Работа над ошибками: как сделать выводы и пережить неприятный опыт :: Здоровье :: РБК Стиль
© Lina Kivaka/Pexels
Автор Алиса Таежная
13 июня 2019
Убедить себя в полезности негативного опыта бывает сложно. Еще труднее преодолеть чувство вины, стыда и обиды, прагматично оценить неверный выбор и двинуться дальше. Рассказываем, как успокоить себя, разобрать пережитые неприятности и не повторять ошибок.
Еще труднее преодолеть чувство вины, стыда и обиды, прагматично оценить неверный выбор и двинуться дальше. Рассказываем, как успокоить себя, разобрать пережитые неприятности и не повторять ошибок.
Возьмите на себя ответственность, а не думайте о вине
Что делать: перестаньте искать правых и виноватых и спокойно признайте, на что могли повлиять.
Одна из главных отравляющих эмоций при осознании ошибок прошлого — это чувство вины, постоянные претензии к себе за неправильно сделанный выбор, которые отравляют ощущение осмысленности прожитого времени. Вы попали на учебу, которая разочаровала? Писали диплом, который не пригодился? Вовремя не выучили язык? Связали свою жизнь с неподходящим человеком? Пострадали от предательства друзей? Вынуждены сталкиваться с последствиями чужих проступков?
Избавиться от вины за неправильный выбор помогает чувство того, что вы в состоянии взять ответственность за свои поступки, и таким образом в вашей жизни всегда будут вещи, которые вы можете контролировать, и те, которые контролировать не получится.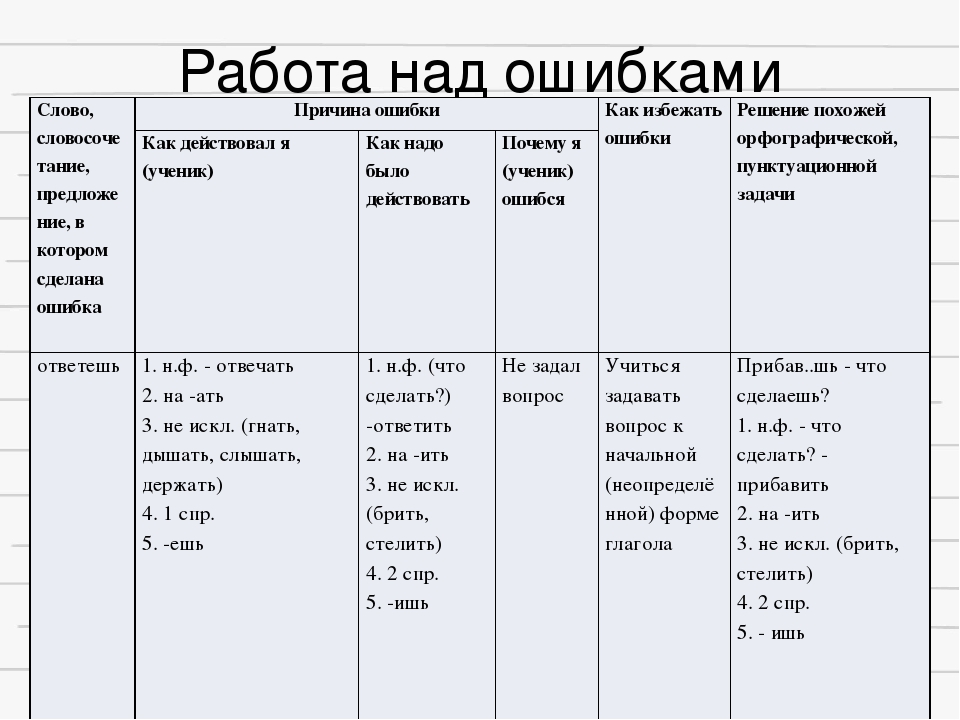
Можно взять ответственность за личные дела, манеру поведения, мысли, эмоции и умение их выражать. А вот брать ответственность за поступки, поведение и эмоции других совершенно не нужно, да и не получится. Скажем, у вас не сложилось с работой. Наверняка в вашей рабочей истории были просчеты, которых можно избежать в будущем, и неидеально сложившиеся отношения. Чувствовать вину за сделанное бессмысленно, а научиться можно многому.
У вас было мало информации или недостаточно навыков планирования? Вы изначально согласились на обязанности, которые не нравились, или вовлекались в конфликты в неподходящий момент? Вспомните, какие ваши действия и мысли действительно доставляли вам дискомфорт, а не пытайтесь задним умом разобраться, на чьей стороне правда или кто в итоге выиграл. Единственное по-настоящему важное сейчас — это ваше будущее, подстраховать и обеспечить которое вы можете, разграничив ваши возможности и влияние других людей и обстоятельств.
© Tess Emily Seymour/Pexels
Обоснуйте прошлый выбор
Что делать: ответьте на вопрос, почему и в каких условиях вы поступили так, а не иначе.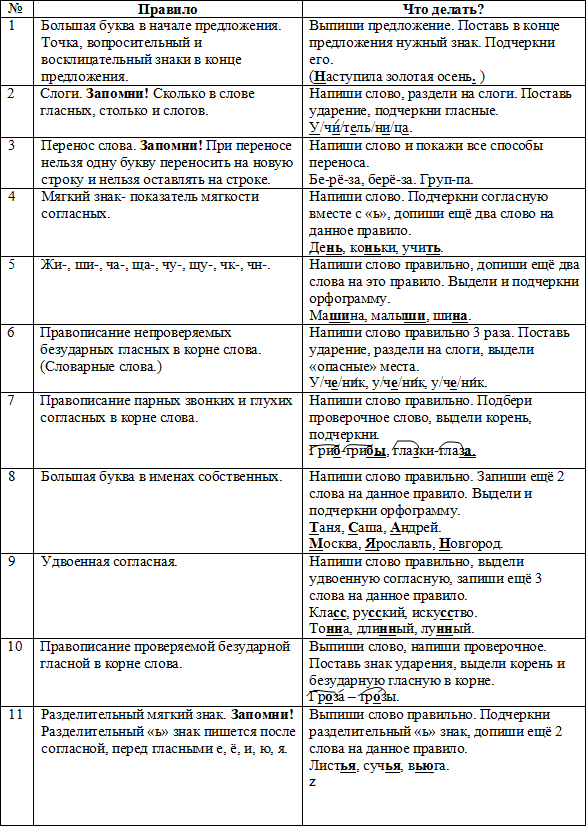
Другое спасение от чувства вины — обосновать уже сделанный выбор, который вызвал много трудных последствий. За каждым выбором всегда лежит положительная мотивация, благодаря которой вы в свое время и пустились в трудное и опасное путешествие, закончившееся не очень благополучно. Переехали в новое место? Скорее всего, в поисках новых возможностей — а значит, в таком поступке много смелости. Пытались построить отношения, несмотря ни на что? За этим стоит искреннее чувство, много надежды и привязанности. Выбрали сложную работу? Из-за потребности вызовов и стремления попробовать новое. Потеряли деньги? Собирались сделать инвестиции. Разошлись с друзьями? Вспомните, почему вы с ними сошлись. Это приближает нас к предыдущему пункту. За каждым сделанным выбором всегда стоит позитивная мотивация, но не все зависит только от нее.
Другие люди могли не выбрать нас, время могло показать, что работа была выбрана неподходящая, а на новом месте оказалось хуже, чем на старом.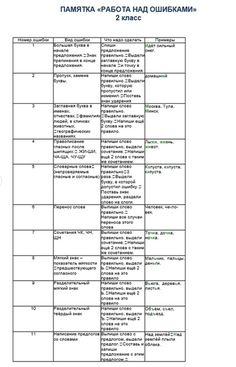 Но ваши надежды, стремление к лучшему и поиски комфорта и удобства всегда стоят за всеми авантюрами, в которые вы включались, и в какой-то ситуации могло просто не повезти или не хватило времени. Не корите себя за моменты, когда вы были ослаблены или выбора не было. Например, никто не выбирает болезнь, личную трагедию, страдания и травмы. Нельзя выбрать оказаться в больнице или стать банкротом, поэтому и думать об этом с чувством вины бессмысленно. Невезение имеет на нашу жизнь такое же влияние, как и удача — и далеко не всегда мы получаем то, чего действительно заслуживаем.
Но ваши надежды, стремление к лучшему и поиски комфорта и удобства всегда стоят за всеми авантюрами, в которые вы включались, и в какой-то ситуации могло просто не повезти или не хватило времени. Не корите себя за моменты, когда вы были ослаблены или выбора не было. Например, никто не выбирает болезнь, личную трагедию, страдания и травмы. Нельзя выбрать оказаться в больнице или стать банкротом, поэтому и думать об этом с чувством вины бессмысленно. Невезение имеет на нашу жизнь такое же влияние, как и удача — и далеко не всегда мы получаем то, чего действительно заслуживаем.
Найдите возможные альтернативы
Что делать: подумайте, какой другой выбор у вас был, почему вы его не сделали и что мешает сделать его сейчас.
Стандартный ход мысли потерпевшего — думать задним умом. Это может быть очень травмирующий процесс, если постоянно концентрироваться на негативном итоге. Важно помнить, что многие прошлые возможности от нас никуда не исчезли, а после ухода из нашей жизни каких-то людей или обязанностей образовалось место для чего-то нового.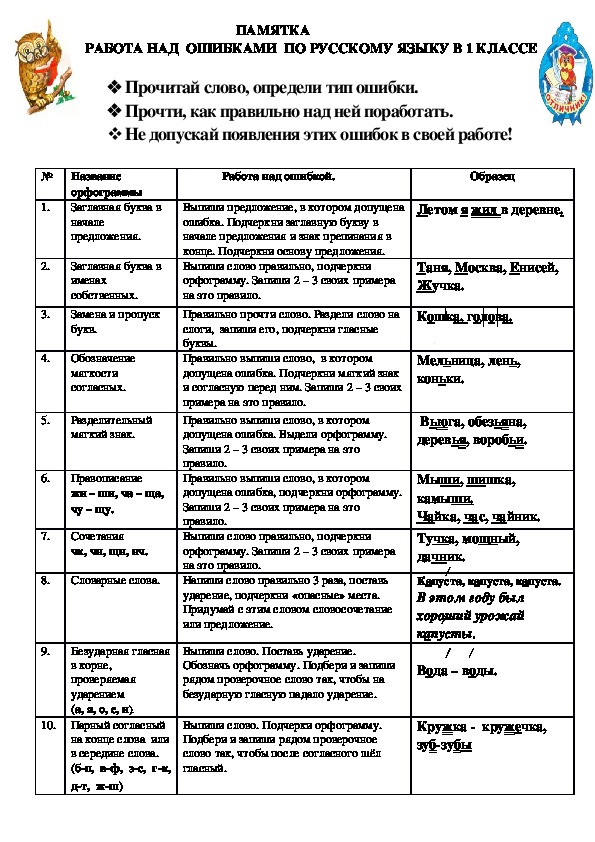
Например, у вас был выбор карьерного пути — и теперь вы оказались в тупике. Вспомните, из чего вы выбирали. Можете ли вы сделать выбор снова, но с другим результатом? Привел ли ошибочный выбор к новым знакомствам, важным навыкам, ощутимым положительным результатам?
Вы учились не тому. Можно ли сейчас переучиться, записаться на дополнительные курсы, поменять специальность, дополнить работу доставляющим радость хобби? Из-за перегрузки вы потеряли связь с друзьями. Хотите ли вы восстановить с ними отношения? Или завести новых друзей, чтобы поддерживать их иначе? Ваше расставание лишило вас веры в хороший исход в отношениях. Какие люди вам нравились? Что вас всегда привлекало, а что настораживало? Что категорически не устраивало в этих отношениях? Как изменились ваши приоритеты тогда и сейчас? Вы запустили здоровье. Какие привычки и лечение нужны, чтобы восстановиться? Можно ли изменить образ жизни так, чтобы чувствовать себя лучше? Можно ли перестроить расписание так, чтобы здоровье было приоритетом? Альтернативы можно подыскать не только в прошлом — куда важнее сделать это в настоящем.
© fotografierende/Pexels
Зафиксируйте важные выводы и используйте их в терапии
Что сделать: запишите то, что вы окончательно уяснили для себя из негативного опыта. Если есть терапевт или психолог, обсудите с ним результаты.
Иногда, пережив что-то тяжелое, мы возвращаемся в прошлое с сожалением — ностальгия и привычка помнить о людях и событиях хорошее могут сыграть дурную шутку: вы забудете, почему принесший боль опыт лучше больше не повторять.
Для того чтобы иметь какую-то отправную точку в самоанализе, запишите случившееся и время от времени возвращайтесь к записанному в момент сомнений. Самым удобным методом принятия решений многими специалистами считается квадрат Декарта, где вместо абстрактных или обтекаемых «за» и «против» мы можем понять, на какие условия полагались, отметая одни опции и выбирая другие.
Неслучившееся — результат ошибок, стечение обстоятельств и не ваш выбор? Какие выводы вы сделали от этих несовпадений? Очень часто провал на работе показывает, что какая-то область или график нам не подходят, мы недооценили влияние коллектива или количество занятости. Ошибка в специализации обнаруживает собственные стремления и таланты. Несложившиеся отношения доказывают, что для нас по-настоящему важно в любви и привязанности. Принципиально зафиксировать ваши выводы (даже временные) и, если есть возможность, обсудить ситуацию с психологом или терапевтом, когда самостоятельные решения вызывают у вас затруднения. В любом случае вербализация постоянно крутящихся в голове мыслей, во-первых, расслабит и переключит внимание (рефлексия будет выплеснута), а во-вторых, зафиксирует ваши решения, чтобы при будущих поступках вы могли увидеть наглядно ваш актуальный ход мыслей и сконцентрированный опыт.
Памятка . Работа над ошибками
Работа над ошибками по русскому языку
Работа над ошибками – один из обязательных видов деятельности ученика. Качественная работа по исправлению ошибок постепенно помогает приблизиться к грамотному выполнению задания. Так как чаще всего работу над исправлением ошибок ученики выполняют дома, то надеемся, что эти материалы будут для вас полезными.
Способы исправления учителем ошибок
в письменных работах учащихся
Исправления, сделанные учителем в тетради, должны обязывать учащихся к определенной работе над ошибками, которую нужно контролировать. Сами по себе, без последующей работы, исправления учителя не способствуют устранению орфографических ошибок. Учителя начальной школы используют различные способы исправления орфографических ошибок, что не только позволяет учитывать индивидуальные особенности учащихся, но и способствует правильному выбору способа исправления ошибки учеником.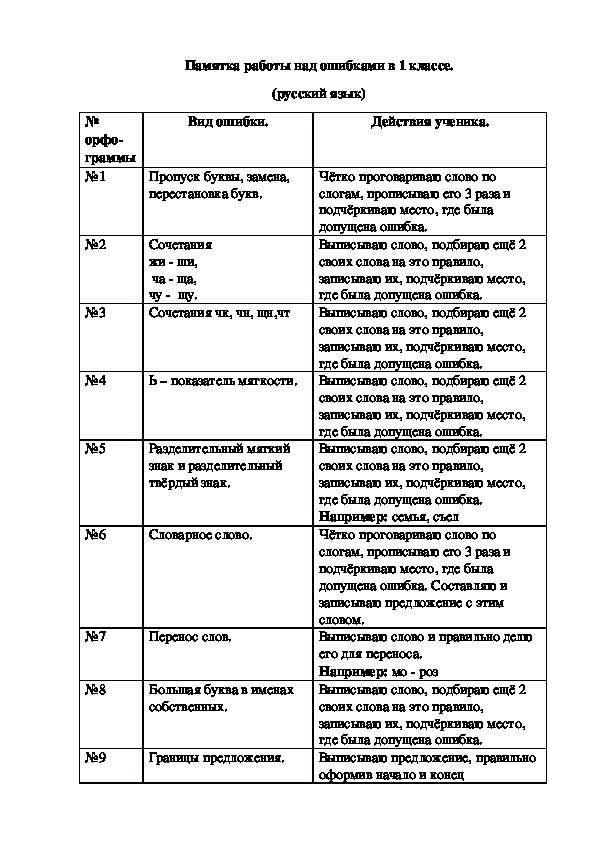 После того как ошибка зафиксирована учителем, ученик должен выполнить работу над ошибками.
После того как ошибка зафиксирована учителем, ученик должен выполнить работу над ошибками.
1. Обозначение на полях условным знаком (/) строчки, в которой находится ошибка.
2. Подчеркивание слова, в котором находится ошибка, и обозначение ошибки на полях условным знаком.
3. Подчеркивание ошибки в слове и обозначение на полях условным знаком (/).
4. 3ачеркивание ошибки, надписывание правильного варианта, указание на полях номера орфограммы, на которую допущена ошибка.
5. Зачеркивание ошибки, надписывание правильного варианта, указание на полях морфемы, в которой находится ошибка.
Например:
6. Зачеркивание ошибки, надписывание правильного варианта, указание на полях способа исправления ошибки.
Условные обозначения орфографических,
пунктуационных и речевых ошибок
/ – орфографическая ошибка.
V – пунктуационная ошибка.
W – логопедическая ошибка.
Ф – фактическая ошибка. (К лесным защитникам относятся разные гусеницы, муравьи.)
Z – красная строка (нет отступа).
Г – нарушение границы предложения. (Кот фыркнул. И убежал под диван.)
V – пропуск слова, предложения.
1, 2, 3 – нарушение порядка слов в предложении.
1 3 4 2
(Стакан стоял на столе с водой.)
Н – речевой недочет (неудачный выбор слова).
– нарушение последовательности изложения.
П – повтор одного и того же слова (неумение подбирать синонимы).
Работа над ошибками (1 класс)
СЛОВАРНОЕ СЛОВО.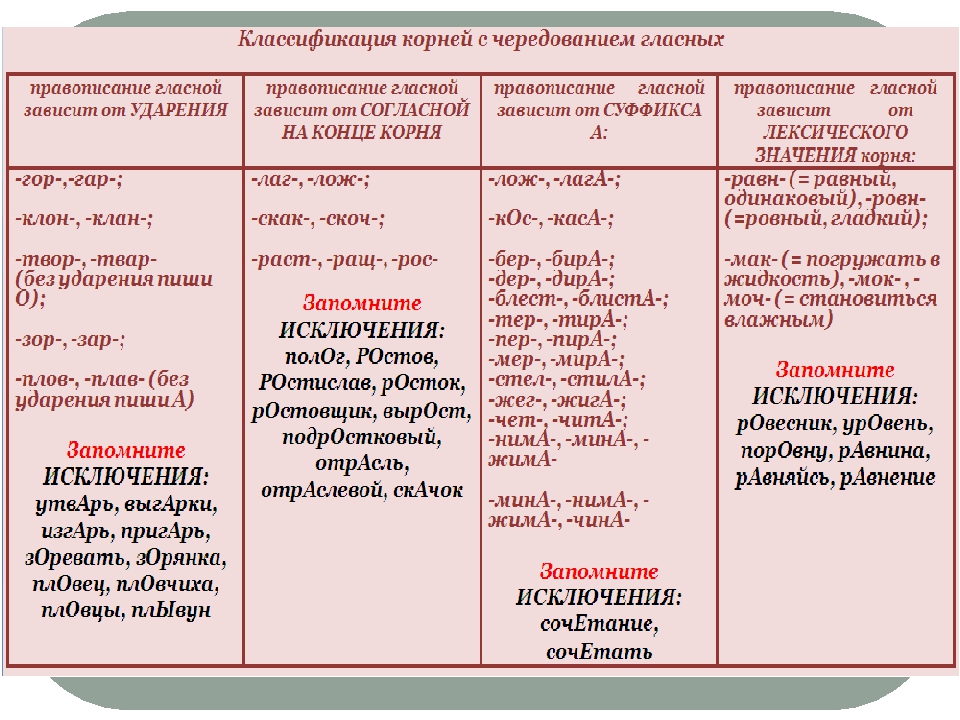
Выпишите правильно слово один раз, подчеркните (выделите) букву, поставьте ударение.
ГЛАСНЫЕ ПОСЛЕ ШИПЯЩИХ – ЖИ, ШИ, ЧА, ЩА, ЧУ, ЩУ.
Выпишите слово без ошибок один раз, подчеркните гласную (сочетание). Придумайте и запишите еще два слова с таким же сочетанием.
СОЧЕТАНИЯ ЧК, ЧН.
Выпишите слово без ошибок один раз, подчеркните (выделите) сочетание. Придумайте и запишите еще два слова с этим сочетанием.
ИМЕНА СОБСТВЕННЫЕ (имена, фамилии, названия городов
и т. д.).
Выпишите правильно имя собственное, подчеркните (выделите) заглавную букву. Придумайте и запишите два слова на это правило.
БЕЗУДАРНЫЕ ГЛАСНЫЕ.
Выпишите правильно слово, выделите безударную гласную. Проверьте гласную ударением: подберите и запишите проверочное слово. Обозначьте ударение в этих словах. Придумайте и запишите два слова на это правило.
Придумайте и запишите два слова на это правило.
ЗВОНКИЕ И ГЛУХИЕ СОГЛАСНЫЕ (на конце и в середине слова).
Выпишите слово правильно, рядом – проверочное. Придумайте и запишите два слова на это правило.
НЕПРОИЗНОСИМЫЕ СОГЛАСНЫЕ.
Выпишите слово, выделите букву. Если написание можно проверить, подберите и напишите проверочное слово. Придумайте и запишите два слова на это правило.
УДВОЕННЫЕ СОГЛАСНЫЕ.
Выпишите правильно слово, подчеркните (выделите) двойные согласные. Придумайте и запишите два слова на это правило.
ПЕРЕНОС СЛОВ.
Выпишите слово, разделите его для переноса всеми возможными способами.
РАЗДЕЛИТЕЛЬНЫЙ МЯГКИЙ ЗНАК. МЯГКИЙ ЗНАК – ПОКАЗАТЕЛЬ МЯГКОСТИ.
Выпишите слово, подчеркните (выделите) Ь. Обозначьте графически. Напишите два слова с разделительным Ь или Ь – показателем мягкости.
ПРОПУСК И ЗАМЕНА БУКВ, ИСКАЖЕНИЕ СЛОВА.
Выпишите слово правильно, разделите на слоги, подчеркните (выделите) гласные.
ПРЕДЛОЖЕНИЕ.
Напишите предложение правильно, подчеркните нужное написание (большая буква в начале, точка, ?, ! – в конце, раздельное написание слов, пропуск слов и т. д.).
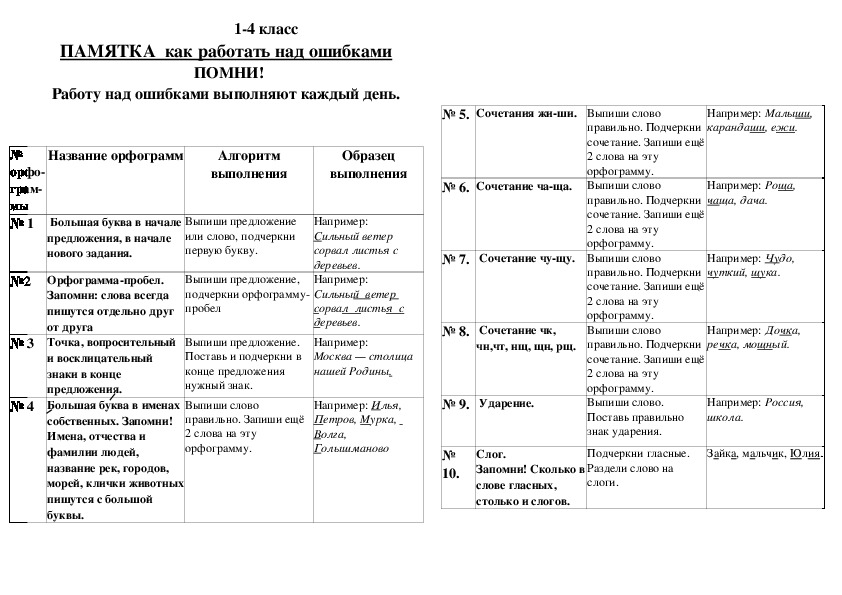
Работа над ошибками (2–4 классы)
I. Последовательность работы над орфограммами.
1. С новой строчки выпишите слово или словосочетание, в котором допущена ошибка.
2. Подчеркните (выделите) орфограмму.
3. Определите, в какой части слова (или части речи) допущена ошибка.
4. Выясните, на какое правило допущена ошибка (определите характер орфограммы), повторите это правило.
5. Выполните указания правила. Графически обозначьте орфограмму.
6. Выберите ошибки на то же правило и исправьте их.
7. Приведите один-два примера на это правило.
Характер орфограммы(правило)
Как исправить
Пример
1
2
3
4
1
Заглавная буква в начале предложения.
Предложение – это группа слов, которые
выражают законченную мысль
Запишите правильно предложение. Подчеркните заглавную букву
Мальчики гуляли во дворе
2
Заглавная буква в именах собственных.
Имена, фамилии, отчества людей, клички животных, географические названия, названия улиц, площадей и др. пишутся с заглавной буквы
Напишите слово правильно.
Выделите заглавную букву.
Объясните написание по образцу
Иван – имя
Петрович – отч.
Сидоров – фам.
Грузия – геогр. н.
река Нева – геогр. н. пес Филька – кл.
3
Перенос слов.
Запомните!
1. Переносите слова по слогам.
2. Нельзя оставлять или переносить одну букву. (Язык – переносить НЕЛЬЗЯ!)
3. Нельзя отрывать букву Й, а также Ь, Ъ от предыдущих букв, так как русские слова не могут начинаться буквами Й, Ь, Ъ, Ы
(конь-ки, лей-ка, подъ-езд).
4. При переносе слов с двойными согласными граница переноса проходит между этими согласными (рус-ский).
5. Особого внимания требует перенос на границе приставки и корня. При переносе нельзя отрывать начальную часть корня, не составляющую слога
(при-крыть, про-спать, НО НЕ прик-рыть, прос-пать)
Напишите слово правильно, разделите на слоги.
Подчеркните, выделите гласные буквы.
Напишите все случаи переноса данного слова
про/пус/тил
про-пустил
пропус-тил
4
Если пропустили (кроме непроизносимых), не дописали, переставили букву в слове
Напишите слово правильно. Разделите на слоги. Выделите или подчеркните букву, которую не написали, заменили, переставили
Разделите на слоги. Выделите или подчеркните букву, которую не написали, заменили, переставили
пло/щад/ка
5
Гласные И, А, У после шипящих.
Запомните:
Жи-ши
Ча-ща
Чу-щу
Напишите слово правильно. Выделите цветом сочетание или подчеркните
машина
широкий
чаща
щука
чугун
6
Сочетания ЧК-ЧН, НЧ-НЩ.
Запомните:
ЧК-ЧН
НЧ-НЩ
(пишите без Ь)
Напишите слово правильно, выделите цветом сочетание или подчеркните
банщик
диванчик
одуванчик
Продолжение табл.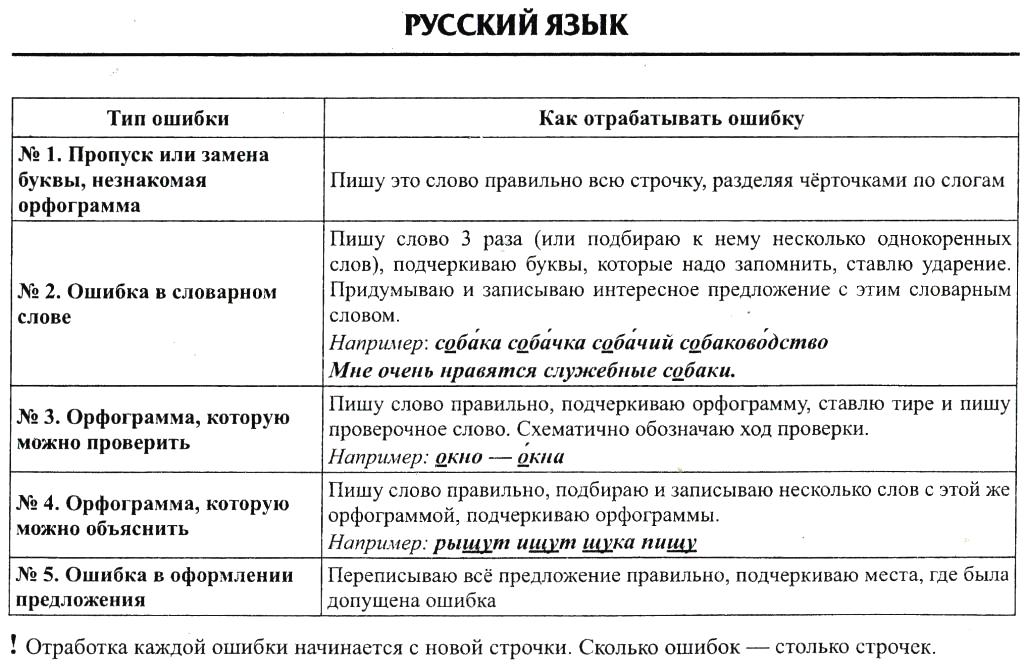
3
4
7
Проверяемые безударные гласные в корне слова (б/г).
Запомните!
Безударные гласные А, Я, И, О, Е можно проверять только в корне.
Для этого нужно изменить слово или
подобрать однокоренное слово так, чтобы на б/г падало ударение
Подберите и запишите проверочное слово, поставьте знак ударения, выделите корень, подчеркните ударную гласную.
Напишите правильно слово с б/г, поставьте знак ударения, выделите корень и б/г в корне
мост – мОсты
красный –
крАсиво
кормит –
кОрмушка
8
Проверяемые согласные в корне слова
(п/с).
Запомните!
Парные звонкие и глу-
Подберите и запишите проверочное слово, выделите ко-рень и подчеркните букву после п/с.
морозы,
морозный – мороЗ
глаза,
глазной – глаЗки
резок – реЗкий
хие согласные б-п, д-т, в-ф, г-к. з-с, ж-ш на конце и в середине слова нужно проверять. Для этого нужно изменить слово или подобрать однокоренное слово так, чтобы после согласного стоял гласный звук (или согласный Н, Л, М, Р)
Напишите правильно слово с п/с. Выделите корень и п/с в корне
9
Непроизносимые согласные в корне слова (н/с): в, д, л, т.
Измените слово или подберите однокоренные слова так, чтобы после согласного стоял гласный или согласный четко звучал.
Запомните!
Букву Т – писать напрасно!
Чудесно – чудеса
Прекрасно – краса
Ужасно – ужасы
Опасно – опасен
Вкусно – вкусы
Интересно – интересы
Подберите и запишите проверочное слово. Выделите корень и подчеркните гласную после н/с.
Выделите корень и подчеркните гласную после н/с.
Напишите правильно слово с н/с. Выделите корень и н/с в корне
звезда
звездочка
звезДный
10
Непроверяемые орфограммы в корне слова (словарные слова).
Непроверяемые гласные и согласные в корне слова ЗАПОМИНАЕМ
Напишите слово правильно. Выделите цветом или подчеркните орфограмму. Подберите два однокоренных слова (или 2 слова
с подобной орфограммой)
мороз
морозный
морозец
(город, топор)
11
Двойные согласные в слове.
Две одинаковые согласные пишутся:
А. В корне слова (их нужно запомнить)
А. Запишите правильно слово. Объясните графически
(выделите корень и двойные согласные в корне)
А.
группа
ванна
Б. Если приставка кончается, а корень начинается с той же согласной
Б. Запишите правильно слово. Объясните графически (выделите приставку и корень, подчеркните двойные согласные)
Б.
рассказ
оттолкнуть
Окончание табл.
В. Если корень кончается, а суффикс начинается с той же согласнойВ. Запишите правильно слово. Объясните графически (выделите корень и суффикс, подчеркните двойные согласные)
В.
ранняя
осенний
Г. В суффиксе (двойные согласные запоминаем)
Г. Запишите правильно слово. Объясните графически (выделите корень и двойные согласные в суффиксе)
Г.
клюквенный
12
Мягкий знак (ь) – показатель мягкости согласных.
Пишется после согласных
на конце слова (конь)
в середине слова между согласными (коньки)
Напишите слово правильно. Выделите ь.
Обозначьте стрелкой или подчеркните согласный, мягкость которого на письме показывает ь
конь
морковь
девять
коньки
мальчик
пальцы
13
Ь — разделительный.
Пишется в корне слова после согласных пред гласными Е, Ё, И, Ю, Я. Показывает, что согласный звук не сливается с гласным
Напишите слово правильно. Выделите ь.
Обозначьте стрелкой или подчеркните согласную и гласную, которые разделяет ь
вьюга
листья
платье
14
Разделительный твердый знак (Ъ).
Запомните!
Пишется после приставок, которые
заканчиваются на согласную, перед
гласными в корне Е, Е, Ю, Я.
согл. Ъ е, е, ю, я
Исключения: объект, субъект, адъютант
Напишите слово правильно.
Выделите приставку и Ъ.
Подчеркните согласную в приставке и гласную в корне, которые разделяет Ъ
съезд
объем
объявление
15
Ь – на конце имен существительных после шипящих.
На конце имен существительных ж. р. в и. п. после шипящих пишется Ь. На конце имен существительных м. р. после шипящих НЕ пишется Ь
Определите род имени существительного. Напишите слово правильно.
Объясните графически
дочь – ж. р.
печь – ж. р.
луч – м. р.
р.
мяч – м. р.
16
Ь — после шипящих во 2-м л. ед. ч. глаголов.
На конце глаголов 2-го л. ед. ч. в форме настоящего и будущего времени пишется Ь
Выпишите глагол. Выделите окончание. Разберите глагол по схеме: часть речи, время, число, лицо
шишешь – гл.,
наст. вр.,
ед. ч., 2л.
решаешь,
пишешь
17
Раздельное написание предлогов с другими словами.
Предлоги со словами пишутся раздельно, так как предлог – это часть речи.
Между предлогом и словом можно поставить другое слово или вопрос.
Перед местоимениями 3 лица после предлога пишите букву Н.
Перед глаголами предлоги не пишутся
Выпишите слово с предлогом. Докажите раздельное написание (между предлогом и словом вставьте другое слово или вопрос)
Сосна росла
у берега.
У (какого?) берега,
у крутого берега.
Ко V мне
С V ними
II. Последовательность работы над пунктуационными ошибками.
1. Выпишите все предложение, в котором была допущена ошибка, подчеркните пунктограмму. Повторите пунктуационное правило.
2. Составьте схему предложения (или подчеркните грамматическую основу).
3. Приведите один-два примера на данное слово.
п/п
Характер орфограммы
(правило)
Как исправить
Пример
1
2
3
4
1
Точка, вопросительный, восклицательный знаки в конце предложения.
Предложение – это слово или группа слов, которые выражают законченную мысль
Выпишите предложение.
Поставьте в конце предложения нужный знак.
Объясните по образцу
Наступило раннее утро.
(повествовательное, невосклицательное)
2
Разбор предложения.
Подлежащее и сказуемое – главные
члены предложения.
Подлежащее обозначает, о ком или о чем говорится в предложении, и отвечает на вопросы кто? что?
Сказуемое обозначает, что говорится о подлежащем, и отвечает на вопрос что делает?
(и др.)
Остальные члены называются второстепенными: дополнение,
определение, обстоятельство
Выпишите предложение. Подчеркните главные члены (основу предложения).
Выпишите из предложения все словосочетания, используя алгоритм
Седые туманы
плывут к облакам.
Туманы (какие?)
седые.
Плывут (куда?)
к облакам
3
Однородные члены предложения – несколько членов предложения (главных или второстепенных), которые отвечают на один и тот же вопрос и зависят от одного и того же слова. Между однородными членами предложения запятая ставится:
Между однородными членами предложения запятая ставится:
1) если между ними нет союзов;
2) если между ними есть союзы А, НО, ДА=НО;
3) если союзы И, ИЛИ повторяются.
Запятая не ставится:
если между ними один раз употребляется союз И, ИЛИ, ДА=И
Выпишите предложение.
Подчеркните однородные члены и слова, от которых они зависят.
Вспомните о знаках препинания между однородными членами. Сделайте схему
Наш народ любит
и бережет свою Родину.
III. Ошибки в разборе слова по составу.
3Состав слова.
Если неправильно разобрано слово по составу – вспомните правила и определения.
Запомните!
Слова, которые имеют общую (одинаковую) часть и сходны (близки) по смыслу называются однокоренными.
Запомните!
В корнях родственных слов пишутся одинаковые гласные. Общая (одинаковая) часть родственных слов называется корнем.
Общая (одинаковая) часть родственных слов называется корнем.
Окончание – изменяемая часть слова, которая служит для связи слов в предложении.
Приставка – это часть слова, которая стоит перед корнем и служит для образования новых слов.
Суффикс – это часть слова, которая стоит после корня и служит для образования новых слов
Напишите слово.
Разберите по составу, пользуясь планом.
ПЛАН
1. Выясните смысл слова.
2. Определите часть речи.
3. Выделите окончание. Докажите (измените слово)
4. Выделите корень.
Докажите (подберите
два родственных слова).
5. Выделите приставку (она стоит перед корнем).
6. Выделите суффикс (он стоит после корня)
Поездка.
Ездить, проезд
Радостный.
Рад, радовался
IV. Ошибки в изложении или сочинении.
3П – повтор слова
Замените повторяющееся слово.
Запишите предложение с новым словом
Ваня увидел собаку и испугался. Ваня закрыл руками лицо и заплакал.
Он закрыл руками лицо и заплакал.
Мальчик закрыл руками лицо и заплакал
Н – неудачное слово или предложение
Замените неудачное слово или предложение.
Запишите исправленное предложение, употребив нужные слова
Холодный осенний ветер вырывал листья и заносил их.
Холодный осенний ветер срывал листья и уносил их
V – пропуск слова или предложения
Подумайте, какое слово или предложение пропущено. Запишите
предложение, впишите в него пропущенное слово (или запишите предложение, которое пропустили)
Жили-были V со старухой.
Жили-были старик со старухой
Г – нет в конце предложения точки или других знаков препинания
Подумайте, какие знаки препинания не поставили. Выпишите предложение. Поставьте в конце предложения нужный знак препинания. Объясните свой выбор
Выпишите предложение. Поставьте в конце предложения нужный знак препинания. Объясните свой выбор
Наступило раннее утро.
(повествовательное,
невосклицательное)
Z – красная строка
Разделите текст на части. Запишите каждую (или соответствующую) часть с красной строки
1, 2, 3… –
неудачный порядок слов в предложении
Прочитайте предложение. Измените порядок слов.
Запишите предложение, правильно расположив слова
Ученики класса нашего спорт любят. Ученики нашего класса любят спорт
Работа над ошибками, 2015 — Фильмы
Мария преподает русский язык и литературу. Ежедневно она помогает детям осваивать сложные правила пунктуации и орфографии. Только вот найти проверочное слово или расставить запятые намного проще, чем разобраться со своей личной жизнью. Давние обиды не позволяют ей двигаться вперед. Девушка живет прошлым, а в сторону будущего даже не смотрит.
Семнадцать лет назад у нее была огромная любовь по имени Олег, вот только парень покинул провинциальный городок, чтобы найти жизнь куда лучше прежней. А с любимой девушкой он даже и не попрощался. Все эти годы, Мария живет с вопросами, на которые не может найти ответы. В чем она провинилась перед Олегом, раз он смог так легко ее оставить. Теперь учитель русского языка живет одна и совершенно не верит мужчинам. Но вдруг Олег решил вернуться, и в сердце Марии вновь затрепетала надежда. Что же будет теперь? Возможна ли любовь сквозь годы? Или же нужно это все-таки забыть?
Что делать, когда судьба преподносит тебе новый шанс? Воспользоваться ним либо же оставить прошлое в прошлом? Кинолента Работа над ошибками Сергея Гиргеля, создателя нашумевшей Каменской, попытается ответить на эти и другие вопросы. История обычной провинциальной женщины, отчаянно желающей любви, придется близкой по духу для многих зрителей. Ведь все хоть раз влюблялись и теряли свою любовь.
Актриса театра и кино Ольга Бурлакова показывает здесь хорошую драматическую игру. Марии, главной героини ленты, действительно хочется верить. Многие женщины смогут увидеть свое отражение во всех ее поступках.
Марии, главной героини ленты, действительно хочется верить. Многие женщины смогут увидеть свое отражение во всех ее поступках.
Мария преподает русский язык и литературу. Ежедневно она помогает детям осваивать сложные правила пунктуации и орфографии. Только вот найти проверочное слово или расставить запятые намного проще, чем разобраться со своей личной жизнью. Давние обиды не позволяют ей двигаться вперед. Девушка живет прошлым, а в сторону будущего даже не смотрит. Семнадцать лет назад у нее была огромная любовь по имен
How it works
Lectoroom — is unique place where you can find online courses from great artists. Watch and learn art wherever you are. Any time! Choosing Lectoroom means you have 24/7 lifetime access to any course you have purchased and access to reviews from artists themselves.
Learning art with us is easy:
- watch videos (?)
- complete tasks
- upload your works (?)
- communicate with artists
- become better!
Choose your course
Search! Try using artists name, a title or use tags like watercolor or illustration:
Enroll to a course
No need to wait! We have set up everything you need to pay and access the course right away. Read the description and then just hit the orange button. The course will appear in your Cabinet on the site.
Read the description and then just hit the orange button. The course will appear in your Cabinet on the site.
We will remind you about course start if is live or has a start date. You will not miss a thing
Add some individuality!
Add your photo, social media links so everyone can communicate with you У нас можно выделиться. Surprise and show your support to others!
Start a course!
Watch videos and share you results. We think that learning process must be smooth and have a step-by-step nature. Next lecture will open right after you have finished the last one.
Upload your work and get a review
Finished your first picture? Completed a task? Upload a photo and get grades and reviews from your mentor.
Get obvious results!
Right after you have finished a course, you will receive a certificate! We also value your feedback so don’t forget to leave a review for us!
Become a pro with us!
Телевизионный фильм «Работа над ошибками» на канале «Русский роман» , Владивосток
Мария — учительница русского языка и литературы. Она учит детей не делать ошибок, однако ей самой предстоит совершить настоящую «работу над ошибками». Личная жизнь Марии не устроена — героиня не может забыть и простить свою первую большую любовь Олега, который уехал из родного города и, как она думает, бросил ее. Груз прошлого не дает ей идти вперед. Но однажды в город возвращается Олег. Кажется, что после семнадцати лет разлуки чувства оживают вновь и что сделанные ошибки можно исправить…
Она учит детей не делать ошибок, однако ей самой предстоит совершить настоящую «работу над ошибками». Личная жизнь Марии не устроена — героиня не может забыть и простить свою первую большую любовь Олега, который уехал из родного города и, как она думает, бросил ее. Груз прошлого не дает ей идти вперед. Но однажды в город возвращается Олег. Кажется, что после семнадцати лет разлуки чувства оживают вновь и что сделанные ошибки можно исправить…
+12
Русский роман
Ошибка в расписанииВторник 07:45
Работа над ошибками
Канал «Русский роман»
В это время была передача:
Ваше сообщение будет рассмотрено в ближайшее время. Спасибо!
Спасибо!
Мария — учительница русского языка и литературы. Она учит детей не делать ошибок, однако ей самой предстоит совершить настоящую «работу над ошибками». Личная жизнь Марии не устроена — героиня не может забыть и простить свою первую большую любовь Олега, который уехал из родного города и, как она думает, бросил ее. Груз прошлого не дает ей идти вперед. Но однажды в город возвращается Олег. Кажется, что после семнадцати лет разлуки чувства оживают вновь и что сделанные ошибки можно исправить…
Продолжительность
1 час 30 минут (90 минут)
Оператор
Владимир Брыляков
В ролях
Вера Полякова, Михаил Дорожкин, Александр Никитин, Владимир Мищанчук, Ольга Бурлакова, Татьяна Гаркуша, Александра Гайдук, Наталья Цуба, Александр Душечкин, Даша Отрошко
Продюсер
Игорь Щербаков, Евгений Арендаревич, Александр Кушаев
Режиссер
Сергей Гиргель
Сценарист
Екатерина Андерсон
Композитор
Игорь Щербаков
Производство
Медиапрофсоюз
Россия
2015
Работа над ошибками
1. Пропуск или замена буквы. Выпиши слово. Подчеркни в нём пропущенную букву.Например: ученик, звонок.
Пропуск или замена буквы. Выпиши слово. Подчеркни в нём пропущенную букву.Например: ученик, звонок.
2.Большая буква в начале предложения. Выпиши предложение правильно. Придумай и напиши ещё одно предложение. Подчеркни заглавную букву.Например: Падают жёлтые листья. Пришла золотая осень.
3.Перенос слова. Раздели слово для переноса.Например: ОСИ – НА.
4.Сочетание чк, чн, чт, нщ, щн. Выпиши слово правильно. Подчеркни орфограмму.*Придумай и запиши ещё 2 слова на эту орфограмму.Например: дочка, речка, мощный.
5.Гласные после шипящих. Выпиши слово правильно. Подчеркни орфограмму.*Придумай и запиши ещё 2 слова на эту орфограмму.Например: малыши, карандаши, роща, туча.
6.Безударная гласная в корне, не проверяемая ударением. Запиши слово правильно 3 раза. Запомни, как оно пишется. Обозначь ударение, подчеркнигласную. Запиши два однокоренных слова.Например: ягода, ягода, ягода, ягодка, ягодный.
7.Безударная гласная в корне, проверяемая ударением.(А, О, И, Е, Я) Выпиши слово. Поставь ударение. Выдели корень. В корне подчеркни безударную гласную одной чертой. Подбери проверочное слово и запиши в скобках. Поставь ударение в проверочном слове. Выдели корень. Подчеркни ударную гласную двумя чертами.Например: сады (сад), молодой (молодость, молоденький).
8.Двойные согласные в слове. Выпиши слово правильно. Раздели слово для переноса. Запиши два однокоренных слова. Подчеркни двойную согласную.Например: группа, груп –па, групповой, подгруппа.
9.Правописание предлога со словами (пробел). Из предложения, в котором допущена ошибка, выпиши слово вместе с предлогом. Докажи, что предлог со словом пишется отдельно. Обозначь орфограмму.Например: к_берегу; к (какому?) берегу, к (крутому?) берегу.
10.Правописание приставки со словами. Выпиши слово. Выдели приставку. Образуй от этого слова однокоренные слова с разными приставками.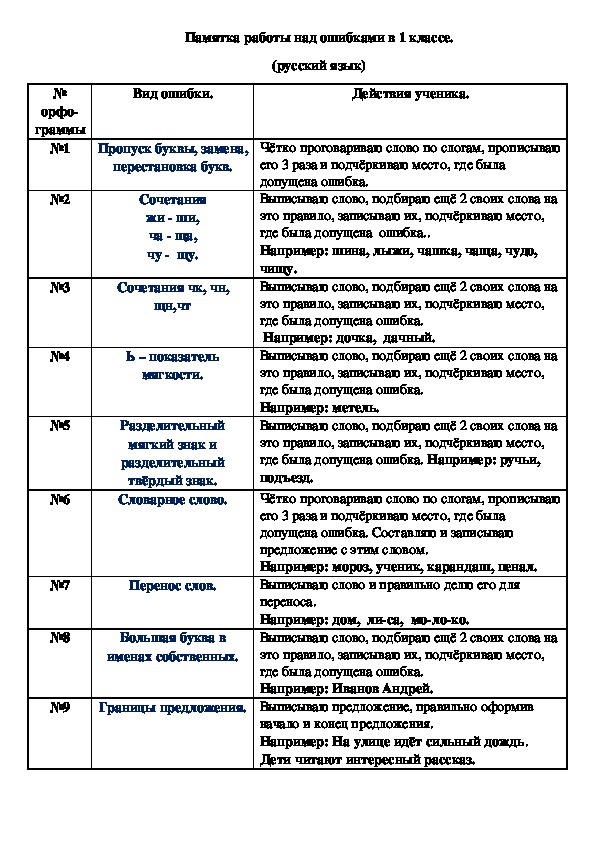 Например: Заехал, уехал, поехал.
Например: Заехал, уехал, поехал.
11.Гласные и согласные в приставках. Выпиши слово правильно. Выдели в нём приставку. Запиши ещё 2 слова с той же приставкой.Например: Полетели, посмотрели, потянули.
12.Большая буква в именах собственных. Выпиши слово правильно. Запиши ещё 2 слова с той же орфограммой.Например: Илья, Петров, Мурка, Волга, Краснодар.
13. Мягкий знак ь, обозначающий мягкость согласных. Подчеркни мягкий знак ь и согласную перед ним.Например: Ель, тень, коньки.
14.Разделительный мягкий знак ь. Выпиши слово правильно. Выдели корень. Подчеркни мягкий знак и гласную букву.Например: Вьюга, листья.
15.Разделительный твёрдый знак ъ. Выпиши слово правильно. Выдели приставку и корень. Подчеркни орфограмму.Например: Съезд, объём.
16.Парные звонкие и глухие согласные. Запиши слово правильно. Проверь согласную. Подчеркни орфограмму.Например: мороз (морозы), ягодка (ягоды).
17. Непроизносимые согласные.Прочитай слово. Подбери к нему несколько однокоренных слов. Выдели корень. Проверь непроизносимую согласную. Обозначь корень. Проверь непроизносимую согласную. Обозначь орфограмму.Делай так: звезда, звёздочка – звёздный
18.Соединительные гласные в сложных словах. Выпиши слово. Выдели корень. Подчеркни гласную. Запиши ещё 1 слово с этой орфограммой.Делай так: водовоз, самолёт.
19. Двойные согласные в слове. Выпиши слово правильно. Раздели слово для переноса. Запиши ещё два однокоренных слова. Подчеркни двойную согласную.Делай так: группа, груп-па, групповой, подгруппа.
20. Мягкий знак ь на конце существительных после шипящих. Выпиши слово правильно. Определи род. Запиши ещё 2 слова с этой орфограммой. Например: Луч ( м.р.), шалаш, товарищ.Ночь (ж.р.), мощь, тишь.
21. Не с глаголом. (орфограмма пробел). Выпиши глагол с не. Запиши ещё 2 слова на это правило. Подчеркни орфограмму.Например: не пришёл, не выучил, не знал.
Подчеркни орфограмму.Например: не пришёл, не выучил, не знал.
22.Однородные члены предложения. Выпиши предложение. Обозначь однородные члены и слово, от которого они зависят. Вспомни, что ты знаешь о знаках препинания и союзах между однородными членами. Выполни схему предложения.Например: Сильный ветер сорвал листья с деревьев, разметал их по дороге.
23. Правописание безударных падежных окончаний имён существительных. Выпиши существительное. Поставь его в начальную форму. Определи тип склонения. Выдели окончание, проверь с помощью слов – помощников. Подбери и запиши свой пример.Делай так: на опушке (на земле, 1 скл.)на полянке (на земле, 1 скл.)
24.Првописание безударных падежных окончаний имён прилагательных. Выпиши прилагательное вместе с существительным, к которому оно относится. Поставь к прилагательному вопрос от существительного. Определи род, число и падеж прилагательного по существительному. Выдели окончание прилагательного. Делай так: к лесу (какому? дальнему – м.р., ед.ч., Д.п.).
Делай так: к лесу (какому? дальнему – м.р., ед.ч., Д.п.).
25. Предлог с местоимением. ( орфограмма – пробел). Выпиши из предложения местоимение с предлогом. Запиши ещё 2 примера на эту орфограмму.Например у преднас, копредмне, спредтобой.
26. Мягкий знак Ь на конце глаголов 2-го лица единственного числа настоящего времени. Выпиши глагол правильно. Запиши ещё 2 глагола с этой орфограммой.Например: пишешь, решаешь, читаешь ( наст.вр., 2 л., ед.ч.)
27.Мягкий знак в неопределённой форме глагола. (-ться, -чь) Выпиши слово правильно. Напиши вопрос. Обозначь орфограмму. Запиши ещё одно слово с этой орфограммой.Например: пытаться (н.ф., что делать?)беречь (что делать?)
28. Правописание безударных личных окончаний глаголов. Выпиши глагол правильно. Поставь ударение. Поставь глагол в начальную (неопределённую) форму. Посмотри на гласную перед -ть. Определи спряжение глагола и гласную, которую следует писать в окончании глагола единственного и множественного числа. Делай так: пишешь- писать, гл, 1 спр., ( -е, -ут, -ют)ставит – ставить, гл., 2 спр., ( -и, -ат, -ят)
Делай так: пишешь- писать, гл, 1 спр., ( -е, -ут, -ют)ставит – ставить, гл., 2 спр., ( -и, -ат, -ят)
29. Сложное предложение. Выпиши правильно. Подчеркни грамматические основы. Нарисуй схему. Подчеркни запятую.Например: Дремлют рыбы под водой, почивает сом седой.
30. Предложение с прямой речью. Запиши правильно. Составь схему. Подчеркни знаки препинания.
Работа над ошибками — продуктивный EPIC FAIL
Эксперты
Проблемы / ситуации применения
Если в компании вы хотите построить единую систему Управления знаниями и хотите, чтобы сотрудники знакомились и применяли успешные практики и способы решения сложных рабочих ситуаций, основываясь на опыте своих коллег
Если вы хотите поменять отношение к ошибкам — сделать их предметом обучения и нового ценного опыта
- увидеть нетипичное в однотипных ситуациях, видеть потенциал в, казалось бы, стандартных ситуациях
- развивать гибкость мышления сотрудников
- повысить открытость вызовам у сотрудников, способствовать тому, чтобы сотрудники не боялись решать сложные задачи
- видеть поведение, навыки и умения коллег, которые способствуют успеху
Если вы хотите увеличить экспертный потенциал компании:
- передачи знаний и навыков более опытных коллег новым сотрудникам
- повышения уровня значимости вклада экспертов и опытных коллег, его признания.

Целевая аудитория
Команда заказчика, которая будет «культивировать» в компании методологию и технологические стандарты модели «База извлеченных уроков», руководители всех уровней
Цель и задачи работы
«Запустить» в компании новую практику повседневного менеджмента, создающую у сотрудников высокую мотивацию и внимание к извлечению ценного опыта из ошибок и прецедентов, разворачивающихся в опыте реальной деятельности
Практика построена на методике «внутренней модерации» как корпоративного навыка.
Проектирует факторы безопасной корпоративной среды для максимального использования экспертного потенциала компании.
Возможные результаты
- Стандарт работы компании «Технология извлечения уроков»
- Формат Базы извлеченных уроков
- Рекомендации по синхронизации этого процесса с процессами производства и другими сервисными функциями
Основные блоки программы и форматы работы
- Работа над ошибками: зачем и в каких ситуациях она нужна компаниям
- Практические примеры: тренд в жизни современных компаний
- Кочему возникает новая философия отношения к ошибкам?
- Как это делают другие и какие результаты можно получить?
- Основные принципы организации безопасной и продуктивной работы по анализу сбоев и ошибок в работе: технологии
- Модельное действие: работа с трудным кейсом Основные риски внедрения и практикования
- Разработка корпоративных прототипов
- Технологии внедрения
- Проектные действия для изменение культуры организации с помощью формата «Работа над ошибками»: в какой компании вы захотите жить и работать
Обязателен предварительный этап подготовки
Разработка кейса для группового обсуждения на основе проблемного анализа — глубинное интервью с ключевыми стейкхолдерами ситуации
Коды исправления ошибок | Блестящая вики по математике и науке
Более эффективная схема кодирования — это код Хэмминга , который аналогичен фонетическому алфавиту из начального раздела. В коде Хэмминга каждая возможная строка сообщения кодируется как определенное двоичное число, причем набор чисел специально выбран так, чтобы все они в некотором смысле существенно различались; Другими словами, каждая пара закодированных сообщений в некоторой степени существенно отличается.
В коде Хэмминга каждая возможная строка сообщения кодируется как определенное двоичное число, причем набор чисел специально выбран так, чтобы все они в некотором смысле существенно различались; Другими словами, каждая пара закодированных сообщений в некоторой степени существенно отличается.
Эта мера составляет Расстояние Хэмминга .Расстояние Хэмминга между двумя числами — это количество разрядов, в которых они различаются. Например, 1101010 и 1111000 — расстояние Хэмминга 2:
11 0 10 1 0
11 1 10 0 0
Ключевым моментом здесь является то, что если какая-либо пара кодировок находится достаточно далеко друг от друга с точки зрения расстояния Хэмминга, ошибки могут быть обнаружены и исправлены, видя, какое из кодовых слов является наиболее близким к переданному сообщению. Например, рассмотрим кодировку
| Letter | Кодировка |
| A | 000 |
| B | 011 |
| C | 101 |
| D | 110 |
В этом кодировании минимальное расстояние Хэмминга между кодировками равно 2, что означает, что могут быть обнаружены однобитовые ошибки — i. е. если во время передачи письма меняется один бит, можно определить, что была сделана ошибка. Однако невозможно определить, каким было исходное сообщение; например, переданное сообщение «010» могло быть однобитовой ошибкой, возникшей в результате отправки «A», «B» или «D».
е. если во время передачи письма меняется один бит, можно определить, что была сделана ошибка. Однако невозможно определить, каким было исходное сообщение; например, переданное сообщение «010» могло быть однобитовой ошибкой, возникшей в результате отправки «A», «B» или «D».
Однако в этой кодировке:
минимальное расстояние Хэмминга между кодировками равно 3, что означает, что однобитовые ошибки могут быть исправлены, а двухбитовые ошибки обнаружены. Это код (3,1) из предыдущего раздела.
Вообще говоря, кодирование может обнаружить kkk-битовых ошибок, если минимальное расстояние Хэмминга составляет не менее k + 1k + 1k + 1, и исправить kkk-битовых ошибок, если минимальное расстояние Хэмминга составляет не менее 2k + 12k + 12к + 1.
Отправьте свой ответ
Известно, что зашумленный канал переворачивает биты с низкой частотой (поэтому можно с уверенностью предположить, что двухбитовых ошибок не будет). Алиса построила следующую частичную кодировку:
Алиса построила следующую частичную кодировку:
| Letter | Кодировка |
| A | 00000 |
| B | 00111 |
| C | 11001 |
| D | ????? |
какое значение должно кодировать Алисе D, чтобы добиться однобитовой коррекции?
КодыХэмминга используют эту идею в сочетании с идеей битов четности и позволяют битам четности перекрываться.n2n — это сумма всех битов (взятых по модулю 2), в позициях которых nnnt младший бит установлен в 1. Например, бит четности в 2 представляет собой сумму битов в позициях 3 = 112,6 = 1102,7 = 1112,10 = 10102,11 = 10112,… 3 = 11_2, 6 = 110_2, 7 = 111_2, 10 = 1010_2, 11 = 1011_2, \ ldots3 = 112, 6 = 1102, 7 = 1112, 10 = 10102 , 11 = 10112,…, поскольку у всех этих позиций второй крайний правый бит установлен на 1.
 nn-1} 22n-n-1 различных элементов алфавита могут быть кодированы с использованием всего nnn битов четности.Это значительное улучшение кодов с повторением, когда n> 2n> 2n> 2; например, кодирование, при котором для каждого слова требуется 4 бита информации (таким образом, может быть закодировано до 16 кодовых слов), может передаваться с 3 битами четности, всего 7 бит, вместо 4⋅3 = 124 \ cdot 3 = 124 ⋅3 = 12 бит из схемы повторения в предыдущем разделе. Поскольку он может исправлять однобитовые ошибки и обнаруживать двухбитовые ошибки, это делает коды Хэмминга намного более эффективными, чем коды с повторением, при достижении той же цели. Столбец с характеристиками
nn-1} 22n-n-1 различных элементов алфавита могут быть кодированы с использованием всего nnn битов четности.Это значительное улучшение кодов с повторением, когда n> 2n> 2n> 2; например, кодирование, при котором для каждого слова требуется 4 бита информации (таким образом, может быть закодировано до 16 кодовых слов), может передаваться с 3 битами четности, всего 7 бит, вместо 4⋅3 = 124 \ cdot 3 = 124 ⋅3 = 12 бит из схемы повторения в предыдущем разделе. Поскольку он может исправлять однобитовые ошибки и обнаруживать двухбитовые ошибки, это делает коды Хэмминга намного более эффективными, чем коды с повторением, при достижении той же цели. Столбец с характеристикамииз AMS
Цифровая революция (Часть III) — Коды коррекции ошибок
6. Технологии исправления ошибок
Основной принцип применения цифровых технологий — разбить изображение или звук на мелкие части и использовать двоичную строку для представления каждой из этих маленьких частей. Двоичные строки часто выбираются для достижения некоторой дополнительной цели, например, для сжатия задействованной информации или для исправления ошибок, которые могут быть вызваны шумом, когда информация пересылается по зашумленному каналу.
Двоичные строки часто выбираются для достижения некоторой дополнительной цели, например, для сжатия задействованной информации или для исправления ошибок, которые могут быть вызваны шумом, когда информация пересылается по зашумленному каналу.
Например, пиксели (элементы изображения) на изображении ниже могут быть отправлены по каналу путем кодирования белого пикселя с помощью 000000, черного пикселя с помощью 111111 и серого пикселя с помощью 000111. Если получатель знает размер изображения , в этом примере 7×7, и что пиксели отправляются строка за строкой в порядке увеличения номера столбца, тогда изображение может быть точно декодировано, если в процессе передачи не возникает слишком много ошибок.
Расстояние Хэмминга между любой парой кодовых слов составляет не менее 3, поэтому, если при передаче любого кодового слова допущено не более одной ошибки, полученные кодовые слова могут быть проверены, и если ошибки произошли, их можно исправить так, чтобы исходные кодовые слова изображение можно реконструировать. Используя таблицу в предыдущем разделе, можно отправить изображение с 8 уровнями серого и по-прежнему использовать кодовые слова длиной 6, имея возможность исправить до одной ошибки на каждое кодовое слово. Если нужно использовать 16 уровней серого, можно использовать код, основанный на плоскости Фано (код Хэмминга), который исправит до одной ошибки на каждое кодовое слово.
Используя таблицу в предыдущем разделе, можно отправить изображение с 8 уровнями серого и по-прежнему использовать кодовые слова длиной 6, имея возможность исправить до одной ошибки на каждое кодовое слово. Если нужно использовать 16 уровней серого, можно использовать код, основанный на плоскости Фано (код Хэмминга), который исправит до одной ошибки на каждое кодовое слово.
Среди самых первых пользователей технологий исправления ошибок зарождающаяся компьютерная промышленность и телефонная промышленность. Например, данные часто перемещаются внутри компьютера.Чтобы предотвратить ошибки, возникающие в некоторых из этих ситуаций, системы памяти компьютеров используют коды Хэмминга для предотвращения ошибок. С рождением космической программы НАСА (нынешнее название) стало основным пользователем и разработчиком технологий кода исправления ошибок. Полезные нагрузки на ранних ракетах были ограничены, потому что подъемная сила ракет была не такой большой. Полезные нагрузки были уменьшены в размерах, и все усилия были направлены на то, чтобы получить максимальное количество «функций» при наименьшем весе. Радиоприемники (и передатчики микроволн), которые использовались для передачи информации обратно на Землю, имели относительно низкую мощность, а это означало, что принимаемые сигналы, когда они подвергались шуму, сопровождающему радиопередачи, часто были не такими сильными, как хотелось бы. .Чтобы помочь преодолеть эту реальность, информация была закодирована с использованием кода исправления ошибок, чтобы повысить точность восстановления отправленного сигнала.
Радиоприемники (и передатчики микроволн), которые использовались для передачи информации обратно на Землю, имели относительно низкую мощность, а это означало, что принимаемые сигналы, когда они подвергались шуму, сопровождающему радиопередачи, часто были не такими сильными, как хотелось бы. .Чтобы помочь преодолеть эту реальность, информация была закодирована с использованием кода исправления ошибок, чтобы повысить точность восстановления отправленного сигнала.
Миссия космического корабля «Маринер» успешно сфотографировала (без цвета) Марс в 1965 году. Размер изображения составлял 200×200 пикселей, каждому пикселю был назначен один из 64 уровней яркости (шесть бит). Поскольку данные передавались со скоростью около 8 бит в секунду (!), Передача одного изображения занимала около 8 часов. К тому времени, когда Mariner 9 вышел на орбиту Марса в 1972 году, были получены гораздо лучшие снимки.Это произошло потому, что космический корабль использовал код Рида-Мюллера, имеющий 6 информационных битов и 26 дополнительных битов для исправления ошибок (кодовые слова были длиной 32 бита). Хотя скорость передачи сейчас составляла примерно 16000 бит в секунду, отдельные изображения были больше, и поэтому камеры получали около 100000 бит в секунду. Это означало, что изображения были сохранены для передачи. К тому времени, когда «Викинг» приземлился на Марсе в 1976 году, технология была усовершенствована и позволяла получать цветные изображения.Первым подходом к этому было получение отдельных изображений одного и того же места с использованием фильтров трех разных цветов. Отдельные черно-белые изображения, полученные через каждый фильтр, были переданы, а затем цветное изображение восстановлено из информации в трех черно-белых изображениях.
Хотя скорость передачи сейчас составляла примерно 16000 бит в секунду, отдельные изображения были больше, и поэтому камеры получали около 100000 бит в секунду. Это означало, что изображения были сохранены для передачи. К тому времени, когда «Викинг» приземлился на Марсе в 1976 году, технология была усовершенствована и позволяла получать цветные изображения.Первым подходом к этому было получение отдельных изображений одного и того же места с использованием фильтров трех разных цветов. Отдельные черно-белые изображения, полученные через каждый фильтр, были переданы, а затем цветное изображение восстановлено из информации в трех черно-белых изображениях.
НАСА использовало множество различных кодов исправления ошибок. Для миссий с 1969 по 1977 год космический корабль Mariner использовал код Рида-Мюллера. Шум, которому подвергались эти космические аппараты, хорошо аппроксимировался «кривой колокола» (нормальное распределение), поэтому коды Рида-Мюллера хорошо подходили для этой ситуации. Код Голея использовался при полете «Вояджера 2» к Юпитеру и Сатурну. Код Рида-Соломона также использовался в миссии «Вояджер». НАСА, однако, также использовало сверточные коды для некоторых своих работ. Различные виды миссий, которые выполняет НАСА, указывают на проблему в попытке получить универсальную систему исправления ошибок. Для миссий, близких к Земле, характер «шума», с которым приходится сталкиваться, отличается от шума космического корабля, направляющегося к внешним планетам. В частности, если передатчик на космическом корабле, находящемся вдали от Земли, работает с малой мощностью, проблема с контролем шума становится больше по мере удаления от Земли.
Код Голея использовался при полете «Вояджера 2» к Юпитеру и Сатурну. Код Рида-Соломона также использовался в миссии «Вояджер». НАСА, однако, также использовало сверточные коды для некоторых своих работ. Различные виды миссий, которые выполняет НАСА, указывают на проблему в попытке получить универсальную систему исправления ошибок. Для миссий, близких к Земле, характер «шума», с которым приходится сталкиваться, отличается от шума космического корабля, направляющегося к внешним планетам. В частности, если передатчик на космическом корабле, находящемся вдали от Земли, работает с малой мощностью, проблема с контролем шума становится больше по мере удаления от Земли.
Компакт-диски — это пример технологии, которая быстро меняет наш образ жизни. Есть аудио компакт-диски и те, которые используются совместно с компьютерами. Хотя некоторые из систем, используемых в этих технологиях, являются частными, известно, что коды Рида-Соломона используются для некоторых компакт-дисков.
Существуют также коды с исправлением ошибок, которые не используют идею отдельных кодовых слов одинаковой длины, где кодовое слово имеет информационные символы и некоторые другие символы, присутствующие для возможности исправления ошибок. Например, сверточные коды можно рассматривать как отправку информации в виде потока символов, где «контрольные символы» вводятся в поток, отправляемый время от времени. Вывод кодировщика сообщения, разделенного на k-кортежи, зависит не только от текущего k-кортежа, который обрабатывается, но также и от некоторых k-кортежей предыдущего сообщения. Выходные данные частей длиннее входных частей, чтобы обеспечить возможность исправления ошибок. Некоторые из этих кодов являются турбокодами.
Например, сверточные коды можно рассматривать как отправку информации в виде потока символов, где «контрольные символы» вводятся в поток, отправляемый время от времени. Вывод кодировщика сообщения, разделенного на k-кортежи, зависит не только от текущего k-кортежа, который обрабатывается, но также и от некоторых k-кортежей предыдущего сообщения. Выходные данные частей длиннее входных частей, чтобы обеспечить возможность исправления ошибок. Некоторые из этих кодов являются турбокодами.
Зарождающаяся компьютерная промышленность была одним из первых пользователей кодов и технологий исправления ошибок.Еще одно важное применение кодов исправления ошибок относится к модемам, устройствам, которые позволяют компьютерам принимать и передавать данные с помощью телефонных линий или оптоволоконного кабеля. Системы исправления ошибок необходимы для систем спутниковой связи; в этой области задействовано много патентов. Эти технологии включают DARS (услуги цифрового аудиорадиосигнала) и SDARS (услуги цифрового спутникового радиовещания). Другие технологии, использующие системы исправления ошибок, — это факсы и HDTV (телевидение высокой четкости).Нет никаких сомнений в том, что использование технологий исправления ошибок будет способствовать дальнейшему развитию цифровой революции.
- Введение
- Основные идеи
- Концепция канала
- Коды и геометрия
- Теория и практика кодов
- Технологии исправления ошибок
- Список литературы
Код исправления ошибок — обзор
Графические модели широко используются для представления класса кодов исправления ошибок.В кодах проверки на четность блока (например, [31]) отправляется k информационных битов (0,1 для двоичного кода) в блоке из N бит, N> k; таким образом, в систему вводится избыточность, чтобы справиться с эффектами шума в канале передачи. Дополнительные биты известны как биты проверки четности. Для каждого кода определяется матрица проверки на четность, H ; Чтобы быть действительным, для каждого кодового слова x оно должно удовлетворять ограничению проверки на четность (операции по модулю 2), Hx = 0.Возьмем в качестве примера случай k = 3 и N = 6. Код состоит из 2 3 (в общем 2k) кодовых слов, каждое из которых имеет длину N = 6 бит. Для матрицы проверки на четность
H = [110100101010011001],
восемь кодовых слов, удовлетворяющих ограничению проверки на четность: 000000, 001011, 010101, 011110, 100110, 101101, 110011 и 111000. В каждом из них В восьми словах первые три бита являются информационными битами, а остальные — битами проверки четности, которые однозначно определяются для удовлетворения ограничению проверки на четность.Каждое из трех ограничений проверки на четность может быть выражено через функцию, то есть
ψ1 (x1, x2, x4) = δ (x1⊕x2⊕x4), ψ2 (x1, x3, x5) = δ ( x1⊕x3⊕x5), ψ3 (x2, x3, x6) = δ (x2⊕x3⊕x6),
где δ (⋅) равно единице или нулю, в зависимости от того, равен ли его аргумент единице или нулю, соответственно. , а ⊕ обозначает сложение по модулю 2. Кодовые слова передаются в двоичный симметричный канал без памяти с шумом, где каждый переданный бит xi может быть перевернут и получен как yi в соответствии со следующим правилом:
P (y = 0 | x = 1) = p , P (y = 1 | x = 1) = 1 − p, P (y = 1 | x = 0) = p, P (y = 0 | x = 0) = 1 − p.
После приема последовательности наблюдений yi, i = 1,2,…, N, необходимо определить значение xi, которое было передано. Поскольку предполагается, что канал не имеет памяти, на каждый бит влияет шум независимо от других битов, и общая апостериорная вероятность каждого кодового слова пропорциональна
∏i = 1NP (xi | yi).
Чтобы гарантировать, что учитываются только допустимые кодовые слова, и предполагая равновероятных информационных битов, мы записываем совместную вероятность как
P (x, y) = 1Zψ1 (x1, x2, x4) ψ2 (x1, x3 , x5) ψ3 (x2, x3, x6) ∏i = 1NP (yi | xi),
где учтены ограничения проверки на четность.Соответствующая факторная модель представлена на Рис. 15.19, где
Рис. 15.19. Факторный граф для кода проверки на четность (3,3).
gi (yi, xi) = P (yi | xi).
Задача декодирования состоит в том, чтобы вывести эффективную схему вывода для вычисления апостериорных значений и на основе этого принять решение в пользу 1 или 0.
Кодирование с исправлением ошибок | информатика
В теории информации: коды исправления и обнаружения ошибок\ n \ nРабота Шеннона в области дискретной, зашумленной связи указала на возможность построения кодов, исправляющих ошибки.Коды с исправлением ошибок добавляют дополнительные биты для исправления ошибок и, таким образом, работают в направлении, противоположном сжатию. С другой стороны, коды обнаружения ошибок… \ n
Подробнеекомбинаторных методов
«,» url «:» Introduction «,» wordCount «: 0,» sequence «: 1},» imarsData «: {» HAS_REVERTED_TIMELINE «:» false «,» INFINITE_SCROLL «:» «},» npsAdditionalContents «: {},» templateHandler «: {» metered «: false,» name «:» INDEX «},» paginationInfo «: {» previousPage «: null, «nextPage»: null, «totalPages»: 1}, «seoTemplateName»: «PAGINATED INDEX», «infiniteScrollList»: [{«p»: 1, «t»: 191931}], «familyPanel»: {» topicLink «: {» title «:» кодирование с исправлением ошибок «,» url «:» / topic / error-correcoding «},» tocPanel «: {» title «:» Directory «,» itemTitle «:» Ссылки » , «toc»: null}, «groups»: [], «showCommentButton»: false, «fastFactsItems»: null}, «byline»: {«members»: null, «allContributorsUrl»: null, «lastModificationDate»: null , «contentHistoryUrl»: null, «warningMessage»: null, «warningDescription»: null}, «citationInfo»: {«участники»: null, «title»: «код для исправления ошибок», «lastModification»: null, «url» : «https: // www.britannica.com/topic/error-correction-coding»},»websites»:null,»lastArticle»:false} Узнайте об этой теме в следующих статьях:приложения в теории информации
- в теории информации: коды исправления и обнаружения ошибок
Работа Шеннона в области дискретной зашумленной связи указала на возможность построения кодов с исправлением ошибок.Коды с исправлением ошибок добавляют дополнительные биты для исправления ошибок и, таким образом, работают в направлении, противоположном сжатию. С другой стороны, коды обнаружения ошибок…
Подробнее
комбинаторные методы
Проверка и исправление ошибок | Computerworld
Каждый раз, когда мы отправляем данные — будь то аудиосигналы по телефонной линии, поток данных или юридический документ — кому-то другому, мы должны знать, что то, что приходит на другой конец, идентично тому, что мы отправили.Точно так же всякий раз, когда мы сохраняем данные на диске или ленте, при их извлечении нам нужна уверенность в том, что они не были изменены. Точные данные абсолютно необходимы для вычислений, ведения документации, обработки транзакций и онлайн-торговли.
К сожалению, хранение и передача данных связаны с действиями физических объектов в реальном мире: электронов, фотонов, атомов, молекул, проводов, контактов и т. Д. Это означает, что всегда есть некоторая степень неопределенности, потому что фоновый шум всегда присутствует в нашей физической вселенной и может изменить или повредить любой заданный бит данных.
Обнаружение ошибок
На заре компьютерной революции были разработаны некоторые мощные методы, которые сначала позволяли обнаруживать, а затем исправлять ошибки в данных. Наиболее очевидный и, возможно, наименее эффективный способ обнаружения изменений данных — это многократно повторять каждую единицу данных, а затем сравнивать копии. Этот метод настолько неэффективен, что не используется для обнаружения ошибок — хотя та же идея используется в RAID-1 (зеркалирование дисков) для обеспечения отказоустойчивости.
Подробнее
Computerworld
QuickStudies
Самый известный метод обнаружения ошибок называется контролем четности, при котором к каждому байту данных добавляется один дополнительный бит и присваивается значение 1 или 0, обычно в зависимости от того, четное или нечетное. количество «1» битов.Принимающая система вычисляет, каким должен быть бит четности, и, если результат не совпадает, тогда мы знаем, что по крайней мере один бит был изменен, но мы не знаем, какой бит неправильный. Также возможно, что данные полностью верны, а бит четности искажен. Однако, если два бита были изменены, изменения аннулируются: данные будут неправильными, но бит четности не будет сигнализировать об ошибке. (Подробнее см. Обнаружение 2-битной ошибки .)
Двумя другими общепринятыми методами обнаружения ошибок являются контрольная сумма (складывание всех битов всего сообщения, документа или программы и получение единой суммы) и циклический контроль избыточности, который работает с группами битов одновременно и использует деление, а не сложение.Контрольные суммы и CRC вычисляются до и после передачи или дублирования, а затем сравниваются. Однако сами по себе контрольные суммы и CRC не могут проверить целостность данных, поскольку алгоритмы известны и можно внести преднамеренные изменения, которые эти методы не обнаружат. Более безопасный способ будет включать криптографические хеш-функции, односторонние математические операции, использование секретных ключей шифрования которых исключает возможность необнаружимых изменений.
Исправление ошибок
Таким образом, существуют методы, которые позволят нам находить ошибки в наших данных, но что дальше? Один из способов получить нужный материал — просто попросить отправляющую сторону или устройство повторно отправить его.Однако, если есть много ошибок или существует длинный путь связи, например, когда мы отправляем данные на полпути вокруг этой шумной планеты, повторная передача может значительно замедлить связь.
Нужна система, которая найдет ошибки и автоматически исправит их. Оказывается, мы можем создавать такие алгоритмы (известные как коды с исправлением ошибок, это другая фраза, которую иногда называют ECC) с любой степенью точности, которую мы хотим, но с компромиссом в эффективности.В большинстве случаев мы выбираем коды, которые могут обнаруживать и исправлять ошибки в одном бите и обнаруживать, но не исправлять ошибки в двух или более битах. (Простая иллюстрация того, как это работает с однобитной ошибкой, показана в Как работает ECC .)
Сегодня ECC используется во многих различных устройствах, от проигрывателей компакт-дисков до компьютеров. Возможно, наиболее известное его использование — это специальная ECC RAM для серверов, в которой дополнительные биты встроены непосредственно в микросхемы динамической RAM.
Заглядывая в будущее, ECC может стать более заметной и популярной на рынке беспроводной связи.Это связано с тем, что популярность беспроводной связи и доступность беспроводных продуктов, по прогнозам, значительно вырастут, но пропускная способность беспроводных каналов останется значительно ниже, чем у проводных подключений.
Кей — автор Computerworld из Вустера, штат Массачусетс. Вы можете связаться с ним по адресу [email protected].
См. Дополнительные Computerworld QuickStudies
Авторские права © 2004 IDG Communications, Inc.
Выходные коды с исправлением ошибок (ECOC) для машинного обучения
Последнее обновление 27 апреля 2021 г.
Алгоритмы машинного обучения, такие как логистическая регрессия и машины опорных векторов, предназначены для задач двухклассовой (бинарной) классификации.
Таким образом, эти алгоритмы необходимо либо модифицировать для решения задач классификации нескольких классов (более двух), либо вообще не использовать. Выходные коды с исправлением ошибок Метод — это метод, который позволяет переосмыслить проблему многоклассовой классификации как множественные задачи двоичной классификации, позволяя напрямую использовать собственные модели двоичной классификации.
В отличие от методов one-vs-rest и one-vs-one, которые предлагают аналогичное решение путем разделения задачи классификации на несколько классов на фиксированное количество задач двоичной классификации, метод выходных кодов с исправлением ошибок позволяет кодировать каждый класс как произвольное количество задач двоичной классификации. Когда используется переопределенное представление, это позволяет дополнительным моделям действовать как предсказания с «исправлением ошибок», что может привести к лучшей предсказательной способности.
В этом руководстве вы узнаете, как использовать выходные коды с исправлением ошибок для классификации.
После прохождения этого руководства вы будете знать:
- Выходные коды с исправлением ошибок — это метод использования моделей двоичной классификации в задачах прогнозирования мультиклассовой классификации.
- Как подбирать, оценивать и использовать модели классификации выходных кодов с исправлением ошибок для прогнозирования.
- Как настроить и оценить различные значения количества бит на гиперпараметр класса, используемого выходными кодами с исправлением ошибок.
Начните свой проект с моей новой книги Ensemble Learning Algorithms With Python, включающей пошаговых руководств и файлов исходного кода Python для всех примеров.
Приступим.
Выходные коды с исправлением ошибок (ECOC) для машинного обучения
Фото Фреда Хсу, некоторые права защищены.
Обзор учебного пособия
Это руководство разделено на три части; их:
- Выходные коды с исправлением ошибок
- Оценка и использование классификаторов ECOC
- Настройка количества бит на класс
Выходные коды с исправлением ошибок
Задачи классификации — это те, в которых метка является предсказательной для данной входной переменной.
Задачи двоичной классификации — это задачи классификации, в которых цель содержит два значения, а задачи классификации с несколькими классами — это задачи, имеющие более двух меток целевого класса.
Многие модели машинного обучения были разработаны для двоичной классификации, хотя они могут потребовать модификации для работы с задачами мультиклассовой классификации. Например, машины логистической регрессии и опорных векторов были специально разработаны для двоичной классификации.
Несколько алгоритмов машинного обучения, например SVM, изначально были разработаны для решения только задач двоичной классификации.
— стр. 133, Классификация образов с использованием методов ансамбля, 2010.
Вместо того, чтобы ограничивать выбор алгоритмов или адаптировать алгоритмы к мультиклассовым задачам, альтернативным подходом является переосмысление проблемы мультиклассовой классификации как множественных задач двоичной классификации. Для этого можно использовать два распространенных метода: один против остальных (OvR) и один против одного (OvO).
- OvR : разделяет задачу с несколькими классами на одну двоичную задачу для каждого класса.
- OvO : разделяет задачу с несколькими классами на одну двоичную задачу для каждой пары классов.
После разделения на подзадачи модель двоичной классификации может соответствовать каждой задаче, а модель с наибольшим откликом может использоваться в качестве прогноза.
И OvR, и OvO можно рассматривать как тип модели обучения ансамбля, учитывая, что несколько отдельных моделей подходят для задачи прогнозного моделирования и используются совместно для прогнозирования.В обоих случаях предсказание « членов ансамбля » является простым победителем при всех подходах.
… преобразовать мультиклассовую задачу в ансамбль задач двоичной классификации, результаты которых затем объединяются.
— стр. 134, Классификация образов с использованием методов ансамбля, 2010.
Подробнее о моделях one-vs-rest и one-vs-one см. В руководстве:
Связанный подход состоит в том, чтобы подготовить двоичное кодирование (например, цепочку битов) для представления каждого класса в задаче.Каждый бит в строке можно предсказать с помощью отдельной задачи двоичной классификации. Кодирование длины может быть выбрано произвольно для данной задачи классификации нескольких классов.
Для ясности, каждая модель получает полный входной шаблон и предсказывает только одну позицию в выходной строке. Во время обучения каждую модель можно обучить для получения правильных выходных данных 0 или 1 для задачи двоичной классификации. Затем можно сделать прогноз для новых примеров, используя каждую модель для прогнозирования входных данных, чтобы создать двоичную строку, а затем сравнить двоичную строку с известной кодировкой каждого класса.Затем в качестве выходных данных выбирается кодировка класса, имеющая наименьшее расстояние до предсказания.
Каждому классу присваивается кодовое слово длины l. Обычно размер кодовых слов содержит больше битов, чем необходимо для уникального представления каждого класса.
— стр. 138, Классификация образов с использованием методов ансамбля, 2010.
Это интересный подход, который позволяет представлению класса быть более сложным, чем требуется (возможно, переопределенным) по сравнению с однократным кодированием, и вводит избыточность в представление и моделирование проблемы.Это сделано намеренно, поскольку дополнительные биты в представлении действуют как коды с исправлением ошибок, чтобы исправить, исправить или улучшить прогноз.
… идея состоит в том, что избыточные «исправляющие ошибки» биты допускают некоторые неточности и могут улучшить производительность.
— стр. 606, Элементы статистического обучения, 2016 г.
Это дало название технике: выходные коды с исправлением ошибок, или сокращенно ECOC.
Выходные коды с исправлением ошибок (ECOC) — это простой, но эффективный подход к решению многоклассовой проблемы, основанный на комбинации двоичных классификаторов.
— стр. 90, Ансамблевые методы, 2012.
Следует позаботиться о том, чтобы каждый закодированный класс имел совершенно разную кодировку двоичной строки. Был исследован набор различных схем кодирования, а также конкретные методы построения кодировок, чтобы гарантировать, что они находятся достаточно далеко друг от друга в пространстве кодирования. Интересно, что случайные кодировки работают, возможно, не хуже.
… проанализировал подход ECOC и показал, что случайное присвоение кода работает так же хорошо, как и оптимально построенные коды с исправлением ошибок
— стр. 606, Элементы статистического обучения, 2016 г.
Для подробного обзора различных схем и методов кодирования для отображения предсказанных строк в закодированные классы я рекомендую главу 6 «Выходные коды с исправлением ошибок » книги «Классификация шаблонов с использованием ансамблевых методов».
Хотите начать ансамблевое обучение?
Пройдите бесплатный 7-дневный ускоренный курс по электронной почте (с образцом кода).
Нажмите, чтобы зарегистрироваться, а также получите бесплатную электронную версию курса в формате PDF.
Загрузите БЕСПЛАТНЫЙ мини-курс
Оценка и использование классификаторов ECOC
Библиотека scikit-learn предоставляет реализацию ECOC через класс OutputCodeClassifier.
Класс принимает в качестве аргумента модель, которая будет соответствовать каждому двоичному классификатору, и может использоваться любая модель машинного обучения. В этом случае мы будем использовать модель логистической регрессии, предназначенную для бинарной классификации.
Класс также предоставляет аргумент « code_size », который определяет размер кодировки для классов как кратное количеству классов, например.грамм. количество битов для кодирования для каждой метки класса.
Например, если нам нужна кодировка с битовыми строками длиной 6 бит, и у нас есть три класса, то мы можем указать размер кодирования как 2:
- длина_кодирования = размер_кода * количество_классов
- длина_кодирования = 2 * 3
- длина_кодирования = 6
Пример ниже демонстрирует, как определить пример OutputCodeClassifier с 2 битами на класс и с использованием модели LogisticRegression для каждого бита в кодировке.
… # определить модель бинарной классификации model = LogisticRegression () # определить модель ecoc ecoc = OutputCodeClassifier (модель, code_size = 2, random_state = 1)
… # определить модель двоичной классификации model = LogisticRegression () # определить модель ecoc ecoc = OutputCodeClassifier (model, code_size = 2, random_state = 1) |
Хотя существует множество сложных способов создания кодировки для каждого класса, класс OutputCodeClassifier выбирает случайную кодировку битовой строки для каждого класса, по крайней мере, на момент написания.
Мы можем исследовать использование OutputCodeClassifier в синтетической задаче классификации нескольких классов.
Мы можем использовать функцию make_classification () для определения задачи классификации нескольких классов с помощью 1000 примеров, 20 входных функций и трех классов.
Пример ниже демонстрирует, как создать набор данных и суммировать количество строк, столбцов и классов в наборе данных.
# набор данных многоклассовой классификации из коллекций счетчик импорта из склеарна.наборы данных импорт make_classification # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1, n_classes = 3) # резюмируем набор данных печать (X.shape, y.shape) # суммируем количество классов print (Счетчик (y))
# мультиклассовый набор данных из коллекций import Counter from sklearn.datasets import make_classification # define dataset X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_informative = 15, n_informative = 15, n_informative = 5, n_informative = 15, n_informative = 5 , random_state = 1, n_classes = 3) # суммировать набор данных print (X.shape, y.shape) # суммируем количество классов print (Counter (y)) |
При выполнении примера создается набор данных и отображается количество строк и столбцов, подтверждая, что набор данных был создан, как ожидалось.
Затем сообщается количество примеров в каждом классе, показывая почти равное количество случаев для каждого из трех настроенных классов.
(1000, 20) (1000,) Счетчик ({2: 335, 1: 333, 0: 332})
(1000, 20) (1000,) Счетчик ({2: 335, 1: 333, 0: 332}) |
Затем мы можем оценить модель выходных кодов с исправлением ошибок в наборе данных.
Мы будем использовать логистическую регрессию с 2 битами на класс, как мы определили выше. Затем модель будет оцениваться с использованием многократной стратифицированной k-кратной перекрестной проверки с тремя повторениями и 10-кратной проверкой. Мы суммируем производительность модели, используя среднее значение и стандартное отклонение точности классификации для всех повторов и складок.
… # определить процедуру оценки cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) # оценить модель и собрать баллы n_scores = cross_val_score (ecoc, X, y, scoring = ‘точность’, cv = cv, n_jobs = -1) # подвести итоги производительности print (‘Точность:%.3f (% .3f) ‘% (среднее (n_scores), std (n_scores)))
… # определить процедуру оценки cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) # оценить модель и собрать баллы n_scores = cross_val_score (ecoc, X, y, scoring = ‘precision’, cv = cv, n_jobs = -1) # суммируем производительность print (‘Accuracy:% .3f (% .3f)’% (mean (n_scores), std (n_scores) )) |
Полный пример приведен ниже.
# оценить выходные коды с исправлением ошибок для мультиклассовой классификации из среднего значения импорта из numpy import std из sklearn.datasets импортировать make_classification из sklearn.model_selection импорт cross_val_score из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.linear_model import LogisticRegression из sklearn.multiclass import OutputCodeClassifier # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1, n_classes = 3) # определить модель бинарной классификации model = LogisticRegression () # определить модель ecoc ecoc = OutputCodeClassifier (модель, code_size = 2, random_state = 1) # определить процедуру оценки cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) # оценить модель и собрать баллы n_scores = cross_val_score (ecoc, X, y, scoring = ‘точность’, cv = cv, n_jobs = -1) # подвести итоги производительности print (‘Точность:%.3f (% .3f) ‘% (среднее (n_scores), std (n_scores)))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 18 19 20 | # оценить выходные коды с исправлением ошибок для классификации нескольких классов из numpy import mean из numpy import std из sklearn.наборы данных импортировать make_classification из sklearn.model_selection импорт cross_val_score из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.linear_model import LogisticRegression из sklearn.mult_Class2000simport из sklearn.mult_Class9 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1, n_classes = 3) # определить модель двоичной классификации model = LogisticRegression () # определить модель ecoc ecoc = OutputCodeClassifier ( model, code_size = 2, random_state = 1) # определить процедуру оценки cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) # оценить модель и собрать баллы n_score cross_score = (ecoc, X, y, scoring = ‘precision’, cv = cv, n_jobs = -1) # подвести итоги работы 9000 5 print (‘Точность:%.3f (% .3f) ‘% (среднее (n_scores), std (n_scores))) |
Выполнение примера определяет модель и оценивает ее на нашем наборе данных синтетической мультиклассовой классификации с использованием определенной процедуры тестирования.
Примечание : Ваши результаты могут отличаться из-за стохастической природы алгоритма или процедуры оценки или различий в числовой точности. Подумайте о том, чтобы запустить пример несколько раз и сравнить средний результат.
В этом случае мы видим, что модель достигла средней точности классификации около 76.6 процентов.
Мы можем использовать это как нашу окончательную модель.
Это требует, чтобы мы подогнали модель ко всем имеющимся данным и использовали ее для прогнозирования новых данных.
Пример ниже представляет собой полный пример того, как подогнать и использовать выходную модель с исправлением ошибок в качестве окончательной модели.
# использовать модель выходных кодов с исправлением ошибок в качестве окончательной модели и сделать прогноз из sklearn.datasets импортировать make_classification из склеарна.linear_model импорт LogisticRegression из sklearn.multiclass import OutputCodeClassifier # определить набор данных X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1, n_classes = 3) # определить модель бинарной классификации model = LogisticRegression () # определить модель ecoc ecoc = OutputCodeClassifier (модель, code_size = 2, random_state = 1) # подогнать модель ко всему набору данных ecoc.fit (X, y) # сделать единый прогноз row = [[0.04339387, 2,75542632, -3,79522705, -0,71310994, -3,08888853, -1,2963487, -1,92065166, -3,15609907, 1,37532356, 3,61293237, 1,00353523, -3,77126962, 2,26638828, -10,263128406396 ] yhat = ecoc.predict (строка) print (‘Прогнозируемый класс:% d’% yhat [0])
# используйте модель выходных кодов с исправлением ошибок в качестве окончательной модели и сделайте прогноз из sklearn.наборы данных import make_classification from sklearn.linear_model import LogisticRegression from sklearn.multiclass import OutputCodeClassifier # define dataset X, y = make_classification (n_samples = 1000, n_features = 20, n_features = 5 1, n_classes = 3) # определить модель двоичной классификации model = LogisticRegression () # определить модель ecoc ecoc = OutputCodeClassifier (model, code_size = 2, random_state = 1) # соответствовать модели по всему набору данных ecoc.fit (X, y) # сделать одно предсказание row = [[0,04339387, 2,75542632, -3,79522705, -0,71310994, -3,08888853, -1,2963487, -1,92065166, -3,15609907, 1,37532356, -1. 2.26638828, -10.22368666, -0.35137382, 1.84443763, 3.7040748, 2.50964286, 2.18839505, -2.31211692]] yhat = ecoc.predict (row) print (‘Прогнозируемый класс:% d’)% [0 | ]
Выполнение примера соответствует модели ECOC для всего набора данных и использует модель для прогнозирования метки класса для одной строки данных.
В этом случае мы видим, что модель предсказала метку класса 0.
Теперь, когда мы знакомы с тем, как установить и использовать модель ECOC, давайте подробнее рассмотрим, как ее настроить.
Настройка количества бит на класс
Ключевым гиперпараметром для модели ECOC является кодирование меток классов.
Сюда входят такие свойства, как:
- Выбор представления (биты, действительные числа и т. Д.)
- Кодировка каждой метки класса (случайная и т. Д.)
- Длина представления (количество бит и т. Д.)
- Как прогнозы сопоставляются с классами (расстояние и т. Д.)
Реализация scikit-learn OutputCodeClassifier в настоящее время не обеспечивает большого контроля над этими элементами.
Элемент, над которым он дает контроль, — это количество битов, используемых для кодирования каждой метки класса.
В этом разделе мы можем выполнить ручной поиск по сетке по разному количеству бит на метку класса и сравнить результаты.Это предоставляет шаблон, который вы можете адаптировать и использовать в своем собственном проекте.
Во-первых, мы можем определить функцию для создания и возврата набора данных.
# получить набор данных def get_dataset (): X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1, n_classes = 3) возврат X, y
# получить набор данных def get_dataset (): X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1, n_classes = 3) return X г |
Затем мы можем определить функцию, которая создаст набор моделей для оценки.
Каждая модель будет примером OutputCodeClassifier , использующего LogisticRegression для каждой задачи двоичной классификации. Мы настроим code_size для каждой модели, чтобы он был различным, со значениями от 1 до 20.
# получить список моделей для оценки def get_models (): модели = dict () для i в диапазоне (1,21): # создать модель model = LogisticRegression () # создать классификатор выходного кода с исправлением ошибок модели [str (i)] = OutputCodeClassifier (модель, code_size = i, random_state = 1) вернуть модели
# получить список моделей для оценки def get_models (): models = dict () for i in range (1,21): # create model model = LogisticRegression () # создать классификатор кода вывода с исправлением ошибок models [str (i)] = OutputCodeClassifier (model, code_size = i, random_state = 1) return models |
Мы можем оценить каждую модель с помощью соответствующей k-кратной перекрестной проверки, как мы это делали в предыдущем разделе, чтобы получить образец оценок точности классификации.
# оценить модель предоставления с помощью перекрестной проверки def оценивать_модель (модель): cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) оценки = cross_val_score (модель, X, y, оценка = ‘точность’, cv = cv, n_jobs = -1) возврат баллов
# оценить модель предоставления с помощью перекрестной проверки def rating_model (model): cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) баллов = cross_val_score (model, X, y, scoring = ‘точность’, cv = cv, n_jobs = -1) баллов возврата |
Мы можем сообщить среднее значение и стандартное отклонение оценок для каждой конфигурации и построить распределения в виде диаграмм в виде прямоугольников и усов, чтобы визуально сравнить результаты.
… # оценить модели и сохранить результаты результаты, имена = список (), список () для имени, модели в models.items (): scores = Assessment_model (модель) results.append (баллы) names.append (имя) print (‘>% s% .3f (% .3f)’% (имя, среднее (баллы), стандартное (баллы))) # построить график производительности модели для сравнения pyplot.boxplot (результаты, метки = имена, showmeans = True) pyplot.show ()
… # оценить модели и сохранить результаты результатов, names = list (), list () для имени, модели в models.items (): scores = Assessment_model (model) results.append (баллы) names.append (имя) print (‘>% s% .3f (% .3f)’% (имя, среднее (баллы), стандартное (баллы))) # производительность модели построения графика для сравнение pyplot.boxplot (результаты, метки = имена, showmeans = True) pyplot.show () |
Собирая все вместе, ниже приведен полный пример сравнения классификации ECOC с сеткой количества битов на класс.
# сравнить количество битов на класс для классификации выходного кода с исправлением ошибок из среднего значения импорта из numpy import std из sklearn.datasets импортировать make_classification из sklearn.model_selection импорт cross_val_score из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.linear_model import LogisticRegression из sklearn.multiclass import OutputCodeClassifier из matplotlib import pyplot # получить набор данных def get_dataset (): X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1, n_classes = 3) вернуть X, y # получить список моделей для оценки def get_models (): модели = dict () для i в диапазоне (1,21): # создать модель model = LogisticRegression () # создать классификатор выходного кода с исправлением ошибок модели [str (i)] = OutputCodeClassifier (модель, code_size = i, random_state = 1) вернуть модели # оценить модель предоставления с помощью перекрестной проверки def оценивать_модель (модель): cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) оценки = cross_val_score (модель, X, y, оценка = ‘точность’, cv = cv, n_jobs = -1) вернуть баллы # определить набор данных X, y = get_dataset () # получить модели для оценки модели = get_models () # оценить модели и сохранить результаты результаты, имена = список (), список () для имени, модели в моделях.Предметы(): scores = Assessment_model (модель) results.append (баллы) names.append (имя) print (‘>% s% .3f (% .3f)’% (имя, среднее (баллы), стандартное (баллы))) # построить график производительности модели для сравнения pyplot.boxplot (результаты, метки = имена, showmeans = True) pyplot.show ()
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 13 14 18 19 20 21 22 23 24 25 26 27 28 29 30 000 000 3435 36 37 38 39 40 41 42 43 44 45 | # сравнить количество битов на класс для классификации выходного кода с исправлением ошибок из numpy import mean из numpy import std из sklearn.наборы данных импортировать make_classification из sklearn.model_selection импорт cross_val_score из sklearn.model_selection import RepeatedStratifiedKFold из sklearn.linear_model import LogisticRegression 000 из sklearn.multiclass2000 импорт 000 из sklearn.multiclass5 def get_dataset (): X, y = make_classification (n_samples = 1000, n_features = 20, n_informative = 15, n_redundant = 5, random_state = 1, n_classes = 3) return X, y # get список моделей для оценки def get_models (): models = dict () for i in range (1,21): # create model model = LogisticRegression () # create error correcting классификатор кода вывода моделей [str (i)] = OutputCodeClassifier (модель, code_size = i, random_state = 1) модели возврата # оценить модель предоставления с помощью перекрестной проверки def rating_model (model): cv = RepeatedStratifiedKFold (n_splits = 10, n_repeats = 3, random_state = 1) scores = cross_val_score (model, , scoring = ‘precision’, cv = cv, n_jobs = -1) вернуть оценки # определить набор данных X, y = get_dataset () # получить модели для оценки models = get_models ( ) # оценить модели и сохранить результаты results, names = list (), list () для имени, модели в моделях.items (): scores = valu_model (model) results.append (scores) names.append (name) print (‘>% s% .3f (% .3f)’% (name, mean (scores), std (scores))) # график производительности модели для сравнения pyplot.boxplot (results, labels = names, showmeans = True) pyplot.show () |
При выполнении примера сначала оценивается каждая конфигурация модели и сообщается среднее значение и стандартное отклонение оценок точности.
Примечание : Ваши результаты могут отличаться из-за стохастической природы алгоритма или процедуры оценки или различий в числовой точности. Подумайте о том, чтобы запустить пример несколько раз и сравнить средний результат.
В этом случае мы видим, что, возможно, 5 или 6 бит на класс дают наилучшую производительность со средними показателями точности около 78,2% и 78,0% соответственно. Мы также видим хорошие результаты для 9, 13, 17 и 20 бит на класс, при этом, возможно, 17 бит на класс дают лучший результат около 78.5 процентов.
> 1 0,545 (0,032) > 2 0,766 (0,037) > 3 0,776 (0,036) > 4 0,769 (0,035) > 5 0,782 (0,037) > 6 0,780 (0,037) > 7 0,776 (0,039) > 8 0,775 (0,036) > 9 0,782 (0,038) > 10 0,779 (0,036) > 11 0,770 (0,033) > 12 0,777 (0,037) > 13 0,781 (0,037) > 14 0,779 (0,039) > 15 0,771 (0,033) > 16 0,769 (0,035) > 17 0,785 (0,034) > 18 0,776 (0,038) > 19 0.776 (0,034) > 20 0,780 (0,038)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 18 19 20 | > 1 0,545 (0,032) > 2 0,766 (0,037) > 3 0,776 (0.036) > 4 0,769 (0,035) > 5 0,782 (0,037) > 6 0,780 (0,037) > 7 0,776 (0,039) > 8 0,775 (0,036) > 9 0,782 (0,038) > 10 0,779 (0,036) > 11 0,770 (0,033) > 12 0,777 (0,037) > 13 0,781 (0,037) > 14 0,779 (0,039) > 15 0,771 (0,033) > 16 0,769 (0,035) > 17 0,785 (0,034) > 18 0,776 (0.038) > 19 0,776 (0,034) > 20 0,780 (0,038) |
Создается рисунок, на котором показаны прямоугольники и усы для оценок точности для каждой конфигурации модели.
Мы видим, что, помимо значения 1, количество битов на класс дает аналогичные результаты с точки зрения разброса и средних оценок точности, составляющих около 77 процентов. Это говорит о том, что подход достаточно стабилен для разных конфигураций.
Графики ящиков и усов для битов на класс по сравнению сРаспределение точности классификации для ECOC
Дополнительная литература
Этот раздел предоставляет дополнительные ресурсы по теме, если вы хотите углубиться.
Связанные руководства
Документы
Книги
API
Резюме
В этом руководстве вы узнали, как использовать выходные коды с исправлением ошибок для классификации.
В частности, вы выучили:
- Выходные коды с исправлением ошибок — это метод использования моделей двоичной классификации в задачах прогнозирования мультиклассовой классификации.
- Как подбирать, оценивать и использовать модели классификации выходных кодов с исправлением ошибок для прогнозирования.
- Как настроить и оценить различные значения количества бит на гиперпараметр класса, используемого выходными кодами с исправлением ошибок.
Есть вопросы?
Задайте свои вопросы в комментариях ниже, и я постараюсь ответить.
Получите представление о современном ансамблевом обучении!
Улучшите свои прогнозы за считанные минуты
…с всего несколькими строками кода Python
Узнайте, как это сделать в моей новой электронной книге:
Алгоритмы ансамблевого обучения с Python
Он предоставляет руководств для самостоятельного изучения с полным рабочим кодом на:
Стекинг , Голосование , Boosting , Bagging , Blending , Super Learner ,
и многое другое …
Привнесите современные методы ансамблевого обучения в
свои проекты машинного обучения
Посмотрите, что внутри
Математических методов и алгоритмов: Мун, Тодд К.: 9780471648000: Amazon.com: Книги
Непревзойденный инструмент обучения и руководство по кодированию с исправлением ошибокМетоды кодирования с исправлением ошибок позволяют обнаруживать и исправлять ошибки, возникающие во время передачи данных в цифровых системах связи. Эти методы почти повсеместно используются в современных системах связи и, таким образом, являются важным компонентом современной информационной экономики.
Кодирование с исправлением ошибок: математические методы и алгоритмы представляет собой всестороннее введение как в теоретические, так и практические аспекты кодирования с исправлением ошибок, с презентацией, подходящей для самых разных аудиторий, включая аспирантов в области электротехники, математики или информатики.Педагогика построена таким образом, что математические концепции представлены постепенно, а затем сразу же следуют приложения к кодированию. Большое количество упражнений расширяет и углубляет понимание учащимися. Уникальной особенностью книги является набор лабораторий программирования, дополненных более чем 250 программами и функциями на соответствующем веб-сайте, который обеспечивает практический опыт и лучшее понимание материала.