданности появления раздражителя, его силы, новизны, контраста с окружающей средой, а также состояния психики и эмоций самого наблюдателя.
Презентация: «Внимание»
Эти постоянно сменяют друг друга в процессе мыслительной деятельности. Так, человек может начать читать книгу в качестве справочного пособия для дальнейшей работы, а затем увлечься темой и продолжить чтение для собственного интереса и удовольствия.
Это яркий пример того, как постпроизвольное внимание приходит на смену произвольному. Если же человек утомится и потеряет концентрацию, ПВ может смениться непроизвольным – по отношению к посторонним объектам.
Чаще всего, впрочем, степень нашей концентрации не является слишком высокой, и произвольное и непроизвольное внимание успешно сочетаются друг с другом. Обдумывая решение задачи, мы успеваем проводить взглядом пролетающую за окном птицу, услышать телефонный звонок или почти механически ответить на посторонний вопрос коллеги.
Как повысить эффективность своих действий
При помощи произвольного внимания из множества объектов и явлений осознанно выделяются связанные с актуальной работой. По сути, ПВ предусматривает следующую последовательность действий: выбор и формулировка цели, организация и сосредоточение на ней, и, в конце концов, ее осуществление.
По сути, ПВ предусматривает следующую последовательность действий: выбор и формулировка цели, организация и сосредоточение на ней, и, в конце концов, ее осуществление.
Однако продолжительное удержание фокусировки на одном объекте или виде работы приводит к утомлению и упадку сил. В среднем, сосредоточенное умственное усилие человека начинает терять свою эффективность через 20 минут.
Презентация: «Свойства внимания»
Продолжение работы без перерыва вызывает усталость и неспособность к активному мыслительному процессу. Снижается произвольное и его замещает непроизвольный вид внимания.
Существует несколько факторов, помогающих повысить эффективность работы и не потерять концентрацию:
- Интерес к занятию, который позволяет произвольному вниманию перейти в постпроизвольное. В таком случае утомляемость существенно снижается, человек способен обработать больший объем информации с лучшими результатами.
- Привычные условия труда. Как показывает практика, изменения в интерьере, освещении или звукоизоляции (в любую сторону) отвлекают и не дают сосредоточиться. Сохранение концентрации при этом требует больших, чем обычно, усилий, человек быстрее утомляется, и выполняемая им работа сильно теряет в качестве.
- Отсутствие сильных раздражителей. К ним можно отнести резкие неожиданные шумы, вспышки света, обилие движущихся предметов вокруг, разговоры на посторонние темы. Все это также является отвлекающими факторами и мешает концентрации.
 Как показывает практика, изменения в интерьере, освещении или звукоизоляции (в любую сторону) отвлекают и не дают сосредоточиться. Сохранение концентрации при этом требует больших, чем обычно, усилий, человек быстрее утомляется, и выполняемая им работа сильно теряет в качестве.
Как показывает практика, изменения в интерьере, освещении или звукоизоляции (в любую сторону) отвлекают и не дают сосредоточиться. Сохранение концентрации при этом требует больших, чем обычно, усилий, человек быстрее утомляется, и выполняемая им работа сильно теряет в качестве.Следует, однако, заметить, что слабые раздражители – например, привычное тиканье часов, тихая музыка, приглушенные уличные звуки – наоборот способствуют сохранению внимания. Они ведут к возникновению слабых очагов возбуждения в коре головного мозга, которые дополняют собой основной очаг, связанный с выполнением текущей задачи; в результате сосредоточенность исполнителя и эффективность его работы возрастают. Таким образом НВ помогает укреплению ПВ.
Презентация: «Познавательные процессы человека»
Для сохранения приемлемого уровня концентрации рекомендуется регулярная смена деятельности.
У каждого человека есть свои особенности восприятия и переработки информации, склонности к тому или иному виду деятельности, но, если говорить об интеллектуальных усилиях, взрослому человеку в среднем достаточно делать перерывы приблизительно раз в час или полтора, переключаясь на более легкое или интересное задание, или физический труд, не требующий серьезной мыслительной нагрузки.
При таком графике работы мы, с одной стороны, не даем себе переутомляться, а с другой – с достаточным напряжением тренируем свою способность к концентрации.
Прочие свойства внимания
Помимо концентрации, у внимания есть и другие свойства – например, объем: количество объектов или занятий, которые мы можем воспринимать в один момент времени, а также распределение внимания – способность одновременно решать несколько задач. Объем и распределение внимания являются характеристиками, важными для выполнения различных действий в реальной жизни: ведь большинство ситуаций предполагает нашу способность к многозадачности.
Например, человек за рулем автомобиля должен одновременно следить за движением, дорожной разметкой и знаками, маневрами других автомобилистов. Дирижер оркестра читает партитуру и тут же отдает команды оркестрантам. Студент слушает лекцию, конспектирует и запоминает нужную информацию. При этом наше непроизвольное внимание отвлекает от выполнения основных действий на посторонние явления.
Занятия с детьми
Произвольное внимание развивается в процессе обучения с раннего детства, тогда как непроизвольное внимание является врожденным качеством. В отличие от непроизвольного, ПВ у детей нуждается в специальной тренировке, например, при помощи специальных занятий в дошкольных учреждениях и дома.
Такими занятиями могут быть упражнения на концентрацию: складывание картинок из нескольких частей, нахождение взаимосвязи между предметами, игра в слова и другие задачи, предполагающие интеллектуальное усилие.
Чем выше интерес ребенка к занятиям, тем эффективнее обучение.
 Таким образом, одной из основных задач воспитателя является возбуждение детского интереса и привлечение всех видов внимания в помощь учебному процессу.
Таким образом, одной из основных задач воспитателя является возбуждение детского интереса и привлечение всех видов внимания в помощь учебному процессу.Важно учитывать, что для детей, как и для взрослых, существует порог, после которого сосредоточенность неизбежно снижается; упражнения теряют свой смысл и эффективность, а уставший ребенок становится сверх возбудимым и невосприимчивым к учебе. В таком случае бессмысленно настаивать на продолжении занятий: поможет переключение на другие занятия или игры, физические нагрузки или простая прогулка на свежем воздухе. Как и любой навык, требует постепенности, регулярных повторений и системного подхода.
Страница 4
Произвольное внимание
Характеризуя внимание человека, наряду с непроизвольным вниманием выделяют высшую специфически человеческую его форму – произвольное внимание. Этот вид внимания существенно отличается от непроизвольного внимания как по характеру происхождения, так и по способах осуществления.
Произвольное внимание возникает тогда, когда человек ставит перед собой определенные задачи, сознательные цели, что и обусловливает выделение отдельных предметов (воздействий) как объектов внимания. Приняв решение, поставив перед собой задачу заняться чем-то, какой-нибудь деятельностью (конспектировать книгу, слушать лекцию), мы, выполняя это решение, произвольно направляем и сосредотачиваем сознание на то, чем считаем нужным заняться. Направленность и концентрация внимания здесь зависит не от особенностей самих предметов, а от поставленной, намеченной задачи, цели. В этих условиях, когда внимание направлено на раздражители, не являющиеся не наиболее сильными, ни наиболее новыми или наиболее занимательными, нередко требуется определенное усилие воли, необходимое как для того, чтобы сохранить объект сосредоточения, т.е. не отвлекаться, так и для того, чтобы поддерживать определенную интенсивность процесса сосредоточения. Это особенно ярко проявляется при наличии в окружающей обстановке посторонних, иррелевантных и вместе с тем новых, сильных, представляющих большой интерес раздражителей, когда приходится сосредотачиваться как бы вопреки их воздействию. Таким образом, произвольное внимание есть проявление волн. Подчеркивая эту особенность произвольного внимания, его иногда называют волевым вниманием.
Таким образом, произвольное внимание есть проявление волн. Подчеркивая эту особенность произвольного внимания, его иногда называют волевым вниманием.
Произвольное внимание, как все высшие произвольные психические процессы, процесс опосредствованный, представляющий собой продукт социального развития. Это положение было особенно отчетливо подчеркнуто Л.С. Выготским.
Произвольное внимание первоначально опосредствовано общением ребенка со взрослыми. Указания, приказ взрослых, в виде речевой инструкции выделяют из окружающих ребенка предметов определенную, названную взрослым вещь, те самым избирательно направляют внимание ребенка и подчиняют его поведение задачам, связанным с деятельностью с этой вещью. При этом ребенку приходится обращать внимание на требуемые приказом (инструкцией) вещи или их признаки, отвлекаясь о своих непосредственных влечений. Постепенно по мере развития ребенок начинает строить свое поведение на основе собственных приказов, путем самостоятельной постановки задач. Сначала самоприказы даются во внешней развернутой речевой форме. Это и определяет избирательное выделение ребенком из окружающих предметов тех, которые становятся объектами его внимания. На первых этапах становления произвольного внимания необходимым условием его поддержания является наличие внешних опор – в виде развернутых практических действий с выделенными объектами и развернутой речи ребенка. В ходе дальнейшего развития произвольного внимания постепенно происходит сокращение внешних опор, они как бы врастают внутрь, превращаются во внутреннюю речевую инструкцию, вол внутреннее умственное действие, на основе которого осуществляется контроль и регуляция поведения, поддержание стойкой избирательной направленности сознания.
Сначала самоприказы даются во внешней развернутой речевой форме. Это и определяет избирательное выделение ребенком из окружающих предметов тех, которые становятся объектами его внимания. На первых этапах становления произвольного внимания необходимым условием его поддержания является наличие внешних опор – в виде развернутых практических действий с выделенными объектами и развернутой речи ребенка. В ходе дальнейшего развития произвольного внимания постепенно происходит сокращение внешних опор, они как бы врастают внутрь, превращаются во внутреннюю речевую инструкцию, вол внутреннее умственное действие, на основе которого осуществляется контроль и регуляция поведения, поддержание стойкой избирательной направленности сознания.
В произвольном внимании, таким образом, как и в других высших формах психической деятельности человека, важную роль играет речь (внешняя и внутренняя).
Специфические особенности произвольного внимания определяют и условие его поддержания. Произвольное внимание, так же как и непроизвольное, тесно связано с чувствами, прежним опытом личности, его интересами. Влияние этих моментов сказывается, однако, при произвольном внимании косвенно, опосредствованно. Так, если непроизвольное внимание обусловлено непосредственными интересами, то при произвольном внимании интересы носят опосредствованный характер. Это интересы цели, интересы результата деятельности. Сама деятельность может не занимать непосредственно, но так как ее выполнение необходимо для решения важной задачи, она становится предметом внимания.
Влияние этих моментов сказывается, однако, при произвольном внимании косвенно, опосредствованно. Так, если непроизвольное внимание обусловлено непосредственными интересами, то при произвольном внимании интересы носят опосредствованный характер. Это интересы цели, интересы результата деятельности. Сама деятельность может не занимать непосредственно, но так как ее выполнение необходимо для решения важной задачи, она становится предметом внимания.
Произвольное внимание социально по своей природе и опосредствовано по структуре.
Послепроизвольное внимание
Ряд психологов выделяют еще один вид внимания, которое возникает после определенных волевых усилий, но когда человек как бы «входит» в работу, легко сосредоточивается на ней. Такое внимание советский психолог И.Ф. Добрынин назвал послепроизвольным (вторичным), так как оно приходит на смену обычному, произвольному вниманию Этот вид внимания отличается от непроизвольного внимания. У человека есть сознательная цель, в которой он сосредоточивается Послепроизвольное внимание имеет большое значение в учебной работе, в начале которой у школьника нередко вызывает произвольное внимание. Затем работа увлекает его, он перестает отвлекаться, начинает заниматься сосредоточенно.
Затем работа увлекает его, он перестает отвлекаться, начинает заниматься сосредоточенно.
Что такое произвольное внимание и как его тренировать
«Будь внимательнее!» — эта фраза все чаще сопровождает растущего ребенка и дома, и в детском саду, и даже во время прогулок на улице.
Взрослый считает ребенка рассеянным и стремится активизировать его внимание. Но если призадуматься, то можно обнаружить в этих же самых высказываниях указание на то, что ребенок очень даже сосредоточен. Просто его внимание направлено не на то, что важно с точки зрения взрослого, а на то, что значимо для него самого.
Внимание — психический процесс, который
обязательно присутствует при познании ребенком мира и проявляется в
направленности и сосредоточенности психики на определенных объектах. Из
огромного потока информации, непрерывно идущей из окружающего мира, благодаря работе
внимания ребенок выбирает ту, которая наиболее интересна, значима и важна для
него. Природа внимания проявляется в том, что выделенный объект, занимая
главное, доминирующее положение, создает в коре головного мозга человека
наиболее сильный очаг нервного напряжения — доминанту. При этом действие всех
остальных раздражителей тормозится. Они не доходят до сознания ребенка, он их
не замечает.
При этом действие всех
остальных раздражителей тормозится. Они не доходят до сознания ребенка, он их
не замечает.
Выделяют несколько типов внимания:
- внешнее внимание , обращенное на предметы и явления окружающего мира, на действия других людей. Данный тип можно замечать уже у младенца. (Поисковые движения глаз, поворот головки в сторону источника света, запаха или звука, замирание и т.д.).
- У дошкольника можно наблюдать и проявление внутреннего внимания , которое направлено на его собственные мысли и переживания. Самым ярким примером этого является ситуация, когда ребенок, забросив все дела, замирает с отрешенным взглядом. Не стоит принимать подобную отрешенность за рассеянность. Наоборот, это кульминация внутреннего внимания.
- Сосредоточенность
и направленность психики может возникнуть в ответ на какой-либо сильный,
необычный, резкий, внезапный раздражитель без каких-либо усилий со стороны
человека. Такое внимание называют непроизвольным . Оно появляется
вместе с вопросом: «Что это такое?», который возникает, когда мы
сталкиваемся с чем-то новым, необычным. Для ребенка пяти — семи лет такой
вопрос очень актуален. «Обыкновенные чудеса» поджидают
дошкольника в самых разных ситуациях и в самое разное время.
Непроизвольное внимание отличается стихийностью возникновения, отсутствием
усилий для его появления и сохранения. Случайно возникнув, оно может тут
же угаснуть.
- На шестом
году жизни ребенок сам начинает управлять собственным вниманием, заставляя
себя сосредоточиваться на чем-либо важном и нужном, жертвуя занимательным
и интересным. Вид внимания, при котором человек ставит перед собой
сознательную цель сконцентрироваться на чем-либо, называется произвольным .
В этом случае постановка и достижение цели требуют затрат физической
энергии, которую дают эмоции и воля. Ребенок, проявляя произвольное
внимание, расходует не только свое время, но и часть своей энергии. Вот
почему важно благодарить ребенка за проявление произвольного внимания.
 Оно появляется
вместе с вопросом: «Что это такое?», который возникает, когда мы
сталкиваемся с чем-то новым, необычным. Для ребенка пяти — семи лет такой
вопрос очень актуален. «Обыкновенные чудеса» поджидают
дошкольника в самых разных ситуациях и в самое разное время.
Непроизвольное внимание отличается стихийностью возникновения, отсутствием
усилий для его появления и сохранения. Случайно возникнув, оно может тут
же угаснуть.
Оно появляется
вместе с вопросом: «Что это такое?», который возникает, когда мы
сталкиваемся с чем-то новым, необычным. Для ребенка пяти — семи лет такой
вопрос очень актуален. «Обыкновенные чудеса» поджидают
дошкольника в самых разных ситуациях и в самое разное время.
Непроизвольное внимание отличается стихийностью возникновения, отсутствием
усилий для его появления и сохранения. Случайно возникнув, оно может тут
же угаснуть.
Как развивается произвольное внимание? Средства, с помощью которых ребенок начинает управлять своим вниманием, он получает в процессе взаимодействия с взрослыми. Родители, воспитатели включают ребенка в такие новые виды деятельности, как игры по правилам, конструирование и т. п. Вводя ребенка в эти виды деятельности, взрослые организуют его внимание при помощи словесных указаний. Ребенка направляют на необходимость выполнять заданные действия, учитывая те или иные обстоятельства.
Позднее
ребенок начинает сам обозначать словами те предметы и явления, на которые необходимо
обращать внимание, чтобы добиться нужного результата. Так он овладевает одним
из главных средств управления вниманием — умением словесно сформулировать то, на что
он будет ориентироваться . На протяжении дошкольного возраста
использование ребенком речи для организации собственного внимания резко
возрастает. Выполняя задание по инструкции взрослого, дети старшего дошкольного
возраста проговаривают инструкцию в 10-12 раз чаще, чем младшие дошкольники. Таким образом, произвольное внимание формируется в дошкольном возрасте в связи
с общим возрастанием роли речи в регуляции поведения ребенка.
Таким образом, произвольное внимание формируется в дошкольном возрасте в связи
с общим возрастанием роли речи в регуляции поведения ребенка.
- Часто бывает так, что занятия, которые вначале требовали волевых усилий для сосредоточения внимания, становятся затем интересными и увлекают ребенка. Произвольное внимание при этом переходит в послепроизвольное , в котором смешиваются характерные признаки как произвольного, так и непроизвольного внимания. С произвольным послепроизвольное внимание сходно активностью, целенаправленностью, а с непроизвольным — отсутствием усилий для его сохранения.
Таким образом, к пяти-шести годам можно наблюдать развитие произвольного и послепроизвольного внимания.
Тренировка внимания
В 5-7 лет можно заметить, что игры и
любая другая деятельность ребенка стали значительно дольше по времени, чем в
младшем дошкольном возрасте, это говорит о том, что возрастает устойчивость
внимания, которая отвечает за то, как
долго ребенок может поддерживать достаточный уровень сосредоточенности
психики на объекте или выполняемой деятельности. Старшие дошкольники способны
удерживать внимание на действиях, которые приобретают для них интеллектуально
значимый интерес (игры-головоломки, загадки, задания учебного типа). Но существуют
особенности устойчивость внимания дошкольника и условия, при соблюдении которых
оно только возрастет:
Старшие дошкольники способны
удерживать внимание на действиях, которые приобретают для них интеллектуально
значимый интерес (игры-головоломки, загадки, задания учебного типа). Но существуют
особенности устойчивость внимания дошкольника и условия, при соблюдении которых
оно только возрастет:
- Занимайтесь с ребенком без перерыва не больше 35 минут, идеальное время составляет 25 минут.
- Перерывы между занятиями или какой-то деятельности требующей сильно напряжения внимания не должно быть меньше 20 минут.
- Идеальный дни для деятельности, требующей усиленного внимания это вторник и среда.
- Не стоит
перегружать его в выходные занятиями в различных кружках, студиях,
посещением гостей, театров, музеев, просмотром фильмов, компьютерными играми
и так далее. Такое изобилие впечатлений не дает ребенку возможности
сосредоточиться на деятельности, предлагаемой ему в рабочие дни, и так же
может вызвать сонливость, а нервные клетки могут потерять восприимчивость
и перестать отвечать на падающие, на них раздражители. Чтобы избежать
этого, важно следить за тем, чтобы ребенок соблюдал режим дня ,
особенно в выходные дни.
 Чтобы избежать
этого, важно следить за тем, чтобы ребенок соблюдал режим дня ,
особенно в выходные дни.
Чтобы избежать
этого, важно следить за тем, чтобы ребенок соблюдал режим дня ,
особенно в выходные дни.Существуют так же и другие свойства внимания:
Концентрация внимания определяет, насколько сильно, интенсивно ребенок может сосредоточиться на объекте, а также насколько он способен сопротивляться отвлекающим обстоятельствам, случайным помехам. Чаще всего сила сосредоточения у дошкольников невелика, ее важно развивать. Например, с помощью такого упражнения:
Попробуйте вместе с ребенком разучить какое-нибудь стихотворение при включенном радио или телевизоре. Первое четверостишие учите при очень слабом звуке. Запоминая второе четверостишие, немного увеличьте громкость. Последнее четверостишие разучивайте при достаточно громком звуке.
Переключение
внимания определяется скоростью преднамеренного перехода ребенка с одного объекта или
вида деятельности на другой. При этом перевод внимания всегда сопровождается
некоторым нервным напряжением, которое реализуется волевым усилием.
Распределение внимания предполагает его рассредоточение в одно и то же время на несколько объектов. Именно это свойство дает возможность совершать сразу несколько действий, сохраняя их в поле внимания. В дошкольном возрасте переключение и распределение внимания развиты слабо и требуют тренировки.
Для тренировки переключения и распределения внимания можно использовать такое упражнение:
Ребенку предлагается лист со строчками, состоящими из разных фигур, которые расположены вперемежку: круги, квадраты, прямоугольники, трапеции, овалы и т. п. Дается задание: одну фигуру (например, круг) зачеркивать вертикальной чертой, а другую фигуру (например, треугольник) подчеркивать горизонтальной чертой, все остальные фигуры пропускать.
Психология. Учебник для средней школы. Теплов Б. М.
§23. Непроизвольное и произвольное внимание
Когда человек смотрит в кино интересный фильм, внимание без всяких стараний с его стороны направлено на экран. Когда, идя по улице, он внезапно услышит близко от себя резкий свисток милиционера, он «невольно» обратит на это внимание. Это — непроизвольное внимание, направляющееся на данный объект без нашего сознательного намерения и без всяких усилий с нашей стороны.
Когда, идя по улице, он внезапно услышит близко от себя резкий свисток милиционера, он «невольно» обратит на это внимание. Это — непроизвольное внимание, направляющееся на данный объект без нашего сознательного намерения и без всяких усилий с нашей стороны.
При непроизвольном внимании возникновение участка с оптимальной возбудимостью в коре головного мозга обусловлено непосредственно действующими раздражителями.
Но когда человек должен оторваться от интересной книги и заняться нужной, но мало увлекающей его в данный момент работой, например учить иностранные слова, ему приходится сделать над собой усилие, чтобы направить внимание в эту сторону, и, может быть, ещё больше делать усилий для того, чтобы не позволять вниманию отвлекаться, чтобы поддерживать внимание на этой работе. Если я хочу читать серьёзную книгу, а в комнате громкие разговоры и смех, я должен заставлять себя быть внимательным к чтению и не обращать внимания на разговоры. Такое внимание называется произвольным. Оно отличается тем, что человек ставит себе сознательную цель направить внимание на определённый предмет и для осуществления этой цели применяет, когда это нужно, определённые усилия, старания.
Оно отличается тем, что человек ставит себе сознательную цель направить внимание на определённый предмет и для осуществления этой цели применяет, когда это нужно, определённые усилия, старания.
При произвольном внимании участок с оптимальной возбудимостью поддерживается сигналами, идущими от второй сигнальной системы. Сознательная цель, намерение всегда выражается в словах, чаще всего произносимых про себя (так называемая «внутренняя речь»). Вследствие образовавшихся в прошлом опыте временных связей эти речевые сигналы могут определять перемещение по коре участка с оптимальной возбудимостью.
Способность произвольно направлять и поддерживать внимание развилась у человека в процессе труда, так как без этой способности невозможно осуществлять длительную и планомерную трудовую деятельность. Во всяком деле, как бы человек ни любил его, всегда имеются такие стороны, такие трудовые операции, которые сами по себе не имеют ничего интересного и не способны привлечь к себе внимание.
Необходимо уметь произвольно сосредоточивать своё внимание и на этих операциях, необходимо уметь заставить себя быть внимательным и к тому, что в данный момент не привлекает к себе. Хороший работник — это тот человек, который всегда может сосредоточить своё внимание на том, что необходимо по ходу работы.
Хороший работник — это тот человек, который всегда может сосредоточить своё внимание на том, что необходимо по ходу работы.
Сила произвольного внимания человека бывает очень велика. Опытные артисты, лекторы, ораторы хорошо знают, как трудно бывает начать играть, говорить речь или читать лекцию при сильной головной боли. Представляется, что при такой боли невозможно будет довести выступление до конца. Однако стоит только усилием воли заставить себя начать и сосредоточиться на содержании лекции, доклада или роли, как боль забывается и снова напоминает о себе только по окончании выступления.
Какие же предметы способны привлекать к себе наше непроизвольное внимание? Иначе говоря: каковы причины непроизвольного внимания?
Причины эти очень многочисленные и разнообразные, можно разделить на две категории: во-первых, внешние особенности самих объектов и, во-вторых, интересность этих объектов для данного человека.
Всякий очень сильный раздражитель обычно привлекает внимание.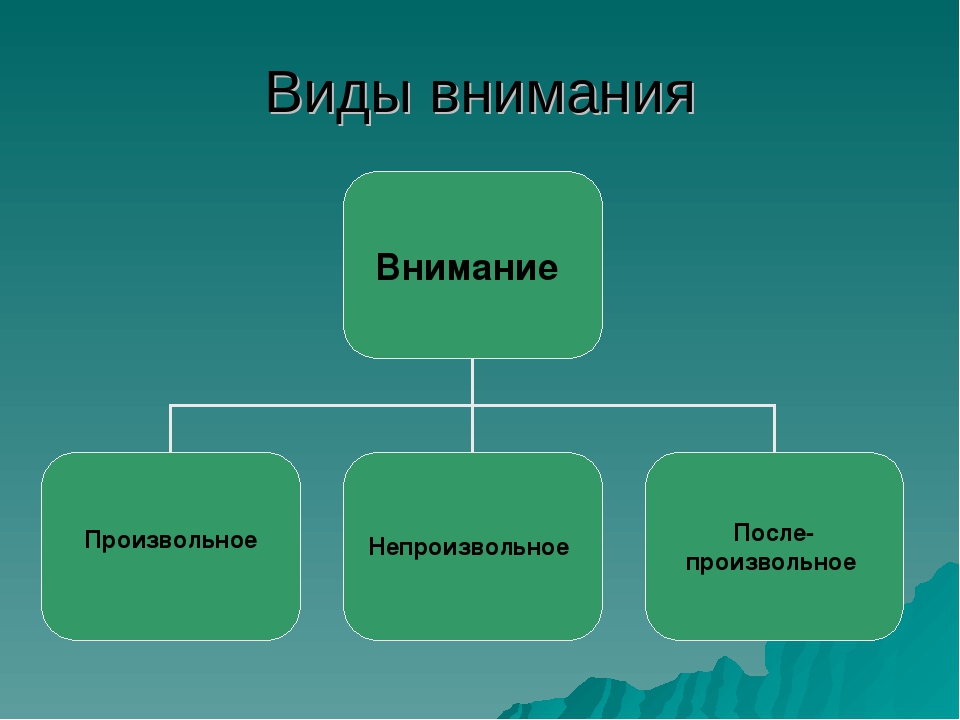 Сильный удар грома обратит на себя внимание даже очень занятого человека. Решающее значение имеет при этом не столько абсолютная сила раздражителя, сколько его относительная сила по сравнению с другими раздражителями. В шумном цехе завода голос человека может остаться незамеченным, тогда как среди полной тишины ночи даже слабый скрип или шорох могут привлечь внимание.
Сильный удар грома обратит на себя внимание даже очень занятого человека. Решающее значение имеет при этом не столько абсолютная сила раздражителя, сколько его относительная сила по сравнению с другими раздражителями. В шумном цехе завода голос человека может остаться незамеченным, тогда как среди полной тишины ночи даже слабый скрип или шорох могут привлечь внимание.
Внезапное и непривычное изменение также привлекают внимание. Например, если в классе со стены будет снята старая стенгазета, висевшая долгое время и уже переставшая привлекать внимание, то её отсутствие на привычном месте на первых порах будет обращать на себя внимание.
Главную роль в привлечении непроизвольного внимания играет интересность объекта для данного человека. Что же является интересным?
Прежде всего то, что близко связано с жизненной деятельностью человека и стоящими перед ним задачами, с той работой, которой он увлечён, с теми мыслями и заботами, которые эта работа в нём возбуждает. Человек, захваченный каким-нибудь делом или какой-нибудь идеей, интересуется всем тем, что с этим делом или с этой идеей связано, и, следовательно, на всё это обращает внимание. Учёный, работающий над какой-либо проблемой, сразу обратит внимание на, казалось бы, мелкую деталь, которая ускользает от внимания другого человека. Один из крупных советских изобретателей говорит о себе: «Меня интересуют принципы всех машин. Еду на трамвае и смотрю в окно, как идёт автомобиль, как он поворачивается (тогда я думал об управлении для культиватора). Я смотрю на все машины, например на лестницу пожарную, и вижу, что и её можно использовать».
Учёный, работающий над какой-либо проблемой, сразу обратит внимание на, казалось бы, мелкую деталь, которая ускользает от внимания другого человека. Один из крупных советских изобретателей говорит о себе: «Меня интересуют принципы всех машин. Еду на трамвае и смотрю в окно, как идёт автомобиль, как он поворачивается (тогда я думал об управлении для культиватора). Я смотрю на все машины, например на лестницу пожарную, и вижу, что и её можно использовать».
Конечно, люди интересуются и не только тем, что непосредственно связано с главным делом их жизни. Мы читаем книги, слушаем лекции, смотрим спектакли и кинофильмы, которые не имеют прямой связи с нашей работой. Что же требуется для того, чтобы они могли заинтересовать нас?
Во-первых, они должны быть в какой-то мере связаны с уже имеющимися у нас знаниями; предмет их не должен быть для нас совершенно неизвестным. Едва ли человек, никогда не изучавший физики звука и ничего не понимающий в технологии металлов, может заинтересоваться лекцией на тему «Применение ультразвуков в металлургии».
Во-вторых, они должны давать нам какие-либо новые знания, содержать в себе нечто для нас ещё неизвестное. Популярная лекция на только что названную тему не будет интересна для специалиста по ультразвукам, так как содержание её известно ему целиком.
Интересно главным сбразом то, что даёт новые сведения о вещах, с которыми мы уже знакомы, в особенности же то, что даёт ответы на уже имеющиеся у нас вопросы. Интересно то, чего мы ещё не знаем, но что мы уже хотим узнать. На этом принципе построены обыкновенно сюжеты интересных, увлекательных романов. Автор так ведёт рассказ, что перед нами встаёт ряд вопросов (кто совершил такой-то поступок? что случилось с героем?), и мы постоянно ожидаем получить на них ответ. Поэтому внимание наше находится в постоянном напряжении.
Интерес является самым важным источником непроизвольного внимания. Интересное увлекает, захватывает наше внимание. Но было бы совсем неверно думать, что произвольное внимание никак с интересом не связано. Оно тоже руководствуется интересами, но интересами другого рода.
Если увлекательная книга захватывает внимание читателя, то тут имеет место непосредственный интерес, интерес к самой книге, к содержанию её. Но если человек, задавшись целью построить модель какого-нибудь аппарата, производит для этого длинные и сложные вычисления, каким интересом он при этом руководствуется? Непосредственного интереса к самым вычислениям у него нет. Интересует его модель, и вычисления являются лишь средством для того, чтобы её построить. В этом случае человек руководствуется косвенным, или, что то же самое, опосредствованным интересом.
Такого рода косвенный интерес, интерес к результату, имеется почти во всякой работе, которую мы производим сознательно и добровольно; иначе мы не стали бы её производить. Его достаточно, чтобы взяться за работу. Но так как самая работа неинтересна, не увлекает нас, то мы должны употреблять усилие, чтобы сосредоточить на ней своё внимание. Чем меньше самый процесс работы интересует и увлекает нас, тем более необходимо произвольное внимание. Иначе мы никогда не достигнем интересующего нас результата.
Иначе мы никогда не достигнем интересующего нас результата.
Бывает, однако, так, что работа, за которую мы сначала взялись вследствие какого-либо косвенного интереса и на которой мы сначала должны были произвольно, с большим усилием удерживать внимание, постепенно сама начинает интересовать нас. Возникает непосредственный интерес к работе, и внимание начинает уже непроизвольно сосредоточиваться на ней. Это — нормальное течение внимания в трудовом процессе. С помощью одних произвольных усилий, без всякого непосредственного интереса к самой деятельности нельзя успешно работать в течение долгого времени, так же как нельзя вести длительную работу на основе одного лишь непосредственного интереса и непроизвольного внимания; время от времени необходимо вмешательство произвольного внимания, так как в силу усталости, скучного однообразия отдельных этапов, всякого рода отвлекающих впечатлений непроизвольное внимание будет ослабляться. Итак, выполнение всякой работы требует участия и произвольного и непроизвольного внимания, постоянного чередования их.
В итоге мы можем сказать: центральное значение в организации внимания имеют задачи, которые ставят перед нами жизнь и та деятельность, которой мы заняты. Исходя из этих задач, мы сознательно направляем своё произвольное внимание, этими же задачами определяются наши интересы — главные двигатели непроизвольного внимания.
Из книги Общая психология автора Первушина Ольга НиколаевнаВНИМАНИЕ Вниманием называется выделение, выбор актуальных, личностно значимых сигналов. Как и память, внимание относится к так называемым «сквозным» психическим процессам, так как присутствует на всех уровнях психической организации.Традиционно внимание связывают
Из книги Психология автора Крылов Альберт АлександровичГлава 25. ВОЛЯ КАК ПРОИЗВОЛЬНОЕ УПРАВЛЕНИЕ ПОВЕДЕНИЕМ § 25.1. ВОЛЯ КАК ПСИХОФИЗИОЛОГИЧЕСКИЙ ФЕНОМЕНВ процессе эволюции нервная система становится не только органом отражения окружающей действительности и состояний животных и человека, но и органом их реагирования на
Из книги Мой метод: начальное обучение автора Монтессори МарияВнимание
Чего мы прежде всего ждем от ребенка, помещенного в обстановку внутреннего роста: вот он сосредоточит свое внимание на каком-либо предмете, использует этот предмет в соответствии с его назначением и будет бесконечно повторять упражнения с данным предметом. Один
Один
Внимание Искусство — это хореография внимания.Вы стоите перед красивым зданием. Оно представляется вам осмысленным целым. Затем ваше внимание переключается на колонны, расположение окон, козырек крыши, затем обратно на здание в целом, потом вновь на подробности:
Из книги Социальное влияние автора Зимбардо Филип Джордж Из книги Психология: Шпаргалка автора Автор неизвестен Из книги Элементы практической психологии автора Грановская Рада МихайловнаВнимание Вот какой рассеянный С улицы Бассейной! С.
Из книги Шпаргалка по общей психологии автора Войтина Юлия Михайловна57. НЕПРОИЗВОЛЬНОЕ ВНИМАНИЕ Непроизвольное внимание – это внимание, возникающее без всякого намерения человека, без заранее поставленной цели, не требующее волевых усилий.Существует сложный комплекс причин, вызывающих непроизвольное внимание. Эти причины можно
Из книги Психология воли автора Ильин Евгений ПавловичГлава 2. Воля как произвольное управление поведением и деятельностью
Воля как произвольное управление поведением и деятельностью
2.3. Воля — это волевая регуляция или произвольное управление? Трудно сказать по какой причине, но в психологии утвердилось понятие «психическая регуляция», а не «психическое управление». Поэтому, очевидно, применительно к воле в большинстве случаев психологи говорят о
Из книги Квантовый ум [Грань между физикой и психологией] автора Минделл Арнольд3.2. Функциональные системы и произвольное управление действиями и деятельностью Со времен И. П. Павлова понимание физиологических механизмов управления поведением значительно продвинулось. Представление о рефлекторной дуге было заменено на представления о
Из книги Флипноз [Искусство мгновенного убеждения] автора Даттон Кевин5.3. Произвольное внимание как инструмент самоконтроля
Получение информации по каналам «обратной связи» и ее анализ возможны только в том случае, если в процесс управления и регуляции включено произвольное внимание. Как и непроизвольное внимание, произвольное внимание
Как и непроизвольное внимание, произвольное внимание
Внимание Истинная ценность понимания заключается в том, что оно мотивирует вас быть более внимательным ко всему. Мы знаем по собственному опыту: обратив на что-то внимание, мы начинаем воспринимать это по-другому. Так, бездумное поглощение пищи вызывает у нас совершенно
Из книги автора Из книги автораВнимание Ежечасно, ежеминутно тысячи внешних стимулов лезут нам в глаза и уши, затопляя наши мозги. При этом осознаем мы – просто обращаем внимание – лишь горстку из них. Присмотритесь к тому, что вы делаете прямо сейчас, например, читая эту книгу. Поднимая глаза от текста,
Виды внимания, типы и свойства: произвольное, непроизвольное
Внимание – это когда человек избирательно направляет и сосредотачивает свое сознание на объекте или определенной деятельности. У индивида при этом повышается сенсорная и двигательная, и интеллектуальная активности. У внимательности основа органическая, представляющая особую структуру мозга, обеспечивающая функционирование этого параметра и отвечающая за проявление характеристик внешнего плана. В мозге за внимательность отвечают особые клетки – нейроны, которых специалисты называют ещё детекторами новизны.
У внимательности основа органическая, представляющая особую структуру мозга, обеспечивающая функционирование этого параметра и отвечающая за проявление характеристик внешнего плана. В мозге за внимательность отвечают особые клетки – нейроны, которых специалисты называют ещё детекторами новизны.
Для чего нужна внимательность?
Отвечают на данный вопрос функции, осуществляемые вниманием. Важность внимательности можно обозначить на простейших ситуативных примерах из ежедневной деятельности человека, проиллюстрировав произведение о «рассеянном с улице Бассейной». Так, невнимательность может привести к совершению ошибочных действий. При некоторых психических расстройствах невнимательной в крайних ее проявлениях выступает в качестве симптома недуга. Невнимательность у детей может свидетельствовать о замедленных процессах развития. Так, может быть нарушено произвольное внимание.
Психологи выделяют следующие основные функции:
- бдительность;
- реакция на сигналы и их обнаружение;
- функции поиска;
- избирательность;
- распределение.

Бдительность важна при обеспечении чувств личной безопасности. Функции поиска также напрямую связаны с внимательностью. Так, развитию этого качества посредством поиска способствует такая простая школьная методика, как работа над ошибками и проверка собственной работы на предмет их наличия. Это не просто развивает внимательность, а формирует непроизвольное внимание.
Важна внимательность в сфере интеллектуальной работы. С целью выявления степени его сформированности и развитости, используются различные методики.
Кроме того, в психологии используется такие понятие, как признаки внимания. К их числу можно отнести пантомические особенности поведения: замирание, задержка дыхания или его замедление, проявляющиеся в сосредоточенности на определенном объекте, при интеллектуальной работе. Так, сегодня в числе наиболее изученных – зрительное внимание. Признаком его проявления является созерцание или разглядывание видимых предметов, способность к запоминанию их расстановки или внешних особенностей. Развивают зрительное внимание детей посредством цвета или формы. Развитие слухового внимания основывается на способностях к запоминанию звуков, произношений.
Развивают зрительное внимание детей посредством цвета или формы. Развитие слухового внимания основывается на способностях к запоминанию звуков, произношений.
Внимательность во всем своем многообразии
Такой параметр, как внимательность, в рамках психологической науки также подвержено классификации. Выделяют следующие виды внимания:
- непроизвольное;
- произвольное;
- послепроизвольное.
В основе классификации заложены принципы сознательности выбора, его направленности и регуляции. Также важно упомянуть, что нижеописанные виды внимания никак нельзя рассматривать по отдельности.
Непроизвольное внимание
Чтобы оно себя проявило, человеку не требуется прилагать особых усилий. Достаточно какого-то сильного раздражителя в виде нового, вызывающего интерес. Ключевой функцией непроизвольного внимания считается возможность человека быстро и адекватно ориентироваться при постоянно изменяющихся параметрах окружающего мира, выделяя объекты, имеющие важное значение в жизненном, личностном плане.
Непроизвольное внимание в медицине представлено несколькими синонимами – пассивная внимательность или эмоциональная. Этим подчеркивается, что у индивидуума отсутствуют усилия, направленные на сосредоточение на объекте. Отмечается наличие связи между объектами внимания и его эмоциями.
Произвольное внимание
Имеет также следующие синонимы в литературе – активное или волевое. Данному типу характерно целенаправленное сосредоточение сознания вкупе с усилиями воли. Человек, поставивший перед собой некую задачу и осознанно вырабатывающий программу по ее достижению, запускает свое произвольное внимание. А оно начинает регулировку протекающих в мозгу психических процессов. Чем сильнее воля у индивидуума, тем больше сил он сможет мобилизовать на решение поставленных задач. Благодаря этой функции, человек может извлекать из своей памяти только необходимую для этого информацию, выделяя из всего объема памяти самое главное.
На основании этой особенности работает и развитие произвольного внимания. Обычный человек без специальных тренировок способен использовать его около 20 минут.
Послепроизвольный вид
Послепроизвольный вид возникает в ситуациях, когда задача из первостепенной переходит в обыденную. Как пример можно привести школьника с его домашними заданиями. В первое время он усилием воли садится за их выполнение, но постепенно этот процесс становится обыденностью, и для его выполнения не нужно волевого усилия с его стороны. Послепроизвольный вид – это привычка к чему-то.
По психологическим характеристикам данный вид несколько схож с непроизвольным. Длительность проявления послепроизвольной внимательности может равняться нескольким часам. Его активно используют в педагогической практике, искусственно вводя школьников в состояние послепроизвольного внимания.
Другие виды и свойства внимания
Кроме этих вышеописанных, относящихся к основным, существует еще несколько:
- Природное внимание – дается человеку с рождения. Оно выражается в избирательном реагировании индивидуума на стимулы с элементами новизны. И неважно внутренние они или внешние. Основной процесс, обеспечивающий данные типы внимания, частности их деятельность – это ориентировочный рефлекс;
- Социально обусловленное внимание является результатом обучения и воспитания человека. Имеет тесную связь с регуляцией поведения при помощи воли и сознательно-избирательным реагированием на объект внимания;
- Непосредственное внимание – управляется только тем объектом, на которое оно направлено и если объект внимания полностью соответствуют потребностям и интересам человека в данный момент;
- Опосредствованное внимание. Ее регуляция происходит при помощи специальных средств, в число которых входят жесты, слова, указующие знаки или предметы;
- Чувственное внимание – является частью с эмоциональности человека и избирательной деятельностью его органов, отвечающих за чувства;
- Интеллектуальное внимание контактирует направленностью и сосредоточенностью человеческой мысли.
Свойства и проявления внимательности не подвержены классификации. А наблюдать их можно в ходе интеллектуальной деятельности. Так, это способность к сосредоточенности, переключения с одного вида деятельности на другую работу. Учитывается и такая характеристика, как интенсивность. Она зависит от психологической значимости и важности для индивидуума интеллектуальной или иной деятельности.
Концентрированность – способность сосредоточения на конкретном объекте в течение длительного периода времени, является одним из основных признаков внимательности.
Развитие внимание
Практически все формы внимания можно развивать. Этому способствует учебная, интеллектуальная и трудовая деятельность человека. При этом рекомендуется создавать для него условия, способствующие формированию:
- интеллектуальная работа в условиях отвлекающих факторов, при этом, добиваясь того, чтобы человек на них не отвлекался;
- добиться от человека того, чтобы он осознал, что осваиваемый им труд имеет общественное значение, и он должен нести ответственность за выполненную им работу;
- распределение и объем внимания можно сформировать в качестве определенного трудового навыка или интеллектуальной деятельности путем одновременного выполнения нескольких действий в условиях, когда темп деятельности нарастает. Таким способом развивают, например, зрительное внимание. Присутствует и классификация по степени сложности различных методик.
Устойчивость внимательности можно обеспечивать развитием волевых качеств индивида. Переключение развивается подбором специальных упражнений. Метод нередко применяется, когда важно развитие произвольного внимания. Единственное условие обучения – это делать любую работу качественно.
Автор статьи: Сюмакова СветланаУпражнения для тренировки памяти и внимания
Подготовка к экзамену — это самый важный этап, без которого нельзя сдать ОГЭ и ЕГЭ. Для эффективной подготовки психологами было создано большое количество развивающих упражнений, которые способны улучшить такие необходимые навыки, как память, внимание и концентрация. В этой статье будут приведены факты, благодаря которым подготовка к ЕГЭ будет простой и эффективной.
Развитие памяти и внимания
Чтобы информация запоминалась проще и быстрее, нужна тренировка памяти. Для этого ученые и психологи создали многочисленные тесты и упражнения.
Улучшают память с помощью разных мнемотехник. Например, банальное подчеркивание в тетради важных дат и обведение в рамочку формулы концентрирует мозг на этом выделении и помогает лучше на нем сфокусироваться.
Развитие внимания — это пункт, без которого нельзя обойтись. На внимании основан успех запоминания большого объема информации.
Особенности развития внимания и памяти
Тренировку памяти лучше начать после прохождения теста, который бы показал насколько эффективно вы пользуетесь памятью, и какой вид памяти у вас лучше всего развит.
Существует 4 вида памяти:
- Зрительная — это то, как вы запомнили информацию в образной форме, которую вы увидели.
- Слуховая — это запоминание услышанной информации.
- Двигательная — отвечает за ваши конспекты и ведение тетради. Люди с двигательной памятью хорошо запоминают информацию только, если запишут ее.
- Комплексная — это память, объединяющая в себе 2 или 3 вышеперечисленных вида.
Особенности занятий заключаются в индивидуальном подходе к каждому виду памяти. Упражнения нужно открывать только после прохождения теста и выявления более развитого вида памяти у занимающегося. Таким образом человек может развить любой тип своей памяти.
Виды внимания
Внимание — это процесс мозговой активности, способность концентрации на чем-либо. Психологи выделяют 3 вида внимания: непроизвольное, произвольное и послепроизвольное.
Непроизвольное
Непроизвольное внимание возникает неожиданно, независимо от сознания. Оно не требует каких-то волевых усилий. Его еще называют пассивным или вынужденным вниманием. Примером такого вида можно привести ситуацию с громкими звуками, яркими вспышками, когда человек невольно и несознательно обращает внимание на подобные раздражители.
Произвольное
Произвольный — это вид внимания, когда человек подсознательно концентрируется на чем-либо. Произвольное внимание в основном требует волевых усилий. В качестве примера можно привести ситуацию, когда ученик прикладывает усилия, чтобы не уснуть и доделать домашнюю работу.
Послепроизвольное
Послепроизвольный вид, как и произвольный, носит подсознательный характер, но при этом не требует особых волевых усилий. Управляется чаще интересом. Как пример, можно привести прочтение книги. Изначально человек концентрируется на сюжете с помощью волевых усилий, но затем интерес погружает индивида в чтение, и ему уже не нужно делать над собой усилия, чтобы закончить книгу.
Упражнения на развитие внимания и концентрации
Упражнение «Линия»
Возьмите белый лист бумаги и начните медленно рисовать прямую линию. Все ваши мысли должны быть сосредоточены только на этой линии, если вы отвлекаетесь на что-то еще, то делайте маленькую черту вверх, как на кардиограмме. Высоким результатом концентрации будет результат, где в течение 3 минут вы не сделаете ни одной черты вверх.
Упражнения на развитие памяти
Упражнения, рекомендованные психологами и учеными.
Для развития зрительной памяти
Лучше всего подойдет игра «Найди 10 отличий». Достаточно простое развлечение, но для тех, кто не обладает достаточным вниманием и концентрацией, эта игра может показаться не такой уж и легкой. Доступность ее в виде приложения на гаджетах также является большим плюсом.
Бросьте на пол 5 спичек и в течение нескольких секунд запомните их расположение. После этого отвернитесь и попробуйте сделать точно такую же картинку из 5 других спичек.
Упражнения для слуховой памяти
Для этого упражнения понадобится музыкальное сопровождение. Нужно включить на плеере любую песню и прослушав какую-то часть, поставить на паузу. Затем попробуйте продолжить воспроизведение куплета у себя в голове. Отличным результатом будет возможность полностью мысленно прокручивать и останавливать любимую песню.
Чтение вслух хорошо развивает слуховую память, способствует увеличению словарного запаса, улучшению дикции и интонации. Читать нужно не торопясь в оптимальном разговорном темпе.
Упражнения для двигательной памяти
Расположитесь на табурете лицом к стене, предварительно повесив на уровне глаз лист бумаги. Закройте глаза и нарисуйте точку в любом месте листа. После положите руки на колени, досчитайте до 5 и постарайтесь нарисовать точку в том же месте, при этом не открывая глаза. Чем меньше расстояние между точками, тем лучше развита двигательная память. При частых повторениях промежуток между точками будет сокращаться.
Выставьте перед собой обе руки, как будто держите 2 колеса. Начните вращать воображаемые колеса в разные стороны. Как только поняли, что получается, поменяйте направление.
Упражнения на развитие мышления
Мышление также имеет несколько видов: образное, абстрактное, логическое, творческое.
Образное мышление — это вид мышления, характеризующийся опорой на представления и образ. Например, художник в деталях задумал картину и рисует ее.
Упражнения:
Вспомните несколько людей, с которыми вы сегодня общались: изобразите в деталях их одежду, прическу, цвет глаз.
Изобразите каждый из перечисленных ниже предметов:
- лицо человека;
- друг детства;
- бегущая собака;
- ваша спальня;
- закат;
- летящий орел;
- журчащий ручей;
- капля росы;
- перистые облака;
- клавиатура компьютера;
- дубрава;
- снежная вершина;
- зубная щетка;
- ваша любимая пара обуви.
Абстрактное мышление характеризуется тем, что человек вычленяет какие-то особые детали из полной картины. Такой вид мышления часто бывает полезным при решении задач ЕГЭ по математике, когда нужно обратить внимание на какую-то незначительную деталь и по ней прийти к ответу.
Пример упражнения: поставьте таймер на 3 минуты и напишите максимальное количество слов, которые бы начинались на буквы «К», «Ж», «М» и «Й».
Логическое мышление — это основа и способность человека рассуждать последовательно и без противоречий. Для развития логического мышления рекомендуют решать логические задачи. Но есть также и упражнения:
1.Игра «Найди лишнее слово». Из нескольких наборов слов, например, «храбрый, злой, смелый, отважный» нужно найти лишнее. Игра достаточно простая, но она подходит для развития логики.
2.Игра «Найди отличия в каждой паре слов»:
- поезд — самолет;
- лошадь — овца;
- дуб — сосна;
- сказка — стихотворение;
- натюрморт — портрет.
Творческое мышление — это вид мышления, связанный с созданием или открытием чего-либо нового. Например, хорошим творческим мышлением обладал французский писатель Жюль Верн, который в своих произведениях придумывал новую технику для того времени: самолеты, подводную лодку.
Упражнения:
- Нарисуйте 9 точек, а теперь попробуйте соединить их 4 отрезками. Отрывать карандаш от бумаги нельзя, при этом линия может проходить через точку всего 1 раз.
- Выберите стихотворение, которое вам нравится. Используйте его последнюю строку в качестве первой строки вашего собственного стихотворения.
Концентрация и устойчивость внимания
На развитие внимания влияют многие факторы: генетика, окружающая среда, уровень концентрации и опыт. Поэтому если вы желаете развить внимание и концентрацию, то для этого предстоит выполнять несложные упражнения.
Есть специальные таблицы Шульте, которые направлены на развитие концентрации. В них вразброс написаны числа от 1 до 25, которые необходимо быстро и последовательно находить.Возьмите 2 карандаша и начните рисовать ими одновременно. Одной рукой — окружность, а второй — треугольник. Круг должен быть ровным, а треугольник — с острыми углами. Выполняйте это задание в течение минуты, чем больше получилось нарисовать, тем лучше.
Игра «Не называй число» тоже влияет на развитие внимания. Надо посчитать до 100, но вместо каждого пятого числа говорить «я внимателен».
Все эти упражнения помогут вам подготовиться к экзамену. Ваше внимание, память и концентрация дойдут до идеала, и вы уже не будете отвлекаться.
Не забудьте про метод ассоциаций. Это первый способ запоминания информации, который необходимо освоить. Применение метода ассоциаций способствуют развитию творческого мышления и совершенствует механизмы запоминания. Наиболее широко распространен прием ассоциативного запоминания, основанный на образности мышления. Например, на уроках русского языка данный прием используется для запоминания правильности написания словарных слов. Орфограмма представляется в виде яркого образа.
Упражнение для развития «метода ассоциаций»
Берутся любые 2 слова. Требуется связать их цепочкой слов-ассоциаций. Для связи следует использовать слова, между которыми есть что-то общее или, наоборот, что-то противоположное. Например, пара слов часы — облако. Из них можно сделать такую цепочку: «Часы — Время — День — Солнце — Небо — Облако». Главное в упражнении — это установить связь между словами.
Итак, это и есть основные способы для подготовки к тестам и хорошей сдачи экзамена. Тренировка мозга и развитие внимания продолжаются и во время обучения. Выполнив все пункты, изложенные выше, можно рассчитывать на высокий балл ЕГЭ. И учеба, в свою очередь, станет даваться легче и интереснее.
Устойчивость внимания: меньше, чем у золотой рыбки?
- Саймон Мейбин
- Всемирная служба Би-би-си, программа «More or Less»
Автор фото, Getty Images
Вы наверняка даже не сможете дочитать до конца эту статью, ведь все знают, что устойчивость внимания современного человека становится все короче — это же так естественно! Или нет?
Трудно фокусироваться на чем-то одном в нынешней действительности, состоящей из соцсетей, смартфонов и гипертекстовых ссылок, вторгающихся именно в тот момент, как вы что-то читаете.
Статистика это тоже подтверждает.
По данным различных исследований, концентрация нашего внимания сократилась с 12 секунд в 2000 году до 8 секунд в настоящий момент — то есть стала меньше, чем у среднестатистической аквариумной рыбки, которая в состоянии поддерживать свое внимание в течение 9 секунд.
Но если вы обратите внимание на то, откуда поступают эти цифры, картина оказывается не такой простой.
Все эти утверждения основаны на отчете, подготовленном в 2015 году группой, изучавшей потребительские предпочтения для канадского отделения компании Microsoft, на основании опроса 2000 канадцев и исследования активности головного мозга у 112 человек во время того, как те занимались разнообразными делами.
Те цифры, которые все издания потом подхватили — о нашей сокращающейся устойчивости внимания, — на самом деле не были получены во время исследования Microsoft. Они действительно впервые появились в этом отчете, но были взяты из другого источника — Statistic Brain.
Автор фото, iStock
Быстрый поиск в Google выводит нас на первоисточник. Видно, что вебсайт Statistic Brain тоже выглядит вполне заслуживающим доверия. Там даже говорится, что авторы сайта «любят цифры, их чистоту и то, о чем они говорят» — как раз с такими людьми мы в программе More or Less и любим иметь дело.
И в качестве доказательства любители цифр с сайта Statistic Brain приводят источники всех своих цифр — откуда они взяты. Однако источники эти своей туманностью только раздражение вызывают.
А когда мы связались с упомянутыми источниками — Национальным центром по биотехнологической информации в Национальной библиотеке США по медицине, а также с Associated Press — никто не смог предоставить никакого свидетельства проведенных исследований, которые бы подтверждали указанные цифры.
Попытки связаться с самим сайтом Statistic Brain тоже ни к чему не привели.
Я поговорил с несколькими людьми, которые посвятили свою жизнь изучению проблем человеческого внимания, но они также не могли понять, откуда появились эти данные.
Автор фото, Getty Images
Подпись к фото,Профессор Бриггс давно изучает то, как выполнение нескольких дел сразу влияет на концентрацию внимания — например, когда человек за рулем пользуется мобильным телефоном
Все зависит от выполняемой задачи
На самом деле, по мнению этих специалистов, утверждения о том, что устойчивость нашего внимания сокращается, совершенно не верны.
«Я совершенно так не думаю, — сказала Джемма Бриггс, доктор психологических наук, преподающая в британском Открытом университете (Open University). — Просто потому, что я не думаю, что психологи или люди, которые интересуются этой проблемой, будут стараться замерять и подсчитывать это таким вот способом».
Джемма изучает внимание у водителей и очевидцев преступления и говорит, что искать среднестатистическую величину «устойчивости внимания» бессмысленно.
«Все зависит от того, чем вы занимаетесь. То, насколько мы концентрируем внимание на выполнении задачи, варьируется от того, что требует от нас эта задача», — говорит она.
Был проведен ряд исследований, когда изучалось как раз, что происходит с концентрацией внимания во время выполнения одной какой-то задачи, например, прослушивания лекции.
Однако предполагать, что существует какое-то определенное количество времени, в течение которого люди обычно сосредотачивают внимание даже на одном каком-то деле, тоже не совсем верно.
«То, как мы распределяем свое внимание на различные задачи, зависит очень во многом от того, что каждый человек привносит в эту конкретную ситуацию», — объясняет Бриггс.
«У нас имеется множество разной информации по поводу того, что обычно случается в каждой конкретной ситуации, что мы можем ожидать от нее. И вот эти наши ожидания и то, что мы испытываем — все это непосредственно сформировывает наше восприятие [ситуации] и то, как мы оцениваем получаемую информацию в каждый конкретный момент», — говорит эксперт.
Высказываются мнения и по поводу того, что все время сокращающиеся по длительности кадры в фильмах демонстрируют как раз то, что концентрация внимания уменьшается. Однако ученый, исследовавший это явление, говорит, что это всего лишь показывает, что кинорежиссеры стали более искусно манипулировать нашим вниманием.
Автор фото, Getty Images
Подпись к фото,У аквариумных рыбок не такая уж короткая память, и они могут обучаться
Интересная ирония
Кое-что еще смущает во всей этой статистике по поводу концентрации внимания.
Оказывается, нет никаких свидетельств того, что у аквариумных рыбок, или каких-либо еще, крайне недлинная устойчивость внимания или память — вопреки тому, что говорится в поп-культуре по этому поводу.
Я поговорил с профессором Фелисити Хантингфорд, которая почти 50 лет изучает поведение рыб и только что прочитала курс лекций на тему «Насколько умны рыбы?»
«Аквариумные рыбки могут обучаться всему тому, чему можно обучить животных или птиц, — говорит профессор. — Они стали модельной системой для изучения процесса обучения и формирования памяти именно потому, что у них есть память и они могут обучаться».
По ее словам, существует в буквальном смысле сотни научных работ, написанных за десятки лет, по поводу обучаемости аквариумных рыбок и их памяти. Я нашел отсылку к исследованию о природе памяти рыб, датируемую 1908 годом.
«То, что тот самый биологический вид, который изучают нейропсихологи и другие группы ученых в качестве модели для понимания формирования памяти, получил такую репутацию — я думаю, в этом заключается любопытная ирония», — говорит профессор Хантингфорд.
Итак, у аквариумной рыбки не короткая устойчивость внимания или память. Как и нет свидетельств тому, что человеческая концентрация внимания сокращается.
Программа More or Less выходит на Всемирной службе Би-би-си по пятницам.
Феномен внимания в информационной среде: экономика внимания
Современная экономика все больше вращается вокруг концентрации внимания человека, а значит, принципы управления вниманием являются определяющим звеном функционирования такой экономики. Внимание регулирует взаимодействие людей с миром как на индивидуальном, так и на социальном уровне. Кроме того, привлечение внимания и его последующая перепродажа в настоящее время является массовым бизнесом. Следуя направлению в поведенческой экономике, затрагивающему проблему ограниченного внимания и его экономических последствий, данная статья систематизирует исследования феномена внимания, актуальные в разрезе принятия экономических решений; подробно обсуждается понятие «экономика внимания», которое связано не только с распределением дефицитного внимания в информационно богатом мире, но и рассматривает внимание как базовую потребность, как валюту, богатство и капитал, а также учитывает роль брендов и «микро-звезд».
Важно, что современный подход представления информации подразумевает, с одной стороны, предложение «решений по умолчанию», рассчитывая на склонность человека предпочитать эти решения, с другой стороны – персонализированные предложения захватывают внимание быстро или даже автоматически, преследуя цель его материализации. Данная тенденция в долгосрочной перспективе приводит к деградации способности мыслить системно и анализировать информацию.
Таким образом, на первый план выходит разработка стратегии для эффективного управления вниманием, которая, с одной стороны, учитывала бы клиповый характер мышления, но позволяла минимизировать когнитивные искажения, с другой стороны – предоставляла бы некую смысловую компрессию информации вместо «готового» ответа и тем самым способствовала познанию. В данном контексте инструментарием, подходящим для управления вниманием и способствующим познанию, является тематическое моделирование, включение которого в дискурс поведенческой экономики и экономики внимания является актуальной будущей задачей.
1. Введение
В настоящее время дематериализация и виртуализация стали общими понятиями и в производстве. Мы получаем представление о физических объектах через информацию, однако информация может развернуть свой товарный характер только в том случае, если она изменяет человеческое поведение, а это, в свою очередь, возможно, только если ей уделяют внимание и эмоционально оценивают [Franck, 1993, 1999а]. Экономическое поведение определяется информацией и принципами ее подачи, а также характеризуется использованием ресурсов человеческой психики, к которым относятся внимание и эмоции [Hennric, Ewa, 2009].
Выводы, базирующиеся на многочисленных исследованиях психологов и нейробиологов, описывают следующие свойства человека при восприятии информации: склонность к принятию решений под воздействием эмоций [Damasio, 2001], автоматическая конформность, просоциальное поведение [Cialdini, Goldstein, 2004; Klucharev et al., 2009]; зависимость от скорости поступления информации по той или иной альтернативе (большинством будет выбрана альтернатива, характеризуемая более полной информацией) [Shafir, 1993]; доминирующая роль автора сообщения, а не самого сообщения [Martin, Marks, 2019].
Описанными выше свойствами легко оперировать в информационном обществе, что и происходит в настоящее время: броские заголовки, эмоциональная окраска новостей, распространение информации в социальных сетях, рост числа личных блогов и видеоканалов – все это является «эффективными» каналами распространения и привлечения внимания к информации. Таким образом, современная экономика все больше вращается вокруг концентрации внимания человека, а значит, принципы управления вниманием являются определяющим звеном функционирования такой экономики.
Происходящие изменения характеризуются кардинальной сменой распределения внимания, регулирующего взаимодействие людей с миром как на индивидуальном, так и на социальном уровне [Roda, 2019]. То, как мы распределяем внимание, определяет, какие решения мы принимаем, что, в свою очередь, влияет на экономику, политику и этику.
На уровне коллективного внимания управление действует через средства массовой информации: медиасреда определяет будущее внимание. Конкуренция за внимание постоянно растет, что приводит к увеличению объема контента, который производится за меньшее время. Недавние исследования экспериментально подтверждают, что социальное ускорение истощает внимание, стремление к «новизне» заставляет коллективно переключаться между различными темами гораздо быстрее [Lorenz-Spreen et al., 2019]. Кроме того, свойство транссортативности социальных сетей обуславливает усиление эффекта «иллюзии большинства», когда непопулярная идея может восприниматься как популярная у большой части людей [Ngo et al., 2020].
В настоящее время ученые сходятся во мнении, что способ передачи информации определяет стиль мышления: господство аудиовизуальных средств определяет его клиповый характер. Из-за невозможности осмыслить бурный поток информации человек фиксирует сиюминутные события, теряя возможность дифференцировать мусорную и полезную информацию, и потребляет более простые по форме сведения [Докука, 2013]. Таким образом, носители клипового мышления могут легко поддаваться манипуляциям: «чем больше давление мозаичной культуры, тем меньшую роль играет логика, тем более восприимчиво сознание к манипуляции» [Кара-Мурза, 2004].
«При столь серьезном изменении инфосферы мы обречены на трансформирование собственного сознания, т.е. того, как мы осмысляем свои проблемы, как обобщаем информацию, каким образом предвидим последствия наших поступков и действий» [Тоффлер, 1980]. Известно, что определенный род деятельности может приводить в перспективе к изменениям в некоторых отделах головного мозга. К примеру, в одном из исследований было показано, что способность лицензированных лондонских таксистов приобретать и использовать информацию о движении в большом и сложном для навигации городе привела к увеличению объема серого вещества в гиппокампе [Maguire, et al., 2006].
Таким образом, на первый план выходит разработка стратегии для эффективного управления вниманием, которая, с одной стороны, учитывала бы клиповый характер мышления, но позволяла минимизировать когнитивные искажения, с другой стороны – предоставляла бы некую смысловую компрессию информации и способствовала познанию. Важно, что развитие методов машинного обучения и анализа естественного языка позволяет реализовывать альтернативный подход к представлению информации, ставя перед собой цель получения не быстрого или фрагментарного ответа, а дорожную карту исследуемого направления. К таким методам относится тематическое моделирование – направление, активно развиваемое в области компьютерных наук, начиная с конца 90-х годов [Hofmann, 1999; Blei, et.al. 2003; Воронцов, Потапенко, 2012, 2014].
Следуя направлению в поведенческой экономике, затрагивающему проблему ограниченного внимания и его экономических последствий [см., например, обзор Festré and Garrouste, 2015], данная статья систематизирует исследования феномена внимания, актуальные в разрезе принятия экономических решений (Раздел 2), обсуждается понятие экономики внимания (Раздел 3). В работе освещается мысль о необходимости использования иных алгоритмов работы с информацией, позволяющих повысить эффективность управления вниманием (Раздел 4). Так, базовый на текущий момент подход к поиску и представлению информации может оказаться несостоятельным при рассмотрении его в долгосрочной перспективе.
2. Внимание в информационной среде
Вопрос о том, что такое внимание, интересовал философов и ученых не одно столетие. В контексте обсуждения внимания как ресурса современные публикации [Wickens, 2006; Wu, 2015; Hendricks, Vestergaard, 2019 и др.] адресуют к трудам философа и психолога Вильяма Джеймса:
«Пристрастное, осуществляемое посредством умственной деятельности обладание в ясном и чётком виде одним из нескольких, как кажется, одновременно возможных объектов или рядов мысли. Фокусировка, концентрация сознания — его суть. Это означает отказ от каких-то вещей, чтобы эффективно заниматься другими» (Вильям Джеймс о внимании, James, 1890, pp. 403–404). Более того, с точки зрения Джеймса, жизненный опыт представляет собой то, на что мы соглашаемся обращать внимание [James, 1890, p. 402].
Внимание характеризуется как «клей», который связывает воедино все различные компоненты познания и обработки информации человеком (память, восприятие, выбор действий) или, в некоторых случаях, наоборот, не способный связать данные компоненты, создавая неудачи и ошибки [Wickens, 2006]. С другой стороны, нейрофизиологами давно доказано [см., например, обзор Chun and Wolfe, 2001], что окружающая среда предоставляет гораздо больший объем информации, чем он может быть обработан человеком. Чтобы справиться с потенциальной перегрузкой, мозг оснащен системами внимания. Во-первых, внимание может быть использовано для выбора «необходимой» информации и/или для игнорирования несоответствующей или мешающей информации. Во-вторых, внимание может модулировать или усиливать эту выбранную информацию в соответствии с состоянием и целями воспринимающего.
Теории выборочного внимания (selective attention) развиваются, начиная с 50-х годов, причем по мере появления новых методов функциональной диагностики интерес к данной области постоянно растет, а понимание принципов работы механизмов – пересматривается. Так, в ранних работах, внимание рассматривается как механизм защиты некоторого канала с ограниченной пропускной способностью от перегрузки. Данный подход можно назвать наследием теории информации Шеннона, который допустил, что в любой системе передачи информации есть канал с ограниченной пропускной способностью, который выдает ошибки в случае перегрузки. Человек в данном контексте рассматривается как система переработки и передачи информации. Концепция внимания рассматривалась как фильтр или «узкое место» [Broadbent, 1958; Simon, 1994], как усилие по распределению ограниченных ресурсов [Kahneman, 1973], как цикл восприятия, предполагающий активное предвосхищение событий на основе существующих схем и последующую модификацию схем в процессе сбора информации [Neisser, 1976]. В соответствии с современной концепцией, внимание рассматривается в контексте двух встречных информационных потоков: потока восходящего – управляемого текущими данными, и потока нисходящего – определяемого обработкой информации, связанной с опытом, конкретной задачей, ее контекстом [Lavie, 2005; Фаликман, 2018]. На стыке этих потоков возникает правильно или неправильно решенная задача. Таким образом, большое число разнородных источников информации, отвлекающих стимулов (distractors), особенно, связанных с эмоциями, способны истощать внимание, а значит и результирующее познание, определяемое первоначальной мотивацией.
Несмотря на то, что теории внимания были опробованы в основном в лабораторных условиях, есть все основания полагать, что они могут быть применены к реальным задачам [Murphy et al., 2016]. Одним из примеров таких задач может быть поиск необходимой информации (в сети Интернет), осложненный обилием мусорной, продвигаемой и эмоциональной информации.
Отметим, что вопросы выборочного внимания также актуальны в контексте либертарианского патернализма или теории подталкивания [Thaler, Sunstein, 2008; Паниди, 2017; Белянин, 2018], рассмотренного в информационной среде. Основная критика теории подталкивания затрагивает вопросы навязывания чуждых поведенческих норм [Капелюшников, 2013], манипулирования на основе несогласованного сбора большого количества личной информации – big nudging [Helbing, 2019], перехода «подталкивания» в «толкание» [Sætra, 2019], а также риторики или использования речевых конструкций («либертарианский патернализм»), ставших частью мейнстрима [Рубинштейн, 2019]. Однако важным аспектом является то, что в цифровой эпохе, характеризуемой перенасыщением информации и дефицитом внимания, спрос на свободу выбора замещается спросом на получение быстрого ответа. Можно сказать, что либертарианский патернализм замещается «рациональным патернализмом» (название – по аналогии с «рациональным неведением»), когда выбрать опцию, предлагаемую по умолчанию, выгоднее с точки зрения затрат, чем производить поиск альтернативных решений.
Среди экономистов проблемой поиска информации занимался Саймон, для которого данный процесс был интересен в тех случаях, когда не все альтернативные варианты действий представляются изначально, а должны быть найдены с помощью каких-либо дорогостоящих мер. По Саймону, в данном вопросе важно не то, как ведется поиск, а то, как принимается решение о его прекращении. Иначе говоря, речь идет о количестве просмотренных вариантов, однако, с увеличением объема поиска возрастают издержки. Поиск прекращается, когда лучший из предложенных вариантов превосходит уровень притязаний, который сам постепенно корректируется в соответствии с ценностью предлагаемых вариантов [Simon, 1978]. Схожих взглядов придерживался и Талер, подтверждающий в ходе экспериментов, что «людям свойственно искать, прежде всего, подтверждающее доказательство, нежели опровергающее» [Талер, 2017].
Проведенный анализ изменений страницы выдачи результатов поисковых систем (Search Engine Results Page, SERP) демонстрирует очевидный тренд в сторону введения дополнительных структурных элементов, преследующих двоякую цель: с одной стороны, это получение максимально быстрого ответа на запрос пользователя, с другой – увеличение времени пребывания на странице SERP [Милкова, 2019a]. Поисковые системы, отображая прямые ответы на запросы пользователя, параллельно показывают персонализированные рекламные объявления: чем дольше пользователь находится на странице SERP, тем выше вероятность, что он перейдет по рекламной ссылке. Поисковая система как бы предлагает нам решение по умолчанию, и склонность человека выбирать это решение (если оно не противоречит его предпочтениям) приводит к деградации способности осуществлять итерационный поиск. Глобальная смена принципов работы с информацией, направленная на предоставление готовых ответов и решений, очевидно, может привести к долговременным негативным последствиям, включающим ослабление способности анализировать и мыслить системно.
3. Экономика внимания
3.1. Истоки
Изменившийся мир вывел на первый план информацию и работу с ней как определяющий фактор развития экономики. Некоторые исследователи называют такую экономику – информационной [одним из первых – Porat, 1977], однако, существует мнение, что данная терминология является не совсем корректной, так как по определению, экономика — это изучение того, как общество использует ограниченные ресурсы. Информация же в настоящее время предстает перед нами в избытке, а дефицитным ресурсом является внимание, поэтому именно экономика внимания является естественным названием экономики в киберпространстве [Goldhaber, 1997b; Hendricks, Vestergaard, 2019].
Вопрос об эффективном управлении вниманием как дефицитным ресурсом в информационно богатом мире был описан еще 50 лет назад Гербертом Саймоном, который отмечал, что переизбыток информации рождает нехватку внимания и необходимость его более эффективного перераспределения между многочисленными источниками информации [Simon, 1971]. Саймона часто считают отцом-основателем экономики внимания, однако важно отметить, что он рассматривал её только для человека или организации, которые стремятся разумно распределить ограниченный ресурс (внимание), и не изучал внимание как мотивирующий фактор в производстве информации.
Сам термин «экономика внимания» появился значительно позже и был введен параллельно двумя учеными: Майклом Голдхабером [Goldhaber, 1997a] и Георгом Франком [Franck, 1993]. И Франк, и Голдхабер пришли к понятию экономики внимания независимо друг от друга, так как первая работа Франка «Экономика внимания» (Ökonomie der Aufmerksamkeit) была написана на немецком языке [Franck, 1993] и известность получила, только будучи переведенной на английский [Franck, 1999а].
Понимание внимания как новой валюты бизнеса [Davenport, Beck, 2001], а также принятие рынков внимания всерьез [Wu, 2017] представляется важным с точки зрения представления о принципах принятия решений человеком, а также особенностей функционирования современной экономики. Получив начальный импульс в 90-х годах, теория экономики внимания постепенно развивалась, хотя и не являлась доминирующим направлением ни в рамках поведенческой экономики, ни как самостоятельная область. Однако понятие внимания, будучи включенным в дискурс экономических и компьютерных дисциплин, играет все большую роль.
3.2. Привлечение внимания как базовая потребность, ставшая массовым бизнесом
Привлечение внимания как основная человеческая потребность впервые рассматривается в работах пионеров экономики внимания – Георгом Франком и Майклом Голдхабером. С ростом общего благосостояния общества стремление к отличию создает спрос на характеристики, которые являются более избирательными, чем денежный доход, поэтому значительная часть сегодняшней деятельности связана именно с транзакциями внимания, а не с денежными транзакциями. Все большую актуальность получает измерение дохода в терминах внимания, доход от которого ценится выше денежного. «Потребление связано с чувством собственного достоинства, поэтому в обществе, где доход, полученный от внимания, является основной целью, потребление будет следовать за стремлением к самооценке» [Franck, 2005].
Привлечение внимания с помощью медиа Франк рассматривает как массовый процесс, где «известные люди нужны в массовом порядке, если кто-то хочет сделать привлечение внимания массовым бизнесом» [Franck, 1993; 1999a]. Очевидно, что причина популярности медиа лежит не в потребности получения информации, а в разрастании бизнес-идеи о предоставлении информации, чтобы поддерживать внимание. Экраны конкурируют с непосредственным представлением о реальности, навязываются как обязательные единицы в бюджете внимания, что складывается только в том случае, если представляемая ими реальность неизменно отражает ту информацию, которую хотят потреблять массы [Franck, 1993, 1999а]. Таким образом, круговорот информация-внимание действует так: люди обращают внимание на поставщика информации в обмен на выяснение того, что им нравится.
Обсуждая вопрос о том, какой именно фактор послужил причиной того, что обмен информации на внимание стал массовым бизнесом, Франк отмечает мутацию культурной жизни в массовый бизнес [Franck, 2005]. Данный факт стал возможен благодаря развитию технологической инфраструктуры, обеспечивающей массовое распространение информации, а также эволюции определенных типов популярной культуры, вовлеченной в поиск того, что именно аудитории интересно видеть, слышать и читать.
На рынке внимания (attention market) покупатели согласны получать услуги в обмен на свое внимание [Iskold, 2007] или, что, по сути, то же самое, на время [Evans, 2020]. Конечной целью является продажа чего-либо, однако она может быть не прямой и не мгновенной. Ключевым элементом в борьбе за внимание является релевантность предоставляемой информации – пока потребитель видит релевантный контент, он будет оставаться на месте, что создает больше возможностей для продажи. В условиях обилия всевозможных альтернатив ошибки могут стоить очень дорого, они, по сути, отменяют сделку (посетитель уходит на другой сайт/сервис). Однако сайты не могут создавать релевантный персонализированный контент, если они не знают пользователя – чтобы задерживать внимание, необходимо обладать информацией о посетителе. Очевидным следствием данной необходимости является вопрос о приватности предоставляемой информации. И задача состоит не только в защите информации потребителей, но и в том, чтобы дать пользователю контроль над информацией о себе. Искольд [Iskold, 2007] подчеркивает, что для честной игры в экономике внимания важно, чтобы внимание обладало, в том числе, такими свойствами, как: принадлежность пользователю, прозрачность использования, стоимость.
В качестве координационного центра для социальной организации внимания на рынках внимания выступают «знаменитости» или «микро-звезды», производимые средствами массовой информации [Franck, 1993, 1999a]. Успешными в экономике внимания стали компании, которые вложились в технологию распространения тех, кто способен привлекать внимание масс (социальные сети, новостные сайты, телевизионные каналы, поисковые системы). Такого рода компании в разных публикациях называются брокерами внимания (attention brokers) [Wu, 2017], или агентствами внимания (attention agency) [Citton, 2019]. Их роль является ключевой в проведении операций на рынках внимания. Принятие рынков внимания всерьез важно также и с точки зрения разработки правовых норм, регламентирующих взаимоотношения на них. Очевидно, что антимонопольная политика не успела приспособиться и распознать сложности и угрозы, созданные на рынках такого рода [Wu, 2017]. В «слепой зоне» антимонопольного регулирования находятся компании, которые предоставляют свои продукты «бесплатно», однако на самом деле конкурируют на рынках внимания. В качестве наиболее ярких примеров Тим Ву, будучи профессором Колумбийского юридического факультета, приводит сделки о приобретении компанией Google компании YouTube в 2006 году и компании Waze (бесплатное приложение для мобильных устройств для навигации) в 2013 году; сделки о приобретении компанией Facebook компании Instagram в 2012 году, WhatsApp – в 2014 году [Wu, 2017, 2018]. Беспрепятственное слияние данных компаний привело к «существенному уменьшению конкуренции или созданию монополии» [Wu, 2017].
Известность — это вектор, который позволяет максимизировать финансовую доходность публичного деятеля как бренда, создавая экономическую ценность. Бренды являются нематериальными конгломератами внимания: внимание концентрируется, продается, а также может быть перемещено с одного объекта на другой. Экономика внимания учитывает роль брендов, определяющих коммуникационные процессы, структурирующие и формирующие осведомленность и внимание [Doyle, 2019]. Важным аспектом является то, что бренды и реклама служат антиконкурентным целям в том плане, что они могут сдерживать переключение между продуктами [Wu, 2017]. Например, несмотря на то что потребители одинаково оценивают напитки Pepsi и Coca-Cola, предпочтения отдаются именно Coca-Cola. В одном из экспериментов было показано, что в случае, когда Pepsi и Coca-Cola подаются вслепую, потребители дают схожие ответы об их вкусах. В случае, когда напитки подписаны, потребители склонны отдавать предпочтение Coca-Cola, при этом в ходе функциональной магнитно-резонансной томографии отмечалась сильная активность в области головного мозга, отвечающая за систему вознаграждений [McClure et al., 2004]. Таким образом, предпочтение отдается Coca-Cola исключительно из соображений лояльности к бренду, мощность которого обусловлена именно рекламной кампанией.
3.3. Ментальный капитализм
Понятие рынка внимания связано с такими понятиями, как валюта, капитал, богатство, которые также могут быть определены в терминах внимания. Во введенной Франком концепции ментального капитализма объясняется: «Внимание становится валютой, когда оно является, подобно деньгам, сопоставимой системой эквивалентности, поддающейся количественной оценке и измерению, например, в форме показателей тиража, рейтингов аудитории, показателей продаж, числа просмотров, лайков, загрузок, подписчиков и т. д.» [Franck, 2005]. Измерение внимания не просто отражает внимание аудитории, оно в свою очередь также является капиталом внимания. Точно так же, как деньги, внимание привлекает внимание.
Важно, что внимание, как таковое, не является однородной мерой стоимости: ценность внимания в межличностном обмене измеряется индивидуально и зависит от накопленного внимания. По Франку [Franck, 2005], богатые люди в экономике внимания – те, чье внимание больше, чем их расходы; бедные – те, кто не получает достаточно внимания, чтобы поддерживать свою самооценку. Богатство одних и бедность других является взаимозависимым процессом, т.к. внимание, циркулирующее в обществе, ограничено. Получаемый доход будет тем больше, чем больше восхищаются продавцом внимания, а это, в свою очередь, зависит от внимания, которое оказывается продавцу третьими лицами. Таким образом, отражение богатства внимания другого человека становится источником дохода. Рассматривая внимание как богатство, интернет является отличной площадкой для транслирования себя – число блогеров растет огромными темпами, а успех определяется числом подписчиков и «лайков».
В обществе параллельно циркулируют обмен личным вниманием и внимание, потраченное на медиаинформацию. Именно второй тип внимания, гомогенизированный количественной оценкой, способен разрастаться огромными темпами и тем самым обеспечивать известность СМИ. Объем внимания, направляемый средствами массовой информации и перераспределяемый в конкурентной борьбе за рейтинги или охват, не совпадает с общим объемом внимания, циркулирующим в обществе. Таким образом, конкуренция за внимание вывела новый тип технологий привлечения внимания, применяемый для максимизации рейтингов, наполняемости каналов и т.п.
Кроме того, на рынках внимания существует и кража внимания (attentional intrusions) [Wu, 2017], подразумевающая несогласованное получение нежелательной информации. Нейрофизиологические механизмы подтверждают данные идеи, так как определенные триггеры – движущиеся изображения, громкие звуки, яркие краски – все это привлекает внимание без принятия осознанного решения. Тем самым активируется непроизвольное внимание, что, в свою очередь, приводит к снижению произвольного внимания [Мачинская, 2003].
3.4. Технологии привлечения внимания
Итак, общая борьба за внимание ведет к массовому производству средств для привлечения внимания. Экономика внимания связана с тем, чем определяется выбор внимания, и, следовательно, с человеческими мотивами. Распределение внимания меняет наше отношение к объектам, а само внимание является производным от формы, в которой поступает объект. Введенная Ричардом Лэнхэмом концепция осцилляции (oscillatio) подразумевает, что наше внимание колеблется, переключается сначала на стиль, а потом через него – на содержание: «стиль – то, что имеет значение» [Lanham, 2006].
Так, описываемое Лэнхэмом торжество информации над объектами, стиля над содержанием («fluff» over «stuff», Lanham, 2006], несомненно, прослеживается в современном мире. Данная тенденция относится не только к информации о физических объектах, но и к информации, передающей общую картину мира, что подтверждается и отечественными учеными, занимающимися аспектами экономики внимания [см., например, Почепцов, 20017а]. Можно говорить, что «информационные войны» стали привычным явлением в наше время: «информационный инструментарий перестал просто описывать события, как это было раньше, а стал создавать их» [Почепцов, 2017б]. Таким образом, человек, попадая в поток информации, практически не способен ему противостоять. Кроме того, социальные медиа стали «машинами эмоций», которые регулярно производят более яркие, четкие и мощные эмоции, чем эмоции «настоящие» [Почепцов, 2017б]. «Человек видит мир так, как ему диктуют определенные информационные решетки. Это — язык, выделяющий значимые аспекты мира<… >но самым значимым для сегодняшнего дня стало объединение информации с эмоциями» [Почепцов, 2017б].
Внимание интернет-аудитории к тем или иным материалам привлекается не в соответствии с реальными заслугами, а в соответствии с «правильно» выбранной стратегией, предлагающей легко усваиваемую, быстродоступную информацию. Аналогично и с эмоционально окрашенной информацией: если события (в том числе и сообщения) являются эмоциональными, они захватывают внимание быстро и автоматически [Morawetz et al., 2010]. В ходе гонки за внимание самыми эффективными способами являются те, что требуют минимальных издержек – минимальных усилий на включение или же автоматическое включение, обусловленное большим вкладом эмоциональных зон мозга [Ключарев и др., 2011].
Рассмотрим далее несколько примеров, затрагивающих различные технологии и практики привлечения внимания.
В списке самых высокооплачиваемых YouTube-блогеров, составленном Forbes в 2018 году, первое место занял семилетний американец Райан (в 2017 году он также был в списках лидеров, занимая 8 позицию). Родители мальчика выкладывают видео, на котором сын играет в игрушки. Технология привлечения внимания нацелена на использовании детской аудитории, которая является наиболее «благодарной» – она не пропускает рекламу внутри видео, тем самым рекламные сообщения имеют максимальное воздействие. Данный факт объясняет стремительный рост популярности именно детских видеоблогов, в том числе и российских. Число просмотров наиболее популярных детских видео более чем в 10 раз выше, чем у самых популярных общественных деятелей; число подписчиков выше более, чем в 2 раза.
Человек, обладающий капиталом внимания имеет и влияние. Причина влияния адресует к существованию зеркальных нейронов [Gallese et al., 1996; Goldhaber, 2006], феномен которых связан с тем, что в тот момент, когда мы наблюдаем за действием других, происходит активация тех же самых нейронов, которые активировались бы, если бы данное действие выполняли мы сами. К примеру, ряд компаний делают ставку в развитии именно на продвижение своего продукта в формате видеоблогов. Так, американская компания MGAE, производитель игрушек – кукол L.O.L. разместила в магазинах, где продавались куклы, специальные будки, в которых дети сразу могли снять процесс распаковки игрушки на видео и выложить его на YouTube. Благодаря такому подходу куклы серий L.O.L. стали самой продаваемой игрушкой за 2018 год.
Важной особенностью внимания является возможность его перенаправления. В ноябре 2019 года история о лишении миль компанией Аэрофлот пассажира, провезшего на борту кота весом выше разрешенного, вызвала шквал эмоций. Компания Аэрофлот и кот стали героями статей не только российских, но и мировых СМИ. Интересно, что внимание к данной истории привлекло не только желающих посочувствовать, но и тех, кто перенаправил данное внимание на себя. Ряд компаний, среди которых сервис заказа такси, банк, фитнес-центр, авиакомпании, производитель кормов для животных и др., успешно развернули ситуативный маркетинг, предложив каждый по-своему компенсировать убытки от потери миль, что, в свою очередь, положительно сказалось на имидже компаний и позволило расширить охват аудитории. Привлеченное к коту и его хозяину внимание также перетекло для них в материальные выгоды. Однако, как и по Голдхаберу, первичным в данной истории было не желание заработать, а желание получить внимание, опубликовав в социальной сети историю о провозе кота в самолете.
Зависимость денежного дохода от внимания подтверждается и на примерах влияния эмоциональной окраски новостей на рыночный курс рубля [Афанасьев и др., 2019], настроений комментариев в сети Твиттер – на ценообразование предметов искусства [Федорова и др. 2020]. Другим примером является привлечение дополнительного внимания с помощью негативной окраски новостей в период пандемии COVID-19, способное привести к долгосрочным негативным последствиям эпидемии [Milkova, 2020]. В целом, в ряде исследований показано, что новости, вызывающие эмоции, в особенности отрицательные, распространяются гораздо быстрее [Heath et al., 2001; Vosoughi, et al., 2018].
Технологии машинного обучения, активно развиваемые для таргетирования аудитории с целью максимального привлечения внимания, используются в том числе и для политических целей. «Классическим» примером является показ персонализированной рекламы для поддержки и манипулирования вниманием в рамках предвыборной кампании Д. Трампа, а также убеждения большинства британских избирателей покинуть Европейский Союз [Doyle, Roda, 2019].
Гонка за владение капиталом внимания приводит к росту давления информационного потока на представителей определенных профессий, к которым, помимо представителей медиа, относятся и ученые. Наука также функционирует по законам экономики внимания [Franck, 1999b, 2002, 2005]: ученые вкладывают собственное внимание, чтобы в ответ получить внимание других ученых в виде цитирований. Число цитирований определяет значимость научной информации. Цитирование же со своей стороны является платой за использование информации. Научная экономика внимания – также капиталистическая. Индекс научного цитирования (SCI) является функциональным эквивалентом финансового капитала. Франк называет научную коммуникацию – ярмаркой тщеславия [Franck, 1999b], где внимание является средством продвижения науки.
Брайан Носек (Brian Nosek), профессор Университета Вирджиния, руководитель группы по защите научной целостности Центра Открытой Науки, комментирует, что, попадая на рассмотрение в научный журнал, статья, прежде чем перейти к слепому рецензированию, должна привлечь внимание редактора, который заинтересован, чтобы выпускаемый им номер было интересно читать. Однако существует склонность «упускать из виду неопределенность таких результатов». Поэтому захватывающие, необычные результаты публикуются гораздо чаще. Результаты, которые являются и захватывающими, и научно обоснованными редки, поэтому большой преградой на пути развития науки является именно предпочтение интересных результатов научнообоснованным.
Причина, почему техники привлечения внимания в науке также выходят на первый план, достаточно очевидна – это рост общего объема публикаций. Условие полного информирования об исследуемой проблеме при проведении исследования становится невыполнимым: существует стремление «сделать обзор глубоким и полным, не забывая ни отечественных, ни зарубежных авторов, но, двигаясь по ссылкам, упираешься в бесконечность» [Козырев, 2019]. Таким образом, в индустрию знаний вступают те же самые законы привлечения внимания, что и в СМИ: броские заголовки, радикальные переосмысления и т.п.
4. Подход смысловой компрессии информации
Чтобы предотвратить доминирование когнитивных искажений при восприятии информации, важна разработка альтернативного подхода к поиску и представлению информации, который, с одной стороны, учитывал бы клиповый характер современного мышления, а с другой стороны – предоставлял бы дорожную карту исследуемого вопроса вместо «готового ответа».
Потребность в охвате большего объема информации, вместо обращения внимания на «основную», была впервые отмечена итальянским литературоведом Франко Моретти [Моретти, 2016]. Он отметает предпочтение «великих» произведений, предлагая изучение литературы не вглядыванием в детали, а рассматриванием с «дистанции» (distant reading), имея ввиду охват не одного или нескольких произведений, а сразу большого корпуса текстов. Только в таком случае, по мнению Моретти, удастся увидеть не конкретные черты стиля того или иного автора, а некие абстрактные закономерности, характеризующие сразу многие тексты.
Очевидно, что такая же потребность возникает и в целом при восприятии любой информации. Методы, позволяющие читать тексты «издалека», находятся в области компьютерного анализа текстов. Основной задачей направления извлечения информации является «автоматическое экстрагирование значимых для человека данных, как правило, из большого массива текстов, и преобразование их в структурированную форму, что облегчает их последующую обработку и анализ» [Большакова, Ефремова, 2017].
Соответствующим инструментарием является тематическое моделирование (topic modeling) [Hofmann, 1999; Blei, et.al. 2003; Воронцов, Потапенко, 2012, 2014] – одно из активно развивающихся с конца 90-х годов направлений анализа больших объемов текстовой информации. Тематическая модель определяет структуру коллекции текстовых документов путем выявления скрытых тем в документах, а также слов (или словосочетаний), характеризующих каждую из тем. Сжатое семантическое описание документа или слова представляет собой вероятностное распределение на множестве тем. Процесс нахождения этих распределений и называется тематическим моделированием [Daud et.al., 2010].
В настоящее время существуют различные подходы к построению тематических моделей [см. обзоры Милкова, 2019б; Daud et al., 2010], насчитывающие широкий спектр применения для решения различных задач [Boyd-Graber et al., 2017]: анализ дискурса в социальных сетях [Apishev et al., 2016] и моделирование семантических связей [Митрофанова и др., 2014], анализ новостных сообщений [Pashakhin, 2016], анализ научных публикаций [Griffiths, Steyvers, 2004], патентный анализ [Милкова, 2020], анализ биометрических данных [Liu et al., 2016] и др. Однако именно для поведенческих экономистов использование данного инструментария особенно актуально в целях тестирования альтернативного подхода управления вниманием, снижения негативных последствий дефицита внимания.
5. Выводы
Разрастающийся объем информации, развитие информационных технологий и склонность человека к когнитивным искажениям и эмоциональной оценке привели к глобальной смене принципов восприятия информации. Привлечение внимания и его последующая перепродажа в настоящее время является массовым бизнесом, что позволяет манипулировать общественным сознанием и формировать предпочтения. Так, автоматическая конформность заставляет считать «лучшей» альтернативу (информацию) с большим числом «лайков»; склонность к выбору опции по умолчанию – активно пользоваться готовыми ответами, предоставляемыми поисковыми системами; больший вклад эмоциональной системы – предпочитать информацию, имеющую эмоциональную окраску. Кроме того, познавательная система человека склонна искать подтверждения уже выдвинутым гипотезам, а не критически проверять их. «В целом человек сегодня не добывает знания, а получает их готовыми» [Почепцов, 2019].
Резюмируя, отметим, что современный подход представления информации подразумевает, с одной стороны, предложение «решений по умолчанию», рассчитывая на склонность человека предпочитать эти решения, с другой стороны, персонализированные предложения захватывают внимание быстро или даже автоматически, преследуя цель перепродажи внимания на деньги. Однако информация не просто привлекает внимание, она находится в динамическом интерактивном и интерсубъективном процессе, который формирует самость (целостность человека) [Doyle, Roda, 2019]. Очевидно, что выбор объекта внимания, а также качество и интенсивность внимания обуславливается не только мотивацией и личностными качествами, но и внешними факторами. Большая часть поведения внимания реактивна: наблюдаемая реакция в значительной степени обусловлена суммой предыдущих впечатлений и внешних обстоятельств. В стремительно разрастающейся цифровой среде место человека в ней трансформируется: роль внешних агентств усиливается и распределение внимания индивида теряет свою автономию [Doyle, Roda, 2019].
Таким образом, на первый план выходит разработка стратегии для эффективного управления вниманием, подразумевающая представление структуры или смысловой компрессии информации. Представление информации должно, с одной стороны, учитывать клиповый характер современного мышления, а с другой стороны – предоставлять дорожную карту исследуемого вопроса вместо готового ответа. Кроме того, альтернативный способ представления информации должен создавать конкуренцию текущей концепции «быстрого» поиска. В данном контексте инструментарием, подходящим для управления вниманием и способствующим познанию, является тематическое моделирование, включение которого в дискурс поведенческой экономики и экономики внимания является актуальной будущей задачей.
Как работает внимание в рекуррентных нейронных сетях кодер-декодер
Последнее обновление 7 августа 2019 г.
Attention — это механизм, который был разработан для повышения производительности RNN кодировщика-декодера при машинном переводе.
В этом руководстве вы откроете для себя механизм внимания для модели кодировщик-декодер.
После прохождения этого руководства вы будете знать:
- О модели кодировщика-декодера и механизме внимания для машинного перевода.
- Пошаговая инструкция по реализации механизма внимания.
- Приложения и расширения к механизму внимания.
Начните свой проект с моей новой книги «Глубокое обучение для обработки естественного языка», включая пошаговые руководства и файлы исходного кода Python для всех примеров.
Приступим.
- Обновление декабрь 2017 г. : исправлена небольшая опечатка в шаге 4, спасибо Синтии Фриман.
Обзор руководства
Это руководство разделено на 4 части; их:
- Кодер-декодер Модель
- Внимание Модель
- Рабочий пример внимания
- Расширения внимания
Кодер-декодер Модель
Модель кодировщика-декодера для рекуррентных нейронных сетей была представлена в двух статьях.
Оба разработали технику для решения проблемы последовательной природы машинного перевода, когда входные последовательности отличаются по длине от выходных последовательностей.
Илья Суцкевер и др. сделайте это в статье «Последовательность обучения с помощью нейронных сетей», используя LSTM.
Kyunghyun Cho, et al. сделайте это в статье «Изучение представлений фраз с использованием RNN Encoder – Decoder для статистического машинного перевода». Эта работа и некоторые из тех же авторов (Bahdanau, Cho и Bengio) разработали свою конкретную модель позже, чтобы разработать модель внимания. Поэтому мы кратко рассмотрим модель кодировщика-декодера, как описано в этой статье.
На высоком уровне модель состоит из двух подмоделей: кодировщика и декодера.
- Кодер : Кодер отвечает за пошаговое выполнение временных шагов ввода и кодирование всей последовательности в вектор фиксированной длины, называемый вектором контекста.
- Декодер : декодер отвечает за пошаговое выполнение временных шагов вывода при чтении из вектора контекста.
Модель рекуррентной нейронной сети кодировщика-декодера.
Взято из «Изучение представлений фраз с использованием RNN Encoder – Decoder для статистического машинного перевода»
мы предлагаем новую архитектуру нейронной сети, которая обучается кодировать последовательность переменной длины в векторное представление фиксированной длины и декодировать заданное векторное представление фиксированной длины обратно в последовательность переменной длины.
— Изучение представлений фраз с использованием RNN Encoder – Decoder для статистического машинного перевода, 2014.
Ключ к модели заключается в том, что вся модель, включая кодировщик и декодер, обучается от начала до конца, в отличие от обучения элементов по отдельности.
Модель описывается в общем, так что различные конкретные модели RNN могут использоваться в качестве кодировщика и декодера.
Вместо использования популярной RNN с долгосрочной кратковременной памятью (LSTM) авторы разрабатывают и используют свой собственный простой тип RNN, позже названный Gated Recurrent Unit или GRU.
Далее, в отличие от Sutskever, et al. В модели выход декодера из предыдущего временного шага подается как вход для декодирования следующего выходного временного шага. Вы можете видеть это на изображении выше, где выход y2 использует вектор контекста (C), скрытое состояние, переданное при декодировании y1, а также выход y1.
… и y (t), и h (i) также обусловлены y (t − 1) и суммой c входной последовательности.
— Изучение представлений фраз с использованием RNN Encoder – Decoder для статистического машинного перевода, 2014
Внимание Модель
Внимание представили Дмитрий Богданов и др. в их статье «Нейронный машинный перевод путем совместного обучения выравниванию и переводу», который является естественным продолжением их предыдущей работы над моделью кодировщик-декодер.
Внимание предлагается в качестве решения ограничения модели кодировщика-декодера, кодирующей входную последовательность, одним вектором фиксированной длины, из которого можно декодировать каждый выходной временной шаг. Считается, что эта проблема представляет собой большую проблему при декодировании длинных последовательностей.
Потенциальная проблема с этим подходом кодер-декодер заключается в том, что нейронная сеть должна иметь возможность сжимать всю необходимую информацию исходного предложения в вектор фиксированной длины. Это может затруднить работу нейронной сети с длинными предложениями, особенно с теми, которые длиннее, чем предложения в обучающем корпусе.
— Нейронный машинный перевод путем совместного обучения выравниванию и переводу, 2015.
Внимание предлагается как метод выравнивания и перевода.
Выравнивание — это проблема в машинном переводе, которая определяет, какие части входной последовательности имеют отношение к каждому слову в выходных данных, тогда как перевод — это процесс использования соответствующей информации для выбора подходящего выхода.
… мы вводим расширение модели кодировщика-декодера, которое учится согласовывать и транслировать совместно.Каждый раз, когда предложенная модель генерирует слово в переводе, она (программно) ищет набор позиций в исходном предложении, где сосредоточена наиболее релевантная информация. Затем модель предсказывает целевое слово на основе векторов контекста, связанных с этими исходными позициями и всеми ранее сгенерированными целевыми словами.
— Нейронный машинный перевод путем совместного обучения выравниванию и переводу, 2015.
Вместо кодирования входной последовательности в один фиксированный вектор контекста модель внимания разрабатывает вектор контекста, который фильтруется специально для каждого временного шага вывода.
Пример внимания
Взято из «Нейронного машинного перевода путем совместного обучения выравниванию и переводу», 2015 г.
Как и в случае с бумагой Encoder-Decoder, этот метод применяется к проблеме машинного перевода и использует блоки GRU, а не ячейки памяти LSTM. В этом случае используется двунаправленный ввод, при котором входные последовательности предоставляются как в прямом, так и в обратном направлении, которые затем объединяются перед передачей в декодер.
Вместо того, чтобы повторять уравнения для вычисления внимания, мы рассмотрим рабочий пример.
Нужна помощь с глубоким обучением текстовых данных?
Пройдите мой бесплатный 7-дневный ускоренный курс электронной почты (с кодом).
Нажмите, чтобы зарегистрироваться, а также получите бесплатную электронную версию курса в формате PDF.
Начните БЕСПЛАТНЫЙ ускоренный курс прямо сейчас
Рабочий пример внимания
В этом разделе мы конкретизируем внимание на небольшом рабочем примере. В частности, мы проведем расчеты с не векторизованными членами.
Это даст вам достаточно подробное понимание, чтобы вы могли добавить внимание к своей собственной реализации кодировщика-декодера.
Этот рабочий пример разделен на следующие 6 разделов:
- Проблема
- Кодировка
- Выравнивание
- Вес
- Вектор контекста
- Декодировать
1. Задача
Проблема — простая задача предсказания от последовательности к последовательности.
Есть три временных шага ввода:
Требуется модель для прогнозирования 1 временного шага:
В этом примере мы проигнорируем тип RNN, используемый в кодировщике и декодере, и проигнорируем использование двунаправленного входного уровня.Эти элементы не важны для понимания расчета внимания в декодере.
2. Кодировка
В модели кодер-декодер входные данные кодируются как один вектор фиксированной длины. Это выходные данные модели кодировщика для последнего временного шага.
Модель внимания требует доступа к выходным данным кодировщика для каждого временного шага входа. В документе они называются « аннотации » для каждого временного шага. В данном случае:
h2, h3, h4 = кодировщик (x1, x2, x3)
h2, h3, h4 = Кодировщик (x1, x2, x3) |
3.Мировоззрение
Декодер выводит по одному значению за раз, которое передается, возможно, большему количеству слоев перед окончательным выводом прогноза (y) для текущего временного шага вывода.
Модель согласования оценивает (e) насколько хорошо каждый закодированный вход (h) соответствует текущему выходному сигналу декодера (ов).
Для вычисления оценки требуется вывод декодера из предыдущего временного шага вывода, например с (т-1). При оценке самого первого вывода для декодера это будет 0.
Подсчет очков осуществляется с помощью функции a (). Мы можем оценить каждую аннотацию (h) для первого временного шага вывода следующим образом:
е11 = а (0, h2) е12 = а (0, h3) е13 = а (0, h4)
e11 = a (0, h2) e12 = a (0, h3) e13 = a (0, h4) |
Мы используем два нижних индекса для этих оценок, например e11, где первая «1» представляет временной шаг вывода, а вторая «1» представляет временной шаг ввода.
Мы можем представить, что если бы у нас была проблема от последовательности к последовательности с двумя временными шагами вывода, то позже мы могли бы оценить аннотации для второго временного шага следующим образом (при условии, что мы уже вычислили наше s1):
е21 = а (s1, h2) е22 = а (s1, h3) е23 = а (s1, h4)
e21 = a (s1, h2) e22 = a (s1, h3) e23 = a (s1, h4) |
Функция a () в статье называется моделью выравнивания и реализована как нейронная сеть с прямой связью.
Это традиционная однослойная сеть, в которой каждый вход (s (t-1) и h2, h3 и h4) взвешивается, используется передаточная функция гиперболического тангенса (tanh), а выход также взвешивается.
4. Взвешивание
Затем оценки выравнивания нормализуются с помощью функции softmax.
Нормализация оценок позволяет рассматривать их как вероятности, указывая на вероятность того, что каждый закодированный временной шаг ввода (аннотация) будет соответствовать текущему временному шагу вывода.
Эти нормализованные оценки называются весами аннотаций.
Например, мы можем рассчитать веса аннотаций softmax (a) с учетом вычисленных оценок выравнивания (e) следующим образом:
a11 = ехр (e11) / (ехр (e11) + ехр (e12) + ехр (e13)) a12 = ехр (e12) / (ехр (e11) + ехр (e12) + ехр (e13)) а13 = ехр (е13) / (ехр (е11) + ехр (е12) + ехр (е13))
a11 = exp (e11) / (exp (e11) + exp (e12) + exp (e13)) a12 = exp (e12) / (exp (e11) + exp (e12) + exp (e13)) a13 = ехр (e13) / (ехр (e11) + ехр (e12) + ехр (e13)) |
Если бы у нас было два временных шага вывода, веса аннотаций для второго временного шага вывода были бы вычислены следующим образом:
a21 = ехр (e21) / (ехр (e21) + ехр (e22) + ехр (e23)) a22 = ехр (e22) / (ехр (e21) + ехр (e22) + ехр (e23)) a23 = ехр (e23) / (ехр (e21) + ехр (e22) + ехр (e23))
a21 = exp (e21) / (exp (e21) + exp (e22) + exp (e23)) a22 = exp (e22) / (exp (e21) + exp (e22) + exp (e23)) a23 = ехр (e23) / (ехр (e21) + ехр (e22) + ехр (e23)) |
5.Вектор контекста
Затем каждая аннотация (h) умножается на веса аннотации (a), чтобы создать новый обслуживаемый вектор контекста, из которого можно декодировать текущий временной шаг вывода.
У нас есть только один временной шаг вывода для простоты, поэтому мы можем вычислить одноэлементный вектор контекста следующим образом (с скобками для удобства чтения):
c1 = (a11 * h2) + (a12 * h3) + (a13 * h4)
c1 = (a11 * h2) + (a12 * h3) + (a13 * h4) |
Контекстный вектор — это взвешенная сумма аннотаций и нормализованных оценок выравнивания.
Если бы у нас было два временных шага вывода, вектор контекста состоял бы из двух элементов [c1, c2], рассчитанных следующим образом:
c1 = a11 * h2 + a12 * h3 + a13 * h4 c2 = a21 * h2 + a22 * h3 + a23 * h4
c1 = a11 * h2 + a12 * h3 + a13 * h4 c2 = a21 * h2 + a22 * h3 + a23 * h4 |
6. Декодировать
Затем выполняется декодирование в соответствии с моделью кодировщика-декодера, хотя в этом случае используется обслуживаемый вектор контекста для текущего временного шага.
Выход декодера (ов) упоминается в документе как скрытое состояние.
Это может быть передано в дополнительные уровни перед окончательным выходом из модели в качестве прогноза (y1) для временного шага.
Расширения вниманию
В этом разделе рассматриваются некоторые дополнительные приложения Bahdanau, et al. механизм внимания.
Жесткое и мягкое внимание
В статье 2015 года «Покажи, посети и расскажи: создание подписей к нейронным изображениям с визуальным вниманием» Кельвин Сю и др.обратил внимание на данные изображения, используя сверточные нейронные сети в качестве экстракторов признаков для данных изображения на проблеме подписания фотографий.
Они развивают два механизма внимания: один они называют « мягкое внимание », которое напоминает внимание, как описано выше, с взвешенным вектором контекста, и второй « жесткое внимание », где четкие решения принимаются в отношении элементов в векторе контекста. за каждое слово.
Они также предлагают двойное внимание, когда внимание сосредоточено на определенных частях изображения.
Удаление предыдущего скрытого состояния
Было несколько приложений механизма, в которых подход был упрощен, так что скрытое состояние с последнего временного шага вывода (s (t-1)) исключалось из оценки аннотаций (шаг 3 выше).
Два примера:
Это приводит к тому, что модель не получает представление о ранее декодированном выходе, которое предназначено для помощи в выравнивании.
Это отмечено в уравнениях, перечисленных в документах, и неясно, была ли миссия преднамеренным изменением модели или просто упущением в уравнениях.Ни в одной из статей не было замечено обсуждения отказа от этого термина.
Изучение предыдущего скрытого состояния
Минь-Тханг Луонг и др. в своей статье 2015 года «Эффективные подходы к нейронному машинному переводу на основе внимания» явно реструктурировали использование предыдущего скрытого состояния декодера при оценке аннотаций. Также см. Презентацию документа и соответствующий код Matlab.
Они разработали основу для сравнения различных способов оценки аннотаций. Их структура вызывает и явно исключает предыдущее скрытое состояние при оценке аннотаций.
Вместо этого они берут предыдущий вектор контекста внимания и передают его в качестве входных данных декодеру. Цель состоит в том, чтобы позволить декодеру знать о прошлых решениях о выравнивании.
… мы предлагаем подход подачи ввода, в котором векторы внимания ht объединяются с вводами на следующих временных шагах […]. Такие связи имеют двоякий эффект: (а) мы надеемся сделать модель полностью осведомленной о предыдущих вариантах выравнивания и (б) мы создаем очень глубокую сеть, охватывающую как по горизонтали, так и по вертикали
— Эффективные подходы к нейронному машинному переводу на основе внимания, 2015.
Ниже приведено изображение этого подхода, взятое из статьи. Обратите внимание на пунктирные линии, явно показывающие использование декодеров, обслуживаемых выходом скрытого состояния (ht), обеспечивающим вход для декодера на следующем временном шаге.
Передача скрытого состояния в качестве входных данных для декодера
Взято из «Эффективных подходов к нейронному машинному переводу на основе внимания», 2015 г.
Они также развивают внимание « глобальное, » и « локальное, », где локальное внимание является модификацией подхода, который изучает окно фиксированного размера, которое накладывается на вектор внимания для каждого временного шага вывода.Это рассматривается как более простой подход к « упорному вниманию, », представленному Сюй и др.
Недостаток глобального внимания состоит в том, что оно должно уделять внимание всем словам на стороне источника для каждого целевого слова, что является дорогостоящим и потенциально может сделать непрактичным перевод более длинных последовательностей, например абзацев или документов. Чтобы устранить этот недостаток, мы предлагаем локальный механизм внимания, который выбирает фокусировку только на небольшом подмножестве исходных позиций для каждого целевого слова.
— Эффективные подходы к нейронному машинному переводу на основе внимания, 2015 г.
Анализ в статье глобального и локального внимания с различными функциями оценки аннотаций предполагает, что локальное внимание обеспечивает лучшие результаты в задаче перевода.
Дополнительная литература
Этот раздел предоставляет больше ресурсов по теме, если вы хотите углубиться.
Документы по кодировщикам-декодерам
Вниманию документов
Подробнее о внимании
Сводка
В этом руководстве вы открыли для себя механизм внимания для модели кодировщик-декодер.
В частности, вы выучили:
- О модели кодировщика-декодера и механизме внимания для машинного перевода.
- Пошаговая инструкция по реализации механизма внимания.
- Приложения и расширения к механизму внимания.
Есть вопросы?
Задайте свои вопросы в комментариях ниже, и я постараюсь ответить.
Разрабатывайте модели глубокого обучения для текстовых данных уже сегодня!
Создавайте собственные текстовые модели за считанные минуты
…с всего несколькими строками кода Python
Узнайте, как в моей новой электронной книге:
Глубокое обучение для обработки естественного языка
Он предоставляет руководств для самостоятельного изучения по таким темам, как:
Пакет слов, встраивание слов, языковые модели, создание подписей, перевод текста и многое другое …
Наконец-то привнесите глубокое обучение в свои проекты обработки естественного языка
Пропустить академики. Только результаты.
Посмотрите, что внутриКраткий обзор механизма внимания | синхронизировано | SyncedReview
Внимание — это просто вектор, часто выходы плотного слоя с использованием функции softmax.
Перед механизмом «Внимание», перевод основан на чтении всего предложения и сжатии всей информации в вектор фиксированной длины, как вы можете себе представить, предложение из сотен слов, представленных несколькими словами, обязательно приведет к потере информации, неадекватному переводу и т. Д.
Однако внимание частично решает эту проблему. Это позволяет машинному переводчику просматривать всю информацию, содержащуюся в исходном предложении, а затем генерировать правильное слово в соответствии с текущим словом, с которым оно работает, и контекстом.Он может даже позволить переводчику увеличивать или уменьшать масштаб (фокусироваться на локальных или глобальных функциях).
Внимание не таинственное или сложное. Это просто интерфейс, составленный с помощью параметров и тонкой математики. Вы можете подключить его к любому месту, где сочтете подходящим, и потенциально результат может быть улучшен.
Ядром вероятностной языковой модели является присвоение вероятности предложению с помощью предположения Маркова. Из-за природы предложений, которые состоят из разного количества слов, RNN естественным образом вводится для моделирования условной вероятности среди слов.
Vanilla RNN (классический) часто попадает в ловушку при моделировании:
- Структурная дилемма: в реальном мире длина выходов и входов может быть совершенно разной, в то время как Vanilla RNN может справиться только с проблемой фиксированной длины, что трудно решить. выравнивание. Рассмотрим примеры перевода на EN-FR: «он не любит яблоки» → «Il n’aime pas les pommes».
- Математический характер: он страдает от исчезновения / взрыва градиента, что означает, что его трудно тренировать, когда предложения достаточно длинные (возможно, не более 4 слов).
Трансляция часто требует произвольной длины ввода и длины вывода, чтобы справиться с указанными выше недостатками, принята модель кодировщика-декодера и базовая ячейка RNN заменена на ячейку GRU или LSTM, активация гиперболического тангенса заменена на ReLU. Здесь мы используем ячейку ГРУ.
Встраиваемый слой преобразует дискретные слова в плотные векторы для повышения эффективности вычислений. Затем встроенные векторы слов последовательно подаются в кодировщик, также известный как ячейки ГРУ. Что произошло при кодировании? Информация течет слева направо, и каждый вектор слова изучается не только в соответствии с текущим вводом, но и со всеми предыдущими словами.Когда предложение полностью прочитано, кодировщик генерирует вывод и скрытое состояние на временном шаге 4 для дальнейшей обработки. Для части кодирования декодер (а также ГРУ) захватывает скрытое состояние из кодировщика, обученного принудительным действием учителя (режим, в котором вывод предыдущей ячейки является текущим вводом), а затем последовательно генерирует слова перевода.
Это кажется удивительным, поскольку эту модель можно применить к последовательности N-to-M, но все же остается один нерешенный главный недостаток: действительно ли одного скрытого состояния достаточно?
Да, внимание.
Подобно базовой архитектуре кодер-декодер, этот причудливый механизм вставляет вектор контекста в промежуток между кодером и декодером. Согласно схеме выше, синий представляет кодер, а красный — декодер; и мы могли видеть, что вектор контекста принимает выходные данные всех ячеек в качестве входных данных для вычисления распределения вероятностей слов исходного языка для каждого отдельного слова, которое декодер хочет сгенерировать. Используя этот механизм, декодер может захватывать некоторую глобальную информацию, а не делать выводы только на основе одного скрытого состояния.
А построить вектор контекста довольно просто. Для фиксированного целевого слова сначала мы перебираем все состояния кодировщиков, чтобы сравнить целевое и исходное состояния, чтобы сгенерировать оценки для каждого состояния в кодировщиках. Затем мы могли бы использовать softmax для нормализации всех оценок, что генерирует распределение вероятностей, обусловленное целевыми состояниями. Наконец, введены веса, чтобы упростить обучение вектора контекста. Вот и все. Математика показана ниже:
Чтобы понять кажущуюся сложной математику, нам нужно помнить о трех ключевых моментах:
- Во время декодирования векторы контекста вычисляются для каждого выходного слова.Таким образом, у нас будет двумерная матрица, размер которой равен количеству целевых слов, умноженному на количество исходных слов. Уравнение (1) демонстрирует, как вычислить одно значение для одного целевого слова и набора исходного слова.
- Как только вектор контекста вычислен, вектор внимания может быть вычислен с помощью вектора контекста, целевого слова и функции внимания
f. - Нам нужен механизм внимания, чтобы его можно было тренировать. Согласно уравнению (4), оба стиля предлагают тренируемые веса (W у Луонга, W1 и W2 у Bahdanau).Таким образом, разные стили могут привести к разной производительности.
Мы надеемся, что вы понимаете причину, по которой внимание является одной из самых горячих тем сегодня, и, что наиболее важно, основная математика, лежащая в основе внимания. Приветствуется реализация вашего собственного уровня внимания. В передовых исследованиях существует множество вариантов, и они в основном различаются выбором функции оценки и функции внимания или мягкого внимания и жесткого внимания (будь то дифференцируемое). Но основные концепции все те же.Если интересно, вы можете проверить документы ниже.
[1] Vinyals, Oriol, et al. Покажи и расскажи: генератор титров нейронных изображений. arXiv: 1411.4555 (2014).
[2] Богданау, Дмитрий, Кёнхён Чо и Йошуа Бенжио. Нейронный машинный перевод путем совместного обучения выравниванию и переводу. arXiv: 1409.0473 (2014).
[3] Чо, Кёнхён, Аарон Курвиль и Йошуа Бенжио. Описание мультимедийного контента с использованием сетей кодирования-декодирования на основе внимания. arXiv: 1507.01053 (2015)
[4] Xu, Kelvin, et al.Покажи, посети и расскажи: создание подписи к нейронному изображению с визуальным вниманием. arXiv: 1502.03044 (2015).
[5] Сухэ-Батор, Сайнбаяр, Джейсон Уэстон и Роб Фергус. Сквозные сети памяти. Достижения в области систем обработки нейронной информации . (2015).
[6] Жулен, Арман и Томаш Миколов. Вывод алгоритмических паттернов с помощью рекуррентных сетей, дополненных стеком. arXiv: 1503.01007 (2015).
[7] Герман, Карл Мориц и др. Обучающие машины читать и понимать. Достижения в области систем обработки нейронной информации . (2015).
[8] Раффель, Колин и Дэниел П. У. Эллис. Сети с прямой связью с вниманием могут решить некоторые проблемы с долговременной памятью. arXiv: 1512.08756 (2015).
[9] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., & Gomez, A. et al. . Внимание . arXiv: 1706.03762 (2017).
Внимание в глубоких сетях с Keras | Автор: Тусхан Ганегедара
Эта история знакомит вас с репозиторием Github, который содержит атомарный актуальный уровень внимания, реализованный с использованием внутренних операций Keras.Доступен по адресу: Внимание_keras .
С появлением TensorFlow 2.0 трудно игнорировать заметное внимание (без каламбура!), Уделяемое Керасу. Больше внимания было уделено поддержке Keras для реализации глубоких сетей. Keras в TensorFlow 2.0 будет поставляться с тремя мощными API для реализации глубоких сетей.
- Последовательный API — это простейший API, в котором вы сначала вызываете
model = Sequential ()и продолжаете добавлять слои, например.г.model.add (Плотный (...)). - Функциональный API — Расширенный API, в котором вы можете создавать собственные модели с произвольными входами / выходами. Определение модели нужно делать осторожно, так как многое предстоит сделать со стороны пользователя. Модель может быть определена с помощью
model = Model (input = [...], output = [...]). - Subclassing API — еще один продвинутый API, в котором вы определяете модель как класс Python. Здесь вы определяете прямой проход модели в классе, и Keras автоматически вычисляет обратный проход.Затем эту модель можно использовать как обычно, как если бы вы использовали любую модель Keras.
Для получения дополнительной информации получите информацию из первых рук от команды TensorFlow. Однако помните, что, выбирая расширенные API, они дают больше «пространства для маневра» для реализации сложных моделей, они также увеличивают вероятность грубых ошибок и различных «кроличьих нор».
Недавно я искал реализацию или библиотеку слоя внимания на основе Keras для проекта, над которым я работал. Я столкнулся с несколькими репозиториями, которые уже привлекли внимание.Однако мои усилия были напрасны, я пытался заставить их работать с более поздними версиями TF. По нескольким причинам:
- В любом случае реализованному вниманию не хватало модульности (внимание было реализовано для полного декодера вместо отдельных развернутых шагов декодера
- Использование устаревших функций из более ранних версий TF
Это большие усилия, и я уважаю все эти участники.Но я решил вмешаться и реализовать AttentionLayer , который применим на более атомарном уровне и обновлен до новой версии TF.Этот репозиторий доступен здесь.
Примечание : Это статья из серии Light on Math Machine Learning A-Z . Вы можете найти предыдущие сообщения в блоге, связанные с письмом ниже.
AB C D * EFGHIJ K L * M N OPQRSTUV W XYZ
Сначала вы ознакомитесь с этой статьей Grok, что такое модель от последовательности к последовательности, а затем почему важно внимание к последовательным моделям? Далее вы познакомитесь с мельчайшими деталями механизма внимания.Этот пост в блоге закончится объяснением того, как использовать слой внимания.
От последовательности к последовательности — это мощное семейство моделей глубокого обучения, предназначенных для решения самых сложных проблем в сфере машинного обучения. Например,
- Машинный перевод
- Чат-боты
- Обобщение текста
С которыми связаны очень уникальные и нишевые задачи. Например, машинный перевод должен иметь дело с разными топологиями порядка слов (то есть порядком субъект-глагол-объект).Таким образом, они являются незаменимым оружием в борьбе со сложными проблемами НЛП.
Давайте посмотрим, как модель от последовательности к последовательности может быть использована для задачи машинного перевода с английского на французский.
Модель от последовательности к последовательности состоит из двух компонентов: кодера и декодера . Кодер кодирует исходное предложение в краткий вектор (называемый вектором контекста ), где декодер принимает вектор контекста в качестве входных данных и вычисляет перевод, используя закодированное представление.
Модель от последовательности к последовательностиВ этом подходе есть огромное узкое место. На вектор контекста была возложена ответственность за кодирование всей информации в данном исходном предложении в вектор из нескольких сотен элементов. Теперь, чтобы дать немного контекста, этот вектор необходимо сохранить:
- Информация о субъекте, объекте и глаголе
- Взаимодействие между этими сущностями
Это может быть довольно сложно, особенно для длинных предложений. Поэтому требовалось лучшее решение, чтобы раздвинуть границы.
Что, если бы вместо того, чтобы полагаться только на вектор контекста, декодер имел доступ к всем прошлым состояниям кодировщика ? Именно это и делает внимание. На каждом этапе декодирования декодер проверяет любое конкретное состояние кодера. Здесь мы будем обсуждать внимание Бахданова. На следующем рисунке изображена внутренняя работа внимания.
От последовательности к последовательности с вниманиемИтак, как показано на изображении, вектор контекста стал взвешенной суммой всех прошлых состояний кодера.
Это может быть довольно обременительным для работы с некоторыми уровнями внимания по причинам, которые я объяснил ранее. Внимание_keras использует более модульный подход, где он реализует внимание на более атомарном уровне (то есть для каждого шага декодера данного декодера RNN / LSTM / GRU).
Вы можете использовать его как любой другой слой. Например,
attn_layer = AttentionLayer (name = 'Внимание_layer') ([encoder_out, decoder_out])
Я также предоставил игрушечный пример нейронного машинного переводчика (NMT), показывающий, как использовать уровень внимания в NMT (nmt / тренироваться.ру). Но позвольте мне рассказать вам о некоторых деталях.
Здесь я кратко рассмотрю шаги по реализации NMT с вниманием.
Сначала определите входы кодера и декодера (исходные / целевые слова). Оба имеют форму (размер партии, временные шаги, размер словаря).
encoder_inputs = Вход (batch_shape = (batch_size, en_timesteps, en_vsize), name = 'encoder_inputs')
decoder_inputs = Вход (batch_shape = (batch_size, fr_timesteps - 1, fr_vsize) 90inputs, имя = '' (обратите внимание на то, чтоreturn_sequences = True)encoder_gru = GRU (hidden_size, return_sequences = True, return_state = True, name = 'encoder_gru')
encoder_out, encoder_state = encoder_gru (encoder_inputs)Определить возвращаемый декодер = True )
decoder_gru = GRU (hidden_size, return_sequences = True, return_state = True, name = 'decoder_gru')
decoder_out, decoder_state = decoder_gru (decoder_inputs, initial_state = encoder_state)Определение уровня внимания.Входами в уровень внимания являются
encoder_out(последовательность выходов кодера) иdecoder_out(последовательность выходов декодера)attn_layer = AttentionLayer (name = 'Внимание_layer')
attn_out, attn_states = attn_layer ([encoder_out], decoderОбъедините
attn_outиdecoder_outв качестве входных данных для слоя softmax.decoder_concat_input = Concatenate (axis = -1, name = 'concat_layer') ([decoder_out, attn_out])Определите
TimeDistributedSoftmax слой и предоставьтеdecoder_concat_inputв качестве входных данных.плотный = плотный (fr_vsize, активация = 'softmax', name = 'softmax_layer')
плотный_время = TimeDistributed (плотный, name = 'time_distributed_layer')
decoder_pred = плотное_время (decoder_concat_input)Определить полную модель.
full_model = Модель (входы = [encoder_inputs, decoder_inputs], выходы = decoder_pred)
full_model.compile (optimizer = 'adam', loss ='ategorical_crossentropy ')Вот и все!
Это не только обеспечивает внимание, но и дает вам возможность довольно легко заглянуть под капот механизма внимания.Это возможно, потому что этот уровень возвращает оба:
- вектор контекста внимания (используемый как дополнительный вход для уровня Softmax декодера)
- значения энергии внимания (выход Softmax механизма внимания)
для каждого шага декодирования. Таким образом, визуализируя значения энергии внимания, вы получаете полный доступ к тому, что делает внимание во время тренировки / вывода. Ниже я расскажу о некоторых деталях этого процесса.
Вывод из NMT громоздок! Поскольку вам необходимо,
- Получить выходные данные кодировщика
- Определите декодер, который выполняет один шаг декодера (потому что нам необходимо предоставить прогноз этого шага в качестве входных данных для следующего шага)
- Используйте выходные данные кодировщика как исходное состояние для декодера
- Выполнять декодирование до тех пор, пока мы не получим недопустимое слово /
в качестве вывода / или фиксированное количество шагов
Я не буду говорить об определении модели.За подробностями обращайтесь к examples / nmt / train.py . Давайте поговорим о том, как использовать это для увеличения внимания.
для i в диапазоне (20):dec_out, внимание, dec_state = decoder_model.predict ([enc_outs, dec_state, test_fr_onehot_seq])
dec_ind = np.argmax (dec_out, axis = -1) [0, 0]...
Внимание_weights.append ((dec_ind, Внимание))
Итак, как вы можете видеть, мы собираем веса внимания для каждого шага декодирования.
Затем вам просто нужно передать этот список весов внимания на plot_attention_weights (nmt / train.py), чтобы привлечь внимание с помощью других аргументов. Результат после построения может быть таким, как показано ниже.
В этой статье я познакомил вас с реализацией AttentionLayer. Внимание очень важно для последовательных моделей и даже для других типов моделей. Однако текущие реализации либо устарели, либо не очень модульны. Поэтому я немного покопался и реализовал слой Attention с помощью бэкэнд-операций Keras. Надеюсь, у вас получится отлично справиться с этим слоем.Если у вас есть какие-либо вопросы / вы обнаружите какие-либо ошибки, не стесняйтесь отправлять вопрос на Github.
Я был бы очень благодарен, если у вас есть участники, исправляющие любые ошибки / внедряющие новые механизмы внимания. Так что взносы приветствуются!
Оцените мою работу по данной теме.
[1] (Книга) TensorFlow 2 в действии - Manning
[2] (Видеокурс) Машинный перевод в Python - DataCamp
[3] (Книга) Обработка естественного языка в TensorFlow 1 - Packt
Внимание и память в глубоком обучении и НЛП - WildML
Недавняя тенденция в глубоком обучении - это механизмы внимания.В интервью Илья Суцкевер, ныне директор по исследованиям OpenAI, упомянул, что механизмы внимания - это одно из самых захватывающих достижений, и они никуда не денутся. Звучит захватывающе. Но что такое механизмы внимания?
Механизмы внимания в нейронных сетях (очень) слабо основаны на механизме визуального внимания, обнаруженном у людей. Зрительное внимание человека хорошо изучено, и хотя существуют разные модели, все они по сути сводятся к способности сосредоточиться на определенной области изображения с «высоким разрешением», воспринимая окружающее изображение в «низком разрешении», а затем корректировка фокуса с течением времени.
Внимание в нейронных сетях имеет долгую историю, особенно в области распознавания изображений. Примеры включают в себя обучение сочетанию фовеальных проблесков с машиной Больцмана третьего порядка или обучение с помощью глубокой архитектуры для отслеживания изображений. Но только недавно механизмы внимания стали использоваться в повторяющихся архитектурах нейронных сетей, которые обычно используются в НЛП (и все чаще и в зрении). Это то, на чем мы сосредоточимся в этом посте.
Какую проблему решает внимание?
Чтобы понять, что может сделать для нас внимание, давайте рассмотрим в качестве примера нейронный машинный перевод (NMT).Традиционные системы машинного перевода обычно основываются на сложной инженерии функций, основанной на статистических свойствах текста. Короче говоря, эти системы сложны, и на их создание уходит много инженерных усилий. Системы нейронного машинного перевода работают немного иначе. В NMT мы сопоставляем значение предложения с векторным представлением фиксированной длины, а затем генерируем перевод на основе этого вектора. Не полагаясь на такие вещи, как подсчет n-граммов и вместо этого пытаясь уловить более высокий уровень смысла текста, системы NMT обобщают новые предложения лучше, чем многие другие подходы.Возможно, что еще более важно, системы NTM намного проще создавать и обучать, и они не требуют ручной разработки функций. Фактически, простая реализация в Tensorflow - это не более нескольких сотен строк кода.
Большинство систем NMT работают, кодируя исходное предложение (например, немецкое предложение) в вектор с помощью рекуррентной нейронной сети, а затем декодируя английское предложение на основе этого вектора, также используя RNN.
На рисунке выше слова «Echt», «Dicke» и «Kiste» загружаются в кодировщик, и после специального сигнала (не показан) декодер начинает формировать переведенное предложение.Декодер продолжает генерировать слова до тех пор, пока не будет создан специальный маркер конца предложения. Здесь векторы представляют внутреннее состояние кодировщика.
Если вы присмотритесь, вы увидите, что декодер должен генерировать перевод исключительно на основе последнего скрытого состояния (см. Выше) от кодировщика. Этот вектор должен кодировать все, что нам нужно знать об исходном предложении. Он должен полностью улавливать его смысл. Говоря более техническим языком, этот вектор представляет собой предложение , встраивающее .Фактически, если вы построите вложения различных предложений в низкоразмерном пространстве, используя PCA или t-SNE для уменьшения размерности, вы можете увидеть, что семантически похожие фразы оказываются близко друг к другу. Это просто потрясающе.
Тем не менее, кажется несколько неразумным предполагать, что мы можем закодировать всю информацию о потенциально очень длинном предложении в один вектор, а затем заставить декодер произвести хороший перевод, основанный только на этом. Допустим, ваше исходное предложение состоит из 50 слов.Первое слово английского перевода, вероятно, сильно коррелирует с первым словом исходного предложения. Но это означает, что декодер должен учитывать информацию, полученную 50 шагами назад, и эту информацию нужно каким-то образом закодировать в векторе. Известно, что рекуррентные нейронные сети имеют проблемы с такими зависимостями на больших расстояниях. Теоретически такие архитектуры, как LSTM, должны уметь справляться с этим, но на практике долгосрочные зависимости все еще проблематичны. Например, исследователи обнаружили, что реверсирование исходной последовательности (подача ее обратно в кодировщик) дает значительно лучшие результаты, поскольку сокращает путь от декодера до соответствующих частей кодировщика.Точно так же двукратная подача входной последовательности также помогает сети лучше запоминать вещи.
Я считаю подход перестановки предложения «взломом». Это помогает улучшить работу на практике, но это не принципиальное решение. Большинство тестов перевода выполняется на таких языках, как французский и немецкий, которые очень похожи на английский (даже порядок слов в китайском очень похож на английский). Но есть языки (например, японский), в которых последнее слово предложения может быть очень важным для первого слова в английском переводе.В этом случае реверсирование входа только усугубит ситуацию. Итак, какая альтернатива? Механизмы внимания.
С механизмом внимания мы больше не пытаемся кодировать полное исходное предложение в вектор фиксированной длины. Скорее, мы позволяем декодеру «следить» за различными частями исходного предложения на каждом этапе генерации вывода. Важно отметить, что мы позволили модели узнать , на что обращать внимание, на основе введенного предложения и того, что она уже произвела. Таким образом, в языках, которые довольно хорошо согласованы (например, английский и немецкий), декодер, вероятно, решит рассматривать вещи последовательно.Внимание к первому слову при создании первого английского слова и так далее. Это то, что было сделано в нейронном машинном переводе путем совместного обучения выравниванию и переводу, и оно выглядит следующим образом:
Здесь ‘s - это наши переведенные слова, полученные декодером, а‘ s - слова нашего исходного предложения. На приведенном выше рисунке используется двунаправленная рекуррентная сеть, но это не важно, и вы можете просто игнорировать обратное направление. Важной частью является то, что каждое выходное слово декодера теперь зависит от взвешенной комбинации всех входных состояний , а не только от последнего состояния.‘S - это веса, которые определяют, какую часть каждого состояния ввода следует учитывать для каждого вывода. Таким образом, если это большое число, это будет означать, что декодер уделяет много внимания второму состоянию в исходном предложении, производя третье слово целевого предложения. Обычно они нормализуются до суммы 1 (так что они являются распределением по входным состояниям).
Большое преимущество внимания состоит в том, что оно дает нам возможность интерпретировать и визуализировать то, что делает модель.Например, визуализируя матрицу весов внимания при переводе предложения, мы можем понять, как переводится модель:
Здесь мы видим, что при переводе с французского на английский, сеть последовательно обслуживает каждое входное состояние, но иногда при создании выходных данных она обслуживает сразу два слова, как, например, в переводе «Сирия» на «Сирия».
Стоимость внимания
Если мы посмотрим более внимательно на уравнение внимания, мы увидим, что за внимание приходится платить.Нам нужно рассчитать значение внимания для каждой комбинации входного и выходного слова. Если у вас есть входная последовательность из 50 слов и вы сгенерируете выходную последовательность из 50 слов, это будет 2500 значений внимания. Это не так уж и плохо, но если вы выполняете вычисления на уровне персонажа и имеете дело с последовательностями, состоящими из сотен токенов, указанные выше механизмы внимания могут стать чрезмерно дорогими.
На самом деле, это довольно нелогично. Человеческое внимание - это то, что должно сберечь вычислительных ресурсов.Сосредоточившись на одном, мы можем пренебречь многими другими вещами. Но это не совсем то, что мы делаем в приведенной выше модели. По сути, мы подробно изучаем все, прежде чем решить, на чем сосредоточить внимание. Интуитивно это эквивалентно выводу переведенного слова и последующему просмотру всех вашей внутренней памяти текста, чтобы решить, какое слово создать следующим. Это кажется пустой тратой, и это совсем не то, что делают люди. На самом деле, это больше похоже на доступ к памяти, а не на внимание, что, на мой взгляд, неправильно (подробнее об этом ниже).Тем не менее, это не помешало механизмам внимания стать довольно популярными и хорошо справляться со многими задачами.
Альтернативный подход к вниманию - использование обучения с подкреплением для прогнозирования приблизительного местоположения, на котором нужно сосредоточиться. Это больше похоже на человеческое внимание, и именно это сделано в Рекуррентных моделях визуального внимания.
Внимание за пределами машинного перевода
До сих пор мы уделяли внимание машинному переводу. Но тот же самый механизм внимания, описанный выше, может быть применен к любой повторяющейся модели.Итак, давайте рассмотрим еще несколько примеров.
В «Показать, посетить и рассказать» авторы применяют механизмы внимания к проблеме создания описаний изображений. Они используют сверточную нейронную сеть для «кодирования» изображения и рекуррентную нейронную сеть с механизмами внимания для генерации описания. Визуализируя веса внимания (как в примере с переводом), мы интерпретируем то, на что смотрит модель, генерируя слово:
В разделе «Грамматика как иностранный язык» авторы используют рекуррентную нейронную сеть с механизмом внимания для создания деревьев синтаксического анализа предложений.Визуализированная матрица внимания дает представление о том, как сеть генерирует эти деревья:
В книге «Обучающие машины для чтения и понимания» авторы используют RNN для чтения текста, чтения (синтетически сгенерированного) вопроса и затем получения ответа. Визуализируя матрицу внимания, мы можем увидеть, куда сеть «смотрит», пытаясь найти ответ на вопрос:
Внимание = (Нечеткая) память?
Основная проблема, которую решает механизм внимания, заключается в том, что он позволяет сети возвращаться к входной последовательности, вместо того, чтобы заставлять ее кодировать всю информацию в один вектор фиксированной длины.Как я уже упоминал выше, я считаю, что термин "внимание" употребляется неправильно. Иначе говоря, механизм внимания просто предоставляет сети доступ к ее внутренней памяти, которая является скрытым состоянием кодировщика. В этой интерпретации, вместо того, чтобы выбирать, чем «заниматься», сеть выбирает, что извлечь из памяти. В отличие от типичной памяти, механизм доступа к памяти здесь мягкий, что означает, что сеть извлекает взвешенную комбинацию всех ячеек памяти, а не значение из одной дискретной ячейки.Преимущество мягкого доступа к памяти состоит в том, что мы можем легко обучать сеть от начала до конца, используя обратное распространение (хотя были и нечеткие подходы, когда градиенты вычислялись с использованием методов выборки вместо обратного распространения).
Сами механизмы памяти имеют гораздо более долгую историю. Скрытое состояние стандартной рекуррентной нейронной сети само по себе является типом внутренней памяти. RNN страдают от проблемы исчезающего градиента, которая не позволяет им изучать дальнодействующие зависимости.LSTM улучшили это за счет использования механизма стробирования, который допускает явное удаление и обновление памяти.
Тенденция к более сложным структурам памяти в настоящее время продолжается. Сквозные сети памяти позволяют сети считывать одну и ту же входную последовательность несколько раз перед тем, как сделать вывод, обновляя содержимое памяти на каждом этапе. Например, ответ на вопрос, сделав несколько логических шагов над входной историей. Однако, когда веса параметров сети связаны определенным образом, механизм памяти в сквозных сетях памяти идентичен механизму внимания, представленному здесь, только он делает несколько переходов по памяти (потому что он пытается интегрировать информацию из нескольких предложения).
Нейронные машины Тьюрингаиспользуют аналогичную форму механизма памяти, но с более сложным типом адресации, использующим как адресацию на основе содержимого (как здесь), так и адресацию на основе местоположения, что позволяет сети изучать шаблон адресации для выполнения простых компьютерных программ, таких как алгоритмы сортировки.
Вероятно, что в будущем мы увидим более четкое различие между механизмами памяти и внимания, возможно, в духе нейронных машин Тьюринга с обучением с подкреплением, которые пытаются изучить шаблоны доступа для работы с внешними интерфейсами.
google / neural-tangents: быстрые и простые бесконечные нейронные сети на Python
ICLR 2020 Видео | Бумага | Быстрый старт | Руководство по установке | Справочные документы | Примечания к выпуску
Обзор
Neural Tangents - это высокоуровневый API нейронной сети для определения сложных иерархических нейронных сетей конечной и бесконечной ширины . Нейронные касательные позволяют исследователям определять, обучать и оценивать бесконечные сети так же легко, как и конечные.
Бесконечные (по ширине или количеству каналов) нейронные сети - это гауссовские процессы (GP) с функцией ядра, определяемой их архитектурой. Подробности и нюансы переписки см. В разделе «Ссылки». Также смотрите этот список статей, написанных создателями Neural Tangents, в которых изучается предел бесконечной ширины нейронных сетей.
Neural Tangents позволяет построить модель нейронной сети из общих строительных блоков, таких как свертки, пулы, остаточные соединения, нелинейности и т. Д., И получить не только конечную модель, но и функцию ядра соответствующего GP.
Библиотека написана на python с использованием JAX и XLA для запуска "из коробки" на CPU, GPU или TPU. Вычисления ядра оптимизированы по скорости и эффективности использования памяти и могут автоматически распределяться по нескольким ускорителям с почти идеальным масштабированием.
Neural Tangents находится в стадии разработки. Мы с радостью приветствуем вклады!
Содержание
Ноутбуки Colab
Легкий способ начать работу с Neural Tangents - это поиграть со следующими интерактивными блокнотами в Colaboratory.Они демонстрируют основные функции Neural Tangents и показывают, как их можно использовать в исследованиях.
Установка
Чтобы использовать графический процессор, сначала следуйте инструкциям по установке графического процессора JAX. В противном случае установите JAX на ЦП, запустив
pip install jax jaxlib --upgrade
После установки JAX установите Neural Tangents, запустив
pip install neural-tangents
или, если использовать новейшую версию из исходников GitHub,
git clone https: // github.com / google / neural-tangents; cd нейронные касательные
pip install -e.
Теперь вы можете запускать примеры (используя tensorflow_datasets )
и тесты по телефону:
pip install tensorflow tensorflow-datasets more-itertools --upgrade
Примеры Python / infinite_fcn.py
примеры Python / weight_space.py
примеры Python / function_space.py
set -e; для f в tests / *. py; сделать python $ f; сделано
5-минутное вступление
См. Этот Colab для подробного руководства.Ниже очень краткое введение.
Наша библиотека точно следует JAX API для определения нейронных сетей, stax . В stax сеть определяется парой функций (init_fn, apply_fn) , инициализирующих обучаемые параметры и вычисляющих выходы сети соответственно. Ниже приведен пример определения трехуровневой сети и вычисления ее выходных данных y с учетом входных данных x .
из jax import random
от jax.экспериментальный импортный налог
init_fn, apply_fn = stax.serial (
stax.Dense (512), stax.Relu,
stax.Dense (512), stax.Relu,
stax.Dense (1)
)
ключ = random.PRNGKey (1)
x = random.normal (ключ, (10, 100))
_, params = init_fn (ключ, input_shape = x.shape)
y = apply_fn (params, x) # (10, 1) np.ndarray выходы нейронной сети Neural Tangents предназначен для замены stax , расширяя кортеж (init_fn, apply_fn) до тройного (init_fn, apply_fn, kernel_fn) , где kernel_fn - это функция ядра бесконечная сеть (GP) данной архитектуры.Ниже приведен пример вычисления ковариаций GP между двумя пакетами входных данных x1 и x2 .
из jax import random
from neural_tangents import stax
init_fn, apply_fn, kernel_fn = stax.serial (
stax.Dense (512), stax.Relu (),
stax.Dense (512), stax.Relu (),
stax.Dense (1)
)
ключ1, ключ2 = random.split (random.PRNGKey (1))
x1 = random.normal (ключ1, (10, 100))
x2 = random.normal (ключ2, (20, 100))
ядро = kernel_fn (x1, x2, 'nngp') Обратите внимание, что kernel_fn может вычислить две ковариационные матрицы , соответствующие ядрам гауссовского процесса нейронной сети (NNGP) и нейронного касательного (NT) соответственно.Ядро NNGP соответствует байесовской бесконечной нейронной сети [1-5]. NTK соответствует обученной бесконечной сети (непрерывный) градиентным спуском [10]. В приведенном выше примере мы вычисляем ядро NNGP, но можем вычислить NTK или и то, и другое:
# Получить ядро одного типа
nngp = kernel_fn (x1, x2, 'nngp') # (10, 20) np.ndarray
ntk = kernel_fn (x1, x2, 'ntk') # (10, 20) np.ndarray
# Получить ядра в виде именованного кортежа
оба = kernel_fn (x1, x2, ('nngp', 'ntk'))
оба.nngp == nngp # Верно
both.ntk == ntk # Верно
# Распаковать ядра с именем tuple
nngp, ntk = kernel_fn (x1, x2, ('nngp', 'ntk')) Кроме того, если не указан третий аргумент, kernel_fn вернет именованный кортеж Kernel , который содержит дополнительные метаданные. Это может быть полезно для составления приложений kernel_fn следующим образом:
ядро = kernel_fn (x1, x2) ядро = kernel_fn (ядро) печать (kernel.nngp)
Выполнение логического вывода с бесконечными сетями, обученными на потерях MSE, сводится к классическому выводу GP, для которого мы также предоставляем удобные инструменты:
импортировать neural_tangents как nt
x_train, x_test = x1, x2
y_train = случайный.uniform (key1, shape = (10, 1)) # тренировочные цели
predict_fn = nt.predict.gradient_descent_mse_ensemble (kernel_fn, x_train,
y_train)
y_test_nngp = pred_fn (x_test = x_test, get = 'nngp')
# (20, 1) np.ndarray тестовые предсказания бесконечной байесовской сети
y_test_ntk = pred_fn (x_test = x_test, get = 'ntk')
# (20, 1) np.ndarray тестовые предсказания бесконечного непрерывного
# обученная сеть градиентным спуском при сходимости (t = inf)
# Получение прогнозов в виде именованного кортежа
both = pred_fn (x_test = x_test, get = ('nngp', 'ntk'))
оба.nngp == y_test_nngp # Истина
both.ntk == y_test_ntk # Истина
# Распаковываем предсказания namedtuple
y_test_nngp, y_test_ntk = pred_fn (x_test = x_test, get = ('nngp', 'ntk')) Бесконечно широкий
Мы можем определить более сложную (бесконечно) широкую остаточную сеть [14], используя те же строительные блоки nt.stax :
из neural_tangents import stax
def WideResnetBlock (каналы, strides = (1, 1), channel_mismatch = False):
Main = stax.serial (
stax.Relu (), stax.Conv (каналы, (3, 3), strides, padding = 'SAME'),
stax.Relu (), stax.Conv (каналы, (3, 3), padding = 'SAME'))
Shortcut = stax.Identity () если не channel_mismatch else stax.Conv (
каналы, (3, 3), шаги, padding = 'SAME')
вернуть stax.serial (stax.FanOut (2),
stax.parallel (основной, ярлык),
stax.FanInSum ())
def WideResnetGroup (n, каналы, strides = (1, 1)):
блоки = []
блоки + = [WideResnetBlock (каналы, шаги, channel_mismatch = True)]
для _ в диапазоне (n - 1):
блоки + = [WideResnetBlock (каналы, (1, 1))]
возврат стакс.серийный (* блоки)
def WideResnet (размер_блока, k, num_classes):
вернуть stax.serial (
stax.Conv (16, (3, 3), padding = 'SAME'),
WideResnetGroup (размер_блока, int (16 * k)),
WideResnetGroup (размер_блока, int (32 * k), (2, 2)),
WideResnetGroup (размер_блока, int (64 * k), (2, 2)),
stax.AvgPool ((8, 8)),
stax.Flatten (),
stax.Dense (число_классов, 1., 0.))
init_fn, apply_fn, kernel_fn = WideResnet (block_size = 4, k = 1, num_classes = 10) Описание упаковки
Пакет neural_tangents ( nt ) содержит следующие модули и функции:
stax- примитивы для построения нейронных сетей, такие какConv,Relu,последовательный,параллельныйи т. Д.прогноз- прогнозы с бесконечными сетями:predient.gradient_descent_mse- логический вывод с единственной бесконечной шириной / линеаризованной сетью, обученной на потерях MSE с непрерывным градиентным спуском в течение произвольного конечного или бесконечного (t = None) времени. Вычислено в закрытом виде.predient.gradient_descent- логический вывод с одной бесконечной шириной / линеаризованной сетью, обученной произвольным потерям с непрерывным (импульсным) градиентным спуском в течение произвольного конечного времени.Вычислено с использованием решателя ODE.predient.gradient_descent_mse_ensemble- вывод с бесконечным ансамблем сетей бесконечной ширины, либо полностью байесовский (get = 'nngp'), либо вывод с потерями MSE с использованием непрерывного градиентного спуска (get = 'ntk'). Байесовский вывод с конечным временем (например,t = 1., Get = 'nngp') интерпретируется как градиентный спуск только на верхнем уровне [11], поскольку он сходится к точному выводу гауссовского процесса с NNGP (t = None, получить = 'nngp').Вычислено в закрытом виде.прогноз. Gp_inference- точный гауссовский вывод процесса в закрытой форме с использованием NNGP (get = 'nngp'), NTK (get = 'ntk') или обоих (get = ('nngp', 'ntk') )). Эквивалентpredient.gradient_descent_mse_ensembleсt = None(бесконечное время обучения), но имеет немного другой API (принимает предварительно вычисленную матрицу ядраk_train_trainвместоkernel_fnиx_train).
monte_carlo_kernel_fn- вычислить оценку ядра Монте-Карло любую(init_fn, apply_fn), не обязательно заданную черезnt.stax, что позволяет вычислять ядро бесконечных сетей без выражений в замкнутой форме.Инструменты для исследования динамики обучения широких , но конечных нейронных сетей , например
линеаризации,taylor_expand,empirical_kernel_fnи других.Подробнее см. Динамика обучения широких, но конечных сетей.
Технические ошибки
nt.stax vs jax.experimental.stax Отметим следующие отличия нашей библиотеки от JAX.
- Все уровни
nt.staxсоздаются с помощью вызова функции, то естьnt.stax.Relu ()vsjax.experimental.stax.Relu. - Все слои с обучаемыми параметрами по умолчанию используют параметризацию NTK (см. [10], замечание 1).Однако уровни Dense и Conv также поддерживают стандартную параметризацию с помощью аргумента ключевого слова
параметризации(см. [15]). -
nt.staxиjax.experimental.staxмогут иметь разные доступные слои и параметры (например,nt.staxслои поддерживают заполнениеCIRCULAR, имеютLayerNorm, но неBatchNorm.).
Производительность процессора и TPU
Для CNN с пулом производительность нашего процессора и TPU неоптимальна из-за низкого уровня ядра. загрузка (10-20%, похоже, проблема XLA: CPU) и чрезмерное заполнение соответственно.Мы постараемся улучшить производительность, но рекомендуем графические процессоры NVIDIA. в это время. См. «Производительность».
Динамика обучения широких, но конечных сетей
Ядро бесконечной сети kernel_fn (x1, x2) .ntk в сочетании с nt.predict.gradient_descent_mse вместе позволяет аналитически отслеживать выходы бесконечно широкой нейронной сети, обученной на потерях MSE в процессе обучения. Здесь мы обсуждаем последствия для широких , но конечных нейронных сетей и представляем инструменты для изучения их эволюции в весовом пространстве (обучаемые параметры сети) и функциональном пространстве (выходы сети).
Весовая площадь
Непрерывный градиентный спуск в бесконечной сети, как было показано в [11], соответствует обучению линейной модели (в обучаемых параметрах), что делает линеаризованные нейронные сети важным предметом исследования для понимания поведения параметров в широких моделях.
Для этого мы предоставляем две удобные функции:
-
без линеаризациии -
nt.taylor_expand,
, которые позволяют линеаризовать или получить разложение Тейлора произвольного порядка любой функции apply_fn (params, x) вокруг некоторых начальных параметров params_0 as apply_fn_lin = nt.линеаризовать (применить_fn, params_0) .
Можно использовать apply_fn_lin (params, x) точно так же, как любую другую функцию
(в том числе в качестве входных данных для оптимизаторов JAX). Это позволяет легко сравнивать
траектория обучения нейронных сетей с траекторией ее линеаризации.
Предыдущая теория и эксперименты изучали линеаризацию нейронной
сети от входов до логитов или предварительных активаций, а не от входов до
постактивации, которые существенно более нелинейны.
Пример:
импорт jax.numpy as np импортировать neural_tangents как nt def apply_fn (params, x): W, b = параметры вернуть np.dot (x, W) + b W_0 = np.array ([[1., 0.], [0., 1.]]) b_0 = np.zeros ((2,)) apply_fn_lin = nt.linearize (apply_fn, (W_0, b_0)) W = np.array ([[1,5, 0,2], [0,1, 0,9]]) б = b_0 + 0,2 x = np.array ([[0,3, 0,2], [0,4, 0,5], [1,2, 0,2]]) logits = apply_fn_lin ((W, b), x) # (3, 2) np.ndarray
Функциональное пространство:
Выходные данные линеаризованной модели развиваются так же, как выходы бесконечной модели [11], но с другим ядром - в частности, Neural Tangent Kernel [10], оцениваемым на конкретном apply_fn конечной сети с конкретным params_0 , что сеть инициализируется с помощью.Для этого мы предоставляем функцию nt.empirical_kernel_fn , которая принимает любой apply_fn и возвращает kernel_fn (x1, x2, get, params) , что позволяет вычислить эмпирические NTK и / или NNGP (на основе get ) ядра по конкретным параметрам .
Пример:
импортировать jax.random как случайный импортировать jax.numpy как np импортировать neural_tangents как nt def apply_fn (params, x): W, b = параметры вернуть np.dot (x, W) + b W_0 = np.array ([[1., 0.], [0., 1.]]) b_0 = np.zeros ((2,)) params = (W_0, b_0) ключ1, ключ2 = random.split (random.PRNGKey (1), 2) x_train = random.normal (ключ1, (3, 2)) x_test = random.normal (ключ2, (4, 2)) y_train = random.uniform (ключ1, форма = (3, 2)) kernel_fn = nt.empirical_kernel_fn (применить_fn) ntk_train_train = kernel_fn (x_train, None, 'ntk', params) ntk_test_train = kernel_fn (x_test, x_train, 'ntk', параметры) mse_predictor = nt.predict.gradient_descent_mse (ntk_train_train, y_train) т = 5. y_train_0 = apply_fn (параметры, x_train) y_test_0 = apply_fn (параметры, x_test) y_train_t, y_test_t = mse_predictor (t, y_train_0, y_test_0, ntk_test_train) # (3, 2) и (4, 2) np.ndarray поезд и тестовые выходы через t единиц времени # обучение с непрерывным градиентным спуском
Чего ожидать
Успех или неудача линейного приближения в значительной степени зависят от архитектуры. зависимый. Однако мы придерживаемся следующих практических правил:
Сходимость по мере увеличения размера сети.
Для полносвязных сетей обычно наблюдается очень сильная согласие к тому времени, когда ширина слоя составляет 512 (RMSE около 0.05 в конец обучения).
Для сверточных сетей обычно соблюдается разумное согласие согласование к моменту времени количество каналов 512.
Конвергенция при малых темпах обучения.
Поэтому с новой моделью рекомендуется начинать с очень большой модели на небольшой набор данных с небольшой скоростью обучения.
Производительность
В таблице ниже мы измеряем время для вычисления одного NTK
запись в 21-слойной CNN ( 3x3, фильтров, без шагов, SAME padding, ReLU ) на входах формы 3x32x32 .Точно:
слоев = [] для _ в диапазоне (21): Layers + = [stax.Conv (1, (3, 3), (1, 1), 'SAME'), stax.Relu ()]
CNN с объединением
Верхний слой - stax.GlobalAvgPool () :
_, _, kernel_fn = stax.serial (* (слои + [stax.GlobalAvgPool ()]))
| Платформа | Точность | Миллисекунд / запись NTK | Макс.размер партии ( NxN ) |
|---|---|---|---|
| ЦП,> 56 ядер,> 700 ГБ ОЗУ | 32 | 112.90 | > = 128 |
| ЦП,> 56 ядер,> 700 ГБ ОЗУ | 64 | 258,55 | 95 (самый быстрый - 72) |
| TPU v2 | 32/16 | 3,2550 | 16 |
| TPU v3 | 32/16 | 2.3022 | 24 |
| NVIDIA P100 | 32 | 5,9433 | 26 |
| NVIDIA P100 | 64 | 11.349 | 18 |
| NVIDIA V100 | 32 | 2,7001 | 26 |
| NVIDIA V100 | 64 | 6.2058 | 18 |
CNN без объединения
Верхний слой - шт. Плоский () :
_, _, kernel_fn = stax.serial (* (слои + [stax.Flatten ()]))
| Платформа | Точность | Миллисекунд / запись NTK | Макс.размер партии ( NxN ) |
|---|---|---|---|
| ЦП,> 56 ядер,> 700 ГБ ОЗУ | 32 | 0.12013 | 2048 <= N <4096 (самый быстрый - 512) |
| ЦП,> 56 ядер,> 700 ГБ ОЗУ | 64 | 0,3414 | 2048 <= N <4096 (самый быстрый - 256) |
| TPU v2 | 32/16 | 0,0015722 | 512 <= N <1024 |
| TPU v3 | 32/16 | 0,0010647 | 512 <= N <1024 |
| NVIDIA P100 | 32 | 0.015171 | 512 <= N <1024 |
| NVIDIA P100 | 64 | 0,019894 | 512 <= N <1024 |
| NVIDIA V100 | 32 | 0,0046510 | 512 <= N <1024 |
| NVIDIA V100 | 64 | 0,010822 | 512 <= N <1024 |
Проверено с использованием версии 0.2.1 . Все результаты графического процессора приведены для одного ускорителя.Обратите внимание, что время выполнения пропорционально глубине вашей сети.
Если ваша производительность значительно отличается,
пожалуйста, сообщите об ошибке!
Миртовая сеть
Тест производительности ноутбуков Colab
демонстрирует, как построить и протестировать ядра. Демонстрировать
гибкость, мы взяли архитектуру из [16]
В качестве примера. С NVIDIA V100 64-битной точностью, nt занял 316/330/508 GPU-часов на полном наборе данных 60k CIFAR-10 для ядер Myrtle-5/7/10.
Документы
Нейронные касательные использовались в следующих статьях (начиная с новейших):
- Вариационные байесовские нейронные сети с широким средним полем игнорируют данные
- Спектральное смещение и согласование модели задачи объясняют обобщение в ядерной регрессии и бесконечно широких нейронных сетях
- Соединение многозадачного обучения и метаобучения: на пути к эффективному обучению и эффективной адаптации
- Вариационные байесовские нейронные сети с широким средним полем игнорируют данные
- Что на самом деле могут сказать линеаризованные нейронные сети об обобщении?
- Измерение чувствительности гауссовских процессов к выбору ядра
- Перспектива GAN с точки зрения нейронного касательного ядра
- О силе поверхностного обучения
- Кривые обучения для SGD по структурированным функциям
- Обобщение вне распределения в регрессии ядра
- Rapid Feature Evolution ускоряет обучение в нейронных сетях
- Масштабируемая и гибкая глубинная байесовская оптимизация со вспомогательной информацией для научных задач
- Случайные особенности для нейронного касательного ядра
- Многоуровневая точная настройка: устранение пробелов в обобщении в приближении карт решений при ограниченном бюджете на обучение данных
- Объяснение законов нейронного масштабирования
- Коррелированные веса в бесконечных пределах глубоких сверточных нейронных сетей
- Мета-обучение набора данных из ядра Ridge-Regression
- Глубокое обучение в сравнении с обучением в ядре: эмпирическое исследование геометрии ландшафта потерь и эволюции во времени нейронного касательного ядра
- Стабильный ResNet
- Нейронно-касательное ядро с поддержкой меток: к лучшему обобщению и локальной эластичности
- Полу-контролируемое пакетное активное обучение с помощью двухуровневой оптимизации
- Проверка температуры: теория и практика для обучения моделей с softmax-кросс-энтропийными потерями
- Экспериментальный дизайн для чрезмерно параметризованного обучения с применением однократного глубокого активного обучения
- Как экстраполировать нейронные сети: от прямой связи до графических нейронных сетей
- Исследование свойств неопределенности неявных априорных элементов нейронных сетей в пределе бесконечной ширины
- Холодные постеры и алеаторическая неопределенность
- Асимптотика широких сверточных нейронных сетей
- Конечные и бесконечные нейронные сети: эмпирическое исследование
- Байесовские глубокие ансамбли через нейронное касательное ядро
- Удивительная простота раннего обучения динамике нейронных сетей
- Когда нейронные сети превосходят методы ядра?
- Статистическая механика обобщения в ядерной регрессии
- Точные апостериорные распределения широких байесовских нейронных сетей
- Бесконечное внимание: NNGP и NTK для сетей глубокого внимания Функции
- Фурье позволяют сетям изучать высокочастотные функции в низкоразмерных областях
- Поиск обучаемых разреженных сетей с помощью нейронной касательной передачи
- Coresets через двухуровневую оптимизацию для непрерывного обучения и потоковой передачи
- О нейронном касательном ядре глубоких сетей с ортогональной инициализацией
- Фаза глубокого обучения с большой скоростью обучения: механизм катапульты
- Спектрально-зависимые кривые обучения в регрессии ядра и широких нейронных сетях
- Тейлоризованное обучение: к лучшему приближению обучения нейронной сети при конечной ширине
- О пределе бесконечной ширины нейронных сетей со стандартной параметризацией
- Разделение обучаемости и обобщения в глубоком обучении
- Информация в бесконечных ансамблях бесконечно широких нейронных сетей
- Обучение динамике глубоких сетей с использованием стохастического градиентного спуска через нейронное касательное ядро Широкие нейронные сети
- любой глубины развиваются как линейные модели под действием градиента Спуск
- Байесовские глубокие сверточные сети с множеством каналов являются гауссовскими процессами
Сообщите нам, если вы используете код в публикации, и мы добавим его в список!
Цитата
Если вы используете код в публикации, процитируйте, пожалуйста, нашу статью ICLR 2020:
@inproceedings {neuraltangents2020,
title = {Нейронные касательные: быстрые и простые бесконечные нейронные сети в Python},
автор = {Роман Новак, Лехао Сяо, Джири Хрон, Джэхун Ли и Александр А.Alemi и Jascha Sohl-Dickstein и Samuel S. Schoenholz},
booktitle = {Международная конференция по образовательным представлениям},
год = {2020},
url = {https://github.com/google/neural-tangents}
}
Список литературы
[1] Приоры для бесконечных сетей
[2] Экспоненциальная выразительность в глубоких нейронных сетях через временный хаос
[3] На пути к более глубокому пониманию нейронных сетей: сила инициализации и двойной взгляд на выразительность
[4] Распространение глубокой информации
[5] Глубокие нейронные сети как гауссовские процессы
[6] Поведение гауссовского процесса в широких глубоких нейронных сетях
[7] Динамическая изометрия и теория среднего поля CNN: Как обучить 10 000-слойные сверточные нейронные сети.
[8] Байесовские глубокие сверточные сети с множеством каналов являются гауссовскими процессами
[9] Глубокие сверточные сети как мелкие гауссовские процессы
[10] Нейронное касательное ядро: сходимость и обобщение в нейронных сетях
[11] Широкие нейронные сети любой глубины развиваются как линейные модели при градиентном спуске
[12] Пределы масштабирования широких нейронных сетей с разделением веса: поведение процесса по Гауссу, независимость от градиента и вывод нейронного касательного ядра
[13] Остаточные сети среднего поля: на краю хаоса
[14] Широкие остаточные сети
[15] О пределе бесконечной ширины нейронных сетей со стандартной параметризацией
[16] Нейронные ядра без касательных
Половой отбор | Изучайте науку в Scitable
Бейтман, А.J. Межполовый отбор в Дрозофила. Наследственность 2 , 349-368 (1948).
Биркхед, Т. Р. и Моллер, А. П. Конкуренция сперматозоидов и половой отбор . Сан-Диего, Калифорния: Academic Press, 1998.
Калхим, С. и Биркхед, Т. Р. Тестес размер птицы: качество по сравнению с количеством - допущения, ошибки и оценки. Поведенческая экология 18 , 271-275 (2007).
Chapman, T., Arnqvist, G. et al. Сексуальный конфликт. Тенденции в экологии и эволюции 3 , 41-47 (2003).
Клаттон-Брок, Т. Х. и Паркер, Г. А. Сексуальное принуждение в обществе животных. Животные Поведение 49 , 1345-1365 (1995).
Кронин, Х. Муравей и павлин . Кембридж, Великобритания: Кембриджский университет Пресс, 1991.
Дарвин, К. Происхождение мужчины и отбор по признаку пола . Лондон, Великобритания: Мюррей, 1871 г.
Эберхард, В. Женский контроль: половой отбор тайным женским выбором . Принстон, Нью-Джерси: Принстон Университет Press, 1996.
Эмлен Д. Дж. Эволюция Оружие животных. Ежегодный обзор экологии , Систематика, и эволюция 39 , 387-413 (2008).
Фишер Р. А. Генетическая теория естественного отбора . Оксфорд, Великобритания: Clarendon Press, 1930.
Гамильтон, В. Д. и Зук, М. Наследие настоящий фитнес и яркие птицы: роль паразитов? Наука 218, 384-387 (1982).
Келлер, Л. и Рив, Х. К. Почему женщины спариваться с несколькими самцами? Гипотеза сперматозоидов, отобранных половым путем. Продвинутые исследования поведения , 24 , 291-315 (1997).
Киркпатрик М. Половой отбор и эволюция женского выбора. Evolution 82, 1-12 (1982).
Lande, R. Модели видообразования половым путем. селекция по полигенным признакам. Извещений Национальной академии наук, USA 78, 3721-3725 (1981).
LeBoeuf, B. Соревнования между мужчинами и репродуктивный успех морских слонов. американец Зоолог 14 , 163-176 (1974)
Паркер, Г. Конкуренция спермы и ее эволюционные последствия у насекомых. Биологический Обзоры 45, 525-567 (1970).
Паркер, Г. Половой отбор и половая принадлежность конфликт. В Половой отбор и Репродуктивная конкуренция насекомых . ред. Блюм, М. С. и Блюм, Н. А. (Нью-Йорк: Academic Press, 1979): 123-166.
Prum, R.O. Филогенетический анализ эволюции демонстрационного поведения неотропических манакинов (Aves: Pipridae). Этология 84 , 202-231 (1990).
Штутт, А. Д., Шива-Джоти, М. Т. Травматик осеменение и половой конфликт у постельного клопа Cimex lectularius. Proceedings of the National Academy of Sciences , U.S.A., 98 , 5683-5687 (2001)
Trivers, R.L. Родительские инвестиции и половой отбор.В Половой отбор и Происхождение человека 1871–1971 . изд. Кэмпбелл, Б. (Лондон: Heinemann 1972): 136-179.
Захави, A. Выбор партнера: выбор для гандикапа. Журнал теоретической биологии 53, 205-214 (1975).
Изучение PyTorch с примерами - Руководства по PyTorch 1.9.0 + документация cu102
Автор : Джастин Джонсон
Примечание
Это одно из наших старых руководств по PyTorch.Вы можете просмотреть наши последние контент для начинающих в Изучите основы.
В этом руководстве представлены основные концепции PyTorch через автономный Примеры.
По своей сути PyTorch предоставляет две основные функции:
- n-мерный тензор, похожий на numpy, но может работать на графических процессорах
- Автоматическое дифференцирование для построения и обучения нейронных сетей
Мы будем использовать задачу аппроксимации \ (y = \ sin (x) \) полиномом третьего порядка в качестве нашего рабочего примера.Сеть будет иметь четыре параметра и будет обучаться с градиентный спуск для соответствия случайным данным за счет минимизации евклидова расстояния между выходом сети и истинным выходом.
Разминка: numpy
Перед тем, как представить PyTorch, мы сначала реализуем сеть, используя тупой.
Numpy предоставляет объект n-мерного массива и множество функций для манипулирование этими массивами. Numpy - это общая структура для научных вычисления; он ничего не знает о графах вычислений или глубоких обучение или градиенты.Однако мы можем легко использовать numpy для соответствия полином третьего порядка в синусоидальную функцию путем ручной реализации прямого и обратный проход через сеть с использованием numpy-операций:
# - * - кодировка: utf-8 - * -
импортировать numpy как np
импортная математика
# Создание случайных входных и выходных данных
x = np.linspace (-math.pi, math.pi, 2000)
у = np.sin (х)
# Произвольно инициализировать веса
a = np.random.randn ()
b = np.random.randn ()
c = np.random.randn ()
d = np.random.randn ()
learning_rate = 1e-6
для t в диапазоне (2000):
# Прямой проход: вычислить прогнозируемое y
# y = a + b x + c x ^ 2 + d x ^ 3
y_pred = a + b * x + c * x ** 2 + d * x ** 3
# Потеря вычислений и печати
потеря = np. 3 ')
PyTorch: Тензоры
Numpy - отличный фреймворк, но он не может использовать графические процессоры для ускорения своего численные расчеты.Для современных глубоких нейронных сетей графические процессоры часто обеспечить ускорение в 50 раз или больше, так что к сожалению, numpy недостаточно для современного глубокого обучения.
Здесь мы представляем самую фундаментальную концепцию PyTorch: Tensor . PyTorch Tensor концептуально идентичен массиву numpy: Tensor - это n-мерный массив, а PyTorch предоставляет множество функций для на этих тензорах. За кулисами тензорные системы могут отслеживать вычислительный график и градиенты, но они также полезны как универсальный инструмент для научных вычислений.
Также в отличие от numpy, PyTorch Tensors может использовать графические процессоры для ускорения их числовые вычисления. Чтобы запустить PyTorch Tensor на GPU, вы просто необходимо указать правильное устройство.
Здесь мы используем тензоры PyTorch, чтобы подогнать полином третьего порядка к синусоидальной функции. Как и в приведенном выше примере numpy, нам нужно вручную реализовать переадресацию и обратно проходит по сети:
# - * - кодировка: utf-8 - * -
импортный фонарик
импортная математика
dtype = torch.float
устройство = torch.device ("процессор")
# устройство = фонарик.device ("cuda: 0") # Раскомментируйте это, чтобы запустить на GPU
# Создание случайных входных и выходных данных
x = torch.linspace (-math.pi, math.pi, 2000, устройство = устройство, dtype = dtype)
y = torch.sin (x)
# Произвольно инициализировать веса
a = torch.randn ((), устройство = устройство, dtype = dtype)
b = torch.randn ((), device = device, dtype = dtype)
c = torch.randn ((), устройство = устройство, dtype = dtype)
d = torch.randn ((), устройство = устройство, dtype = dtype)
learning_rate = 1e-6
для t в диапазоне (2000):
# Прямой проход: вычислить прогнозируемое y
y_pred = a + b * x + c * x ** 2 + d * x ** 3
# Потеря вычислений и печати
потеря = (y_pred - y).pow (2) .sum (). элемент ()
если t% 100 == 99:
print (t, убыток)
# Backprop для вычисления градиентов a, b, c, d с учетом потерь
grad_y_pred = 2,0 * (y_pred - y)
grad_a = grad_y_pred.sum ()
grad_b = (grad_y_pred * x) .sum ()
grad_c = (grad_y_pred * x ** 2) .sum ()
grad_d = (grad_y_pred * x ** 3) .sum ()
# Обновить веса с помощью градиентного спуска
a - = скорость_обучения * град_а
b - = скорость_обучения * grad_b
c - = скорость_обучения * grad_c
d - = скорость_обучения * град_д
print (f'Result: y = {a.3 ')
PyTorch: Тензоры и автоград
В приведенных выше примерах нам пришлось вручную реализовать как форвард, так и обратные проходы нашей нейронной сети. Реализация вручную обратный проход не имеет большого значения для небольшой двухуровневой сети, но может быстро становится очень проблематичным для больших сложных сетей.
К счастью, мы можем использовать автоматический дифференциация для автоматизации вычисления обратных проходов в нейронных сетях. В autograd Пакет в PyTorch обеспечивает именно эту функциональность.При использовании автограда прямой проход вашей сети будет определять вычислительный граф ; узлы в графе будут тензорами, а ребра будут функциями, которые производят выходные тензоры из входных тензоров. Обратное распространение через этот график затем позволяет легко вычислить градиенты.
Звучит сложно, но на практике довольно просто. Каждый тензор
представляет узел в вычислительном графе. Если x - тензор, имеющий x.requires_grad = Истина , затем x.grad - еще один тензор,
градиент x относительно некоторого скалярного значения.
Здесь мы используем PyTorch Tensors и autograd для реализации нашей подходящей синусоиды. с примером полинома третьего порядка; теперь нам больше не нужно вручную реализовать обратный проход по сети:
# - * - кодировка: utf-8 - * -
импортный фонарик
импортная математика
dtype = torch.float
устройство = torch.device ("процессор")
# device = torch.device ("cuda: 0") # Раскомментируйте это, чтобы запустить на GPU
# Создать тензоры для хранения ввода и вывода.3
# Настройка requires_grad = True указывает, что мы хотим вычислять градиенты с
# уважение к этим тензорам во время обратного прохода.
a = torch.randn ((), устройство = устройство, dtype = dtype, requires_grad = True)
b = torch.randn ((), устройство = устройство, dtype = dtype, requires_grad = True)
c = torch.randn ((), устройство = устройство, dtype = dtype, requires_grad = True)
d = torch.randn ((), устройство = устройство, dtype = dtype, requires_grad = True)
learning_rate = 1e-6
для t в диапазоне (2000):
# Прямой проход: вычисление прогнозируемого y с использованием операций над тензорами.y_pred = a + b * x + c * x ** 2 + d * x ** 3
# Вычислить и распечатать потери с помощью операций с тензорами.
# Теперь потеря - это тензор формы (1,)
# loss.item () получает скалярное значение убытка.
потеря = (y_pred - y) .pow (2) .sum ()
если t% 100 == 99:
print (t, loss.item ())
# Используйте autograd для вычисления обратного прохода. Этот вызов вычислит
# градиент потерь по всем тензорам с requires_grad = True.
# После этого вызовите a.grad, b.grad. c.grad и d.град будет тензорным холдингом
# градиент потерь относительно a, b, c, d соответственно.
loss.backward ()
# Вручную обновить веса с помощью градиентного спуска. Завернуть в torch.no_grad ()
# потому что у весов requires_grad = True, но нам не нужно это отслеживать
# в автограде.
с torch.no_grad ():
a - = скорость_обучения * a.grad
b - = скорость_обучения * b.grad
c - = скорость_обучения * c.grad
d - = скорость_обучения * d.grad
# Вручную обнулить градиенты после обновления весов
а.3 ')
PyTorch: определение новых функций автограда
Под капотом у каждого примитивного оператора автограда действительно две функции которые работают с тензорами. Функция вперед вычисляет вывод Тензоры из входных Tensors. Функция назад получает градиент выходных тензоров относительно некоторого скалярного значения, и вычисляет градиент входных тензоров относительно того же скалярное значение.
В PyTorch мы можем легко определить наш собственный оператор автограда, определив
подкласс горелки .3-3x \ вправо) \)
- полином Лежандра третьей степени. Пишем свой кастомный автоград
функция для вычисления вперед и назад \ (P_3 \), и использовать ее для реализации
наша модель:
# - * - кодировка: utf-8 - * -
импортный фонарик
импортная математика
класс LegendrePolynomial3 (torch.autograd.Function):
"" "
Мы можем реализовать наши собственные пользовательские функции автограда, создав подклассы
torch.autograd.Function и реализация прямого и обратного проходов
которые работают с тензорами.
"" "
@staticmethod
def forward (ctx, ввод):
"" "
В прямом проходе мы получаем тензор, содержащий ввод и возврат
Тензор, содержащий вывод.ctx - это объект контекста, который можно использовать
хранить информацию для обратных вычислений. Вы можете кешировать произвольные
объекты для использования в обратном проходе с помощью метода ctx.save_for_backward.
"" "
ctx.save_for_backward (ввод)
возврат 0,5 * (5 * ввод ** 3 - 3 * ввод)
@staticmethod
def назад (ctx, grad_output):
"" "
При обратном проходе мы получаем тензор, содержащий градиент потери
относительно выхода, и нам нужно вычислить градиент потерь
относительно входа."" "
input, = ctx.saved_tensors
вернуть grad_output * 1.5 * (5 * input ** 2-1)
dtype = torch.float
устройство = torch.device ("процессор")
# device = torch.device ("cuda: 0") # Раскомментируйте это, чтобы запустить на GPU
# Создать тензоры для хранения ввода и вывода.
# По умолчанию requires_grad = False, что означает, что нам не нужно
# вычислить градиенты относительно этих тензоров во время обратного прохода.
x = torch.linspace (-math.pi, math.pi, 2000, устройство = устройство, dtype = dtype)
y = torch.sin (x)
# Создать случайные тензоры для весов.Для этого примера нам понадобится
# 4 веса: y = a + b * P3 (c + d * x), эти веса необходимо инициализировать
# не слишком далеко от правильного результата, чтобы гарантировать сходимость.
# Настройка requires_grad = True указывает, что мы хотим вычислять градиенты с
# уважение к этим тензорам во время обратного прохода.
a = torch.full ((), 0.0, устройство = устройство, dtype = dtype, requires_grad = True)
b = torch.full ((), -1,0, устройство = устройство, dtype = dtype, requires_grad = True)
c = torch.full ((), 0.0, устройство = устройство, dtype = dtype, requires_grad = True)
d = факел.полный ((), 0.3, устройство = устройство, dtype = dtype, requires_grad = True)
learning_rate = 5e-6
для t в диапазоне (2000):
# Чтобы применить нашу функцию, мы используем метод Function.apply. Мы называем это «P3».
P3 = LegendrePolynomial3.apply
# Прямой проход: вычисление предсказанного y с помощью операций; мы вычисляем
# P3 с использованием нашей пользовательской операции автограда.
y_pred = a + b * P3 (c + d * x)
# Потеря вычислений и печати
потеря = (y_pred - y) .pow (2) .sum ()
если t% 100 == 99:
print (t, loss.item ())
# Используйте autograd для вычисления обратного прохода.loss.backward ()
# Обновить веса с помощью градиентного спуска
с torch.no_grad ():
a - = скорость_обучения * a.grad
b - = скорость_обучения * b.grad
c - = скорость_обучения * c.grad
d - = скорость_обучения * d.grad
# Вручную обнулить градиенты после обновления весов
a.grad = Нет
b.grad = Нет
c.grad = Нет
d.grad = Нет
print (f'Result: y = {a.item ()} + {b.item ()} * P3 ({c.item ()} + {d.item ()} x) ')
PyTorch: nn
Вычислительные графы и автоград - очень мощная парадигма для определение сложных операторов и автоматическое получение производных; Однако для больших нейронных сетей raw autograd может быть слишком низкоуровневым.
При построении нейронных сетей мы часто думаем об организации вычисление в слоях , некоторые из которых имеют обучаемых параметров которые будут оптимизированы во время обучения.
В TensorFlow такие пакеты, как Керас, TensorFlow-Slim, и TFLearn предоставляют абстракции более высокого уровня над необработанными вычислительными графами, которые полезны для построения нейронных сети.
В PyTorch пакет nn служит той же цели. Модель nn пакет определяет набор из модулей , которые примерно эквивалентны
слои нейронной сети.Модуль получает входные тензоры и вычисляет
выходные тензоры, но также могут содержать внутреннее состояние, такое как тензоры
содержащие обучаемые параметры. Пакет nn также определяет набор
полезных функций потерь, которые обычно используются при обучении нейронной
сети.
В этом примере мы используем пакет nn для реализации нашей полиномиальной модели.
сеть:
# - * - кодировка: utf-8 - * -
импортный фонарик
импортная математика
# Создать тензоры для хранения ввода и вывода.
x = torch.linspace (-мат.3).
p = torch.tensor ([1, 2, 3])
xx = x.unsqueeze (-1) .pow (p)
# В приведенном выше коде x.unsqueeze (-1) имеет форму (2000, 1), а p имеет форму
# (3,), в этом случае будет применяться семантика широковещательной передачи для получения тензора
# формы (2000, 3)
# Используйте пакет nn, чтобы определить нашу модель как последовательность слоев. nn. последовательный
# - это модуль, который содержит другие модули и последовательно применяет их к
# произвести свой вывод. Линейный модуль вычисляет вывод из ввода, используя
# линейная функция и содержит внутренние тензоры для ее веса и смещения.# Слой Flatten сглаживает вывод линейного слоя до одномерного тензора,
# для соответствия форме `y`.
model = torch.nn.Sequential (
torch.nn.Linear (3, 1),
torch.nn.Flatten (0, 1)
)
# Пакет nn также содержит определения популярных функций потерь; в этом
# case мы будем использовать среднеквадратичную ошибку (MSE) в качестве функции потерь.
loss_fn = torch.nn.MSELoss (сокращение = 'сумма')
learning_rate = 1e-6
для t в диапазоне (2000):
# Прямой проход: вычислить предсказанный y, передав x модели. Объекты модуля
# переопределить оператор __call__, чтобы вы могли вызывать их как функции.Когда
# при этом вы передаете модулю тензор входных данных, и он производит
# Тензор выходных данных.
y_pred = модель (xx)
# Потеря вычислений и печати. Мы передаем тензоры, содержащие предсказанное и истинное
# значений y, а функция потерь возвращает тензор, содержащий
# потеря.
loss = loss_fn (y_pred, y)
если t% 100 == 99:
print (t, loss.item ())
# Обнулить градиенты перед выполнением обратного прохода.
model.zero_grad ()
# Обратный проход: вычислить градиент потерь относительно всего обучаемого
# параметры модели.Внутри сохраняются параметры каждого модуля.
# в тензорах с require_grad = True, поэтому этот вызов будет вычислять градиенты для
# все обучаемые параметры в модели.
loss.backward ()
# Обновить веса с помощью градиентного спуска. Каждый параметр является тензором, поэтому
# мы можем получить доступ к его градиентам, как и раньше.
с torch.no_grad ():
для параметра в model.parameters ():
param - = скорость_обучения * param.grad
# Вы можете получить доступ к первому уровню `модели` как доступ к первому элементу списка
linear_layer = модель [0]
# Для линейного слоя его параметры сохраняются как `weight` и` bias`.3 ')
PyTorch: optim
До этого момента мы обновляли вес наших моделей вручную.
изменяя тензоры, содержащие обучаемые параметры, с помощью torch.no_grad () .
Это не большая проблема для простых алгоритмов оптимизации, таких как стохастический.
градиентный спуск, но на практике мы часто обучаем нейронные сети, используя больше
сложные оптимизаторы, такие как AdaGrad, RMSProp, Adam и т. д.
Пакет optim в PyTorch абстрагирует идею оптимизации
алгоритм и предоставляет реализации часто используемой оптимизации
алгоритмы.3).
p = torch.tensor ([1, 2, 3])
xx = x.unsqueeze (-1) .pow (p) # Используйте пакет nn, чтобы определить нашу модель и функцию потерь.
model = torch.nn.Sequential (
torch.nn.Linear (3, 1),
torch.nn.Flatten (0, 1)
)
loss_fn = torch.nn.MSELoss (сокращение = 'сумма') # Используйте пакет optim, чтобы определить оптимизатор, который будет обновлять веса
# модель для нас. Здесь мы будем использовать RMSprop; пакет optim содержит много других
# алгоритмы оптимизации. Первый аргумент конструктора RMSprop сообщает
# оптимизатор, тензоры каких он должен обновлять.learning_rate = 1e-3
optimizer = torch.optim.RMSprop (model.parameters (), lr = скорость_обучения)
для t в диапазоне (2000):
# Прямой проход: вычислить предсказанный y, передав x модели.
y_pred = модель (xx) # Потеря вычислений и печати.
loss = loss_fn (y_pred, y)
если t% 100 == 99:
print (t, loss.item ()) # Перед обратным проходом используйте объект оптимизатора для обнуления всех
# градиентов для переменных, которые он будет обновлять (которые можно изучить
# веса модели). Это потому, что по умолчанию градиенты
# накапливается в буферах (т.е.e, не перезаписывается) всякий раз, когда .backward ()
# называется. Обратитесь к документации torch.autograd.backward для получения более подробной информации.
optimizer.zero_grad () # Обратный проход: вычислить градиент потерь относительно модели
# параметры
loss.backward () # Вызов пошаговой функции в оптимизаторе обновляет его
# параметры
optimizer.step () linear_layer = модель [0]
print (f'Result: y = {linear_layer.bias.item ()} + {linear_layer.weight [:, 0] .item ()} x + {linear_layer.weight [:, 1].3 ')
PyTorch: пользовательские модули nn
Иногда может потребоваться указать модели более сложные, чем
последовательность существующих модулей; для этих случаев вы можете определить свой собственный
Модули путем создания подкласса nn.Module и определения форварда , который
получает входные тензоры и производит выходные тензоры, используя другие
модули или другие операции автограда над тензорами.
В этом примере мы реализуем наш полином третьего порядка как настраиваемый модуль. подкласс:
# - * - кодировка: utf-8 - * -
импортный фонарик
импортная математика
класс Polynomial3 (torch.nn.Module):
def __init __ (сам):
"" "
В конструкторе мы создаем четыре параметра и назначаем их как
параметры члена.
"" "
супер () .__ init __ ()
self.a = torch.nn.Parameter (torch.randn (()))
self.b = torch.nn.Parameter (torch.randn (()))
self.c = torch.nn.Parameter (torch.randn (()))
self.d = torch.nn.Parameter (torch.randn (()))
def вперед (self, x):
"" "
В функции forward мы принимаем тензор входных данных и должны возвращать
Тензор выходных данных.3 '
# Создать тензоры для хранения ввода и вывода.
x = torch.linspace (-math.pi, math.pi, 2000)
y = torch.sin (x)
# Создайте нашу модель, создав экземпляр класса, определенного выше
model = Polynomial3 ()
# Создайте нашу функцию потерь и оптимизатор. Вызов model.parameters ()
# в конструкторе SGD будет содержать обучаемые параметры (определенные
# с torch.nn.Parameter), которые являются членами модели.
критерий = torch.nn.MSELoss (сокращение = 'сумма')
optimizer = torch.optim.SGD (model.parameters (), lr = 1e-6)
для t в диапазоне (2000):
# Прямой проход: вычислить предсказанный y, передав x модели
y_pred = модель (x)
# Потеря вычислений и печати
потеря = критерий (y_pred, y)
если t% 100 == 99:
print (t, потеря.элемент())
# Обнулить градиенты, выполнить обратный проход и обновить веса.
optimizer.zero_grad ()
loss.backward ()
optimizer.step ()
print (f'Result: {model.string ()} ')
PyTorch: поток управления + распределение веса
В качестве примера динамических графиков и распределения веса мы реализуем очень странная модель: полином третьего-пятого порядка, который при каждом прямом проходе выбирает случайное число от 3 до 5 и использует это количество заказов, повторно используя одни и те же веса несколько раз для вычисления четвертого и пятого порядка.
Для этой модели мы можем использовать обычное управление потоком Python для реализации цикла, и мы можем реализовать распределение веса, просто повторно используя один и тот же параметр, несколько раз при определении прямого паса.
Мы можем легко реализовать эту модель как подкласс модуля:
# - * - кодировка: utf-8 - * -
случайный импорт
импортный фонарик
импортная математика класс DynamicNet (torch.nn.Module):
def __init __ (сам):
"" "
В конструкторе мы создаем пять параметров и назначаем их как члены."" "
супер () .__ init __ ()
self.a = torch.nn.Parameter (torch.randn (()))
self.b = torch.nn.Parameter (torch.randn (()))
self.c = torch.nn.Parameter (torch.randn (()))
self.d = torch.nn.Parameter (torch.randn (()))
self.e = torch.nn.Parameter (torch.randn (())) def вперед (self, x):
"" "
Для прямого прохода модели мы случайным образом выбираем 4, 5
и повторно используйте параметр e, чтобы вычислить вклад этих заказов. Поскольку каждый прямой проход создает динамический граф вычислений, мы можем использовать обычные
Операторы потока управления Python, такие как циклы или условные операторы, когда
определение прямого прохода модели.Здесь мы также видим, что совершенно безопасно повторно использовать один и тот же параметр во многих
раз при определении вычислительного графа.
"" "
y = self.a + self.b * x + self.c * x ** 2 + self.d * x ** 3
для exp в диапазоне (4, random.randint (4, 6)):
y = y + self.e * x ** ехр
вернуть y строка def (self):
"" "
Как и любой класс в Python, вы также можете определить собственный метод в модулях PyTorch.
"" "
return f'y = {self.a.item ()} + {self.5? ' # Создать тензоры для хранения ввода и вывода.
x = torch.linspace (-math.pi, math.pi, 2000)
y = torch.sin (x) # Создайте нашу модель, создав экземпляр класса, определенного выше
модель = DynamicNet () # Создайте нашу функцию потерь и оптимизатор. Обучение этой странной модели с
# ванильный стохастический градиентный спуск сложен, поэтому мы используем импульс
критерий = torch.nn.MSELoss (сокращение = 'сумма')
optimizer = torch.optim.SGD (model.parameters (), lr = 1e-8, импульс = 0,9)
для t в диапазоне (30000):
# Прямой проход: вычислить предсказанный y, передав x модели
y_pred = модель (x) # Потеря вычислений и печати
потеря = критерий (y_pred, y)
если t% 2000 == 1999:
print (t, потеря.