Вместо тысячи слов… 3 февраля отмечается всемирный день борьбы с ненормативной лексикой
Точную дату, когда впервые стали отмечать Всемирный день борьбы с ненормативной лексикой, а также кем было предложено отмечать этот день, нам установить не удалось. Об этом можно говорить лишь примерно – начало ХХI века. Чем продиктовано намерение отмечать Всемирный день борьбы с ненормативной лексикой в России? Видимо, потребностью общества. Слишком много стало ненормативности вокруг, на что повлияли изменения в социокультурной ситуации: отмена внешней цензуры в постперестроечный период, как следствие – утрата многими представителями социума цензуры внутренней; понимание свободы слова как вседозволенности в выборе средств выражения, общий упадок культуры и культуры речи, в частности.
Попытаемся разобраться в том, что стоит за ненормативной лексикой, почему она оказалась вне нормы и всегда ли употребление таких единиц в речи нарушает нормы этические и эстетические.
К ненормативной лексике относятся бранные, жаргонные, матерные и вульгарные выражения, слова-паразиты, канцеляризмы, а ещё диалектизмы и просторечия.
Впервые русский мат был упомянут в берестяной грамоте XII века, которую обнаружили археологи. До XIV века на Руси все неприличные слова назывались «нелепыми глаголами». Теперь же названий много: ругательства, нецензурная брань, ненормативная лексика, ругань, сквернословие. Для обозначения матерной лексики в лингвистике есть термин «обсценная лексика», восходящий к лат. obscenus (отвратительный, непристойный, неприличный) – сегмент бранной лексики различных языков, включающий грубейшие (похабные, непристойно мерзкие, вульгарные) бранные языковые единицы, часто выражающие спонтанную речевую реакцию на неожиданную (обычно неприятную) ситуацию.
В работах, ориентированных на изучение национальных особенностей русских людей, нецензурная матерная лексика выделяется как одна из ведущих специфических черт. Интересен тот факт, что исследованием феномена русского мата в ХХ веке активно занимались зарубежные ученые. В. М. Мокиенко в статье «Русская бранная лексика: цензурное и нецензурное», пишет, что начиная с конца 1970-х годов на Западе был опубликован целый ряд статей и монографий на эту тему. С началом перестройки в США было выпущено несколько лексикографических справочников – их характеризовала уже практическая направленность, стремление «пополнить лексический багаж» студентов-русистов, обучающихся на стандартных литературных русских текстах, облегчить для них живое общение с русскими. Что это? Внедрение в сознание общества мысли, что русские неспособны выражать свои мысли без использования в речи бранных слов? Однако отметим: по количеству нецензурных слов и выражений русский язык стоит на третьем месте в мире. Пальму первенства удерживает английский язык, на втором месте – голландский.
Современные исследователи не рассматривают всерьёз бытующее в русском народе ненаучное представление о том, что обсценная лексика была заимствована русскими из татарского во время татаро-монгольского ига. Русская ненормативная лексика имеет древние славянские и индоевропейские корни. Нецензурная лексика русского языка изначально оценивалась как табуированная – запрещенная по соображениям религиозным, мистическим, моральным, политическим. Такой запрет был направлен на соблюдение хорошего тона в обществе.
Мат в любом языке – неоднозначное языковое явление. С одной стороны, использование нецензурных слов и выражений обществом не приветствуется, с другой – в языке, в частности – русском, выделились самостоятельные речевые жанры, главным образом устные, например, анекдот, где эстетически нагруженная матерная лексика может быть коммуникативно оправданной. Есть жизненные обстоятельства, в которых использование мата не осуждается. Это касается чрезвычайных ситуаций, в которых человек подвержен опасности: разного рода аварии, катастрофы и под.
Сегодня нецензурная лексика получила широкое распространение, проникнув в средства массовой информации и художественную литературу. Молодые люди читают современных писателей и видят там соответствующие слова. А сигнал, который на телевидении пускают вместо ненормативной лексики, – тоже своего рода реклама мата. Пользователи сети Интернет, комментируя действия власти, позволяют высказываться нецензурно в адрес представителей административных структур, что, кстати, преследуется законом. Здесь заметим: следует различать такие понятия, как «критика» и «оскорбление», в том числе матом
Любители острого словца, оправдывая свои речевые действия, часто ссылаются на высказывания знаменитостей. Так, в Интернете «гуляет» фраза Фаины Раневской: «Лучше быть хорошим человеком, ругающимся матом, чем тихой воспитанной тварью». Эти слова воспринимать можно по-разному. Сравните также высказывание Джека Лондона: «Крепкое словцо, вовремя и к месту сказанное, облегчает душу. Частая ругань лишает ругательство смысла» («Ночь на Гобото», 1911 г.).
Частая ругань лишает ругательство смысла» («Ночь на Гобото», 1911 г.).
Вряд ли возможно сегодня искоренить мат. Тем не менее, дόлжно знать, что в России сквернословие по юридическим законам рассматривается как нарушение общественного порядка, оскорбление личности. Оно может соответствовать статье о разжигании национальной, религиозной и этнической розни и повлечь за собой наказание.
Какой быть нашей речи завтра – зависит от нас с вами!
Советуем почитать:
Мокиенко В. М. Русская бранная лексика: цензурное и нецензурное // Русистика. Берлин, 1994, № ½. С. 50–73.
Успенский Б. А. Религиозно-мифологический аспект русской экспрессивной фразеологии // Semiotics and the History of Culture. Ohio, 1988. С. 197–302.
Сковородников А. П. Экология русского языка: монография. Красноярск: Сиб. федер. ун-т, 2016. 388 с.
Шаховский В. И. Унижение языком в контексте современного коммуникативного пространства России // Мир русского слова. 2007. №1−2. С. 40−41.
С. 40−41.
доктор филол. наук, доцент,
зав. кафедрой русского языка и речевой коммуникации
3 февраля отмечается день борьбы с ненормативной лексикой
03 февраля 2015
В народе говорят: «Страшен нож не за поясом, а на кончике языка». А Сократ утверждал: «Каков человек – такова его речь». Ненормативная лексика – это не только набор непристойных слов и выражений. Ее употребление говорит о бедном словарном запасе и духовной нищете человека.
Спад национальной культуры в России фиксируют сегодня почти все, кто хоть сколько-нибудь интересуется своей страной и тем, что с ней происходит. В повседневной жизни мы уже почти не обходимся без слов, которые, несмотря на свою распространенность по старой памяти все еще вызывают смущение и чувство стыда, хотя уже давно не у всех.
В народе говорят: «Страшен нож не за поясом, а на кончике языка». А Сократ утверждал: «Каков человек – такова его речь». Ненормативная лексика – это не только набор непристойных слов и выражений. Ее употребление говорит о бедном словарном запасе и духовной нищете человека.
Ненормативная лексика – это не только набор непристойных слов и выражений. Ее употребление говорит о бедном словарном запасе и духовной нищете человека.
Согласно статистике, в наши дни ненормативную лексику используют в своей речи около 80% населения страны.
Проведенные специалистами одной из российских библиотек исследования показали, что сквернословие в подростковой среде распространяется от чрезмерного употребления, при этом оно утрачивает первоначальное значение, используется в качестве связки слов. Ненормативную лексику употребляют люди, окружающие подростков, причем более половины из них делают это обдуманно с целью оскорбить или обидеть собеседника. И не смотря на это, все опрошенные считают, что нужно искоренять ненормативную лексику в обществе. Многие даже догадываются, что бранные слова плохо влияют на их здоровье, при этом не могут объяснить, в чем заключается плохое влияние. Что касается отношения к употреблению бранных слов в речи, в музыке, в литературе все подростки считают, что это плохо, и они не хотят, чтобы их будущие дети слышали и использовали эти слова.
Для того чтобы привычка сквернословить не стала нормой жизни и не привела к непоправимым изменениям здоровья нашего поколения и к вырождению нации в целом, нужно в учебных заведениях, в семье, в средствах массовой информации уделять больше внимания этому вопросу, привлекать общественность. И рассказывать, не только о вреде курения, алкоголя, наркотиков, но и о вреде сквернословия.
библиограф МБУК «ОМЦБ» Михалева И.С.
Фильтр ненормативной лексики — Переводчик — Azure Cognitive Services
- Чтение занимает 2 мин
Оцените свои впечатления
Да Нет
Хотите оставить дополнительный отзыв?
Отзывы будут отправляться в корпорацию Майкрософт. Нажав кнопку «Отправить», вы разрешаете использовать свой отзыв для улучшения продуктов и служб Майкрософт. Политика конфиденциальности.
Нажав кнопку «Отправить», вы разрешаете использовать свой отзыв для улучшения продуктов и служб Майкрософт. Политика конфиденциальности.
Отправить
Спасибо!
В этой статье
Обычно служба переводов сохраняет в переводе ненормативную лексику, которая присутствует в источнике. Степень ненормативной лексики и контекст, который делает слова оскорбительными, отличаются между культурами. В результате степень оскорбительности лексики на целевом языке может усиливаться или уменьшаться.
Если необходимо избежать ненормативной лексики при переводе, даже если она есть в источнике, можно использовать параметр фильтрации ненормативной лексики, доступный в методе Translate(). Этот параметр позволяет выбрать, хотите ли вы удалить ненормативную лексику, пометить ее соответствующими тегами или не предпринимать никаких действий.
Метод Translate() принимает параметр options, который содержит новый элемент ProfanityAction. Принятыми значениями для элемента ProfanityAction являются NoAction (пропущено), Marked (помечено) и Deleted (удалено).
Принятые значения ProfanityAction и примеры
| Значение ProfanityAction | Действие | Пример: Источник — японский | Пример: Целевой объект — английский |
|---|---|---|---|
| NoAction | По умолчанию. Аналогично отсутствию параметра. Ненормативная лексика переходит из источника в целевой объект. | 彼は変態です。 | Он подонок. |
| Marked | Оскорбительные слова выделены XML-тегами <profanity>…</profanity>. | 彼は変態です。 | Он <profanity>подонок</profanity>. |
| Удаленная | Оскорбительные слова удаляются из выходных данных без замены. | 彼は。 | Он — . |
Дальнейшие действия
Параметры сеанса | Справка Blackboard
Выбор предпочтительного языка
До настоящего времени в Collaborate по умолчанию использовался язык, установленный в браузере, который мог не совпадать с вашим предпочтительным языком. Теперь вы можете выбрать любой язык, поддерживаемый Collaborate, как язык сеанса по умолчанию. Это можно сделать в разделе «Параметры сеанса». Выбранный язык будет сохранен в браузере и использоваться на этом устройстве в следующих сеансах.
Теперь вы можете выбрать любой язык, поддерживаемый Collaborate, как язык сеанса по умолчанию. Это можно сделать в разделе «Параметры сеанса». Выбранный язык будет сохранен в браузере и использоваться на этом устройстве в следующих сеансах.
В целях повышения безопасности и для поддержки этого выпуска Blackboard внедрит усовершенствования продуктов, которые укрепят безопасность интеграций Collaborate. Эти изменения будут автоматически применены в течение запланированного периода выпуска.
Показывать изображения из профиля только модераторам
Чтобы защитить свой сеанс от неприемлемых изображений профилей, запретите показ любых изображений, кроме изображений модераторов Если выбрать этот параметр, изображения профилей участников не будут отображаться где обычно: в списке Присутствующие, чате, секционных группах и основном окне. Вместо этого для участников отображается стандартный аватар.
Представление в виде галереи
Представление в виде галереи позволяет одновременно отобразить больше всего учащихся. В этом представлении можно видеть до 25 присутствующих на одной странице. 25 — оптимальное количество видео, которое можно отобразить на странице и которое в то же время дает достаточно подробную картину для визуального невербального наблюдения.
В этом представлении можно видеть до 25 присутствующих на одной странице. 25 — оптимальное количество видео, которое можно отобразить на странице и которое в то же время дает достаточно подробную картину для визуального невербального наблюдения.
Настройки представления галереи позволяют выбрать:
- сможет ли каждый участник сеанса использовать представление галереи;
- только ли модераторы смогут использовать представление галереи;
- будет ли представление галереи отключено для всех.
Если отключить представление галереи, отображается до 4 видео. Присутствующие не смогут выбрать большее количество.
Разрешения участников
По умолчанию все разрешения включены для сеансов с менее чем 250 участниками. Участники могут обмениваться аудио, видео, размещать сообщения в чате, рисовать на электронных досках и в файлах. Снимите все флажки, чтобы отключить разрешение.
Вы можете менять разрешения участников как до, так и во время сеанса.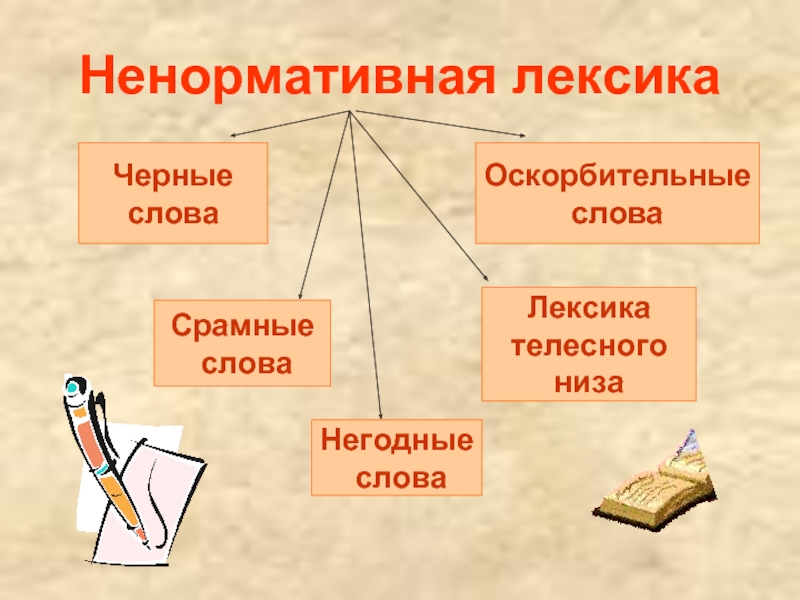 Эти параметры включают или отключают разрешения для всех участников сразу. Вы не можете изменить разрешения только для одного участника. Чтобы предоставить определенным присутствующим особые разрешения, измените их роль.
Эти параметры включают или отключают разрешения для всех участников сразу. Вы не можете изменить разрешения только для одного участника. Чтобы предоставить определенным присутствующим особые разрешения, измените их роль.
Разрешения участников не влияют на разрешения модераторов и ведущих.
В больших сеансах все разрешения участников отключены по умолчанию и не могут быть изменены. Дополнительные сведения см. на странице Настройки в режиме вебинара.
Мосгордума отклонила законопроект о ненормативной лексике
Мосгордума отклонила законопроект о ненормативной лексике
5 апреля, обсудив в первом чтении проект постановления «О проекте федерального закона «О внесении изменения в статью 20.1 Кодекса Российской Федерации об административных правонарушениях», Московская городская Дума не приняла этот документ.
В этой статье КоАП установлена административная ответственность за нарушения общественного порядка и общественной безопасности, в том числе за мелкое хулиганство, выражающееся в употреблении нецензурной брани в общественных местах.
Автор проекта законодательной инициативы депутат Николай Губенко (фракция «КПРФ») предложил расширить сферу действия этой статьи, изменив толкование мелкого хулиганства, как нарушение общественного порядка, выражающееся в использовании в общественных местах ненормативной лексики, бранных, жаргонных слов и оборотов, сленговых выражений, унижающих человеческое достоинство. Необходимость изменения статьи 20-й КоАП он пояснил конституционным запретом цензуры в СМИ, означающей тем самым невозможность «нецензурной» брани. По мнению депутата, вследствие такой коллизии, любой гражданин, изъясняющийся в общественных местах матом или блатным грубым жаргоном, оскорбляющий тем самым человеческое достоинство окружающих, может, сославшись на Конституцию, избежать административного наказания. При этом Николай Губенко отметил пагубные для российского общества тенденции использования ненормативной лексики в художественной литературе, кино, театре, на телевидении и радио, на улице и в быту.
По словам автора, ужесточение ответственности за употребление в общественных местах мата, других бранных слов и жаргона хоть и не изменит кардинально ситуацию, но станет первым маленьким шагом на этом пути, позволит судам правильно применять к нарушителям предписанное статьей 20-й КоАП наказание.
Многие депутаты выразили одобрение и согласие с идеей борьбы с ненормативной лексикой, как в общении людей, так и в СМИ, в литературе и искусстве, но посчитали представленный законопроект не продуктивным, ухудшающим положение дел. Например, по словам Александра Семенникова (фракция «Единая Россия») проблема заключается не в двояком толковании термина «нецензурная» брань, каждый правоприменитель хорошо понимает, что это такое, проблема в плохой работе милиции, когда из-за некачественного составления протоколов об административных правонарушениях дела не доводятся до суда. Именно по этой причине, отметил он, из 10 тысяч составленных протоколов, до рассмотрения в суде доходит сегодня лишь одна десятая их часть. К тому же, для разъяснения ситуации, являются ли использованные нарушителем слова ненормативной лексикой или нет, судьям в каждом отдельном случае придется назначать дорогостоящую экспертизу. По мнению депутата Александра Крутова (фракция «Единая Россия»), замена одного слова другим не даст должного результата, ведь оскорбить можно, выражаясь и нормативной лексикой. Депутат Сергей Митрохин (фракция «ЯБЛОКО – ОБЪЕДИНЕННЫЕ ДЕМОКРАТЫ») считает, что в предложенном законопроекте акцент сделан на борьбе с ненормативной лексикой в СМИ, в искусстве и литературе, и в этом есть опасность для законодателей самим превратиться в цензоров. А речь должна идти о хулиганстве в общественных местах, поэтому необходимо подробно определить, в чем оно заключается, чтобы были правовые основания для привлечения нарушителей к административному наказанию.
Депутат Сергей Митрохин (фракция «ЯБЛОКО – ОБЪЕДИНЕННЫЕ ДЕМОКРАТЫ») считает, что в предложенном законопроекте акцент сделан на борьбе с ненормативной лексикой в СМИ, в искусстве и литературе, и в этом есть опасность для законодателей самим превратиться в цензоров. А речь должна идти о хулиганстве в общественных местах, поэтому необходимо подробно определить, в чем оно заключается, чтобы были правовые основания для привлечения нарушителей к административному наказанию.
По итогам голосования: «за» — 8, «против» — 15, законопроект о внесения изменения в статью 20.1 Кодекса об административных правонарушениях не был принят в первом чтении.
Майя Саламова
Ограничение ненормативного контента в iTunes на ПК
Предостережение относительно радио в интернете. Радиостанции, доступные в iTunes Radio, не созданы компанией Apple. Некоторые из них могут передавать материалы, предназначенные только для взрослой аудитории, например песни с ненормативной лексикой и комедии с темами и ситуациями, не подходящими для детей.
Предостережение относительно iTunes Store. Ниже следует выдержка с веб-сайта консультационной службы Американской ассоциации компаний звукозаписи для родителей. Метка «Родительский контроль» служит предупреждением о том, что записи с этим логотипом могут включать нецензурные выражения или сцены насилия, секса или злоупотребления алкоголем или наркотиками. Родителям рекомендуется принять предостережение во внимание.
Метка «Родительский контроль» не служит достаточным основанием для определения того, подходит ли запись для определенных слушателей. Эта неудаляемая метка скорее служит сигналом предостережения для родителей (потребителей, оптовых и розничных продавцов) при покупке определенных записей для детей или при воспроизведении записей дома.
При определении области применения данной метки имелись в виду следующие возможные проблемы.
В свете современных культурных моральных устоев и стандартов либо в соответствии со своими взглядами и убеждениями отдельные родители могут не захотеть, чтобы их дети услышали эту запись.


Контекст, очевидно, имеет большое значение. Некоторые слова, фразы, звуки или описания могут быть оскорбительными для родителей, если выдвигаются на первый план и подчеркиваются, но могут и не быть таковыми, если просто являются частью фона или незначительной частью слов песни.
Манера подачи материала исполнителем и ожидания публики также имеют значение. При рассмотрении вопроса о применимости метки «Родительский контроль» в конкретной ситуации необходимо учитывать, что запись может содержать не только ругательства, но и сцены насилия, секса или злоупотребления алкоголем или наркотиками.
Текст песен зачастую допускает различную интерпретацию. Слова могут иметь разный смысл. Кроме того, слова нельзя рассматривать в отрыве от музыки, сопровождающей их. Текст, сопровождаемый громкой и шумной музыкой, может восприниматься иначе, чем тот же самый текст, сопровождаемый приятной успокаивающей музыкой.
Выставление меток — это не наука; оно требует продуманности и здравого смысла. Контекст, повторяемость и акцент, очевидно, важны; разрозненных или нечетких ссылок на определенный материал может оказаться недостаточно для гарантированного выставления метки.
Контекст, повторяемость и акцент, очевидно, важны; разрозненных или нечетких ссылок на определенный материал может оказаться недостаточно для гарантированного выставления метки.
Эти рекомендации применимы в случае отдельных дорожек, реализованных на коммерческой основе, а также распространяются на полные альбомы (CD, кассеты или любые другие формы) и видео.
Когда сквернословие может привести к увольнению, а когда нет
На сегодняшних рабочих местах, которые могут показаться более расслабленными и непринужденными, чем в прошлые десятилетия, насколько приемлемо проклинать на работе?
Безусловно уволенный директор по коммуникациям Белого дома Энтони Скарамуччи обнаружил, что это неприемлемо после того, как он использовал ненормативную лексику, чтобы описать коллег репортеру The New Yorker . По словам пресс-секретаря Белого дома Сары Хакаби Сандерс, Скарамуччи оказался без работы на этой неделе после того, как президент Дональд Трамп пришел к выводу, что комментарии «неуместны для человека, занимающего эту должность».
Что составляет допустимую ненормативную лексику на работе, зависит от контекста, в котором ругательства озвучиваются, тона ненормативной лексики, цели ненормативной лексики, аудитории, слушающей или читающей ее, и точных слов, которые используются, эксперты на рабочем месте сказал.
«Работа часто вызывает стресс, разочарование и требует больших затрат, и — в зависимости от культуры вашего места работы — периодическое выражение своих эмоций неприятными словами можно ожидать и терпеть», — сказал Джеймс О’Коннор, основатель Lake Forest. Больной.на базе Cuss Control Academy, цель которой — «повысить осведомленность о негативном влиянии ненормативной лексики на общество и на людей, которые ругаются слишком часто или ненадлежащим образом», согласно веб-сайту академии.
«Это также зависит от того, кто ругается, почему, какие слова используются и кто их слышит. Если босс ругается по какой-либо причине, другие чувствуют себя вправе позволить своему языку летать», — сказал О’Коннор. «Однако ругательства в адрес коллеги могут усилить конфликт. Ругательства перед клиентом могут плохо отразиться на сотруднике и репутации компании.А с хроническими проклятиями, которые ругаются без особой причины и не знают никаких прилагательных, кроме вариаций слова на букву F, работать неинтересно ». перед камерами новостей или журналистами.Публичная тирада ненормативной лексики, направленная на конкретных людей, почти всегда неприемлема, будь то в политике или где-либо еще, говорят эксперты.
«Однако ругательства в адрес коллеги могут усилить конфликт. Ругательства перед клиентом могут плохо отразиться на сотруднике и репутации компании.А с хроническими проклятиями, которые ругаются без особой причины и не знают никаких прилагательных, кроме вариаций слова на букву F, работать неинтересно ». перед камерами новостей или журналистами.Публичная тирада ненормативной лексики, направленная на конкретных людей, почти всегда неприемлема, будь то в политике или где-либо еще, говорят эксперты.
Джон Ф. Келли, новый глава администрации Трампа, уволил Скарамуччи после последнего, в своем разговоре с репортером The New Yorker использовал грубые и непристойные выражения для описания членов президентской администрации, включая Рейнса Прибуса, предшественника Келли, и Стивена К.Бэннон, главный стратег Белого дома.
«Использование Скарамуччи ненормативной лексики выходит за рамки допустимого, в основном из-за публичного характера комментариев», — сказал Джон Челленджер, генеральный директор глобальной аутплейсмента и исполнительной коучинговой фирмы Challenger, Gray & Christmas Inc. язык, тот факт, что он использовал его с репортером, чтобы ударить коллегу, свидетельствует о неуважении и непрофессионализме, и в большинстве компаний может нанести ущерб моральному духу. Это не было случаем конструктивной критики.«
язык, тот факт, что он использовал его с репортером, чтобы ударить коллегу, свидетельствует о неуважении и непрофессионализме, и в большинстве компаний может нанести ущерб моральному духу. Это не было случаем конструктивной критики.«
[Экспресс-запрос только для членов SHRM: Управление политическими дискуссиями ]
« Мы понимаем, что политики, а также высшие руководители имеют разногласия и ругаются, как и все », — сказал О’Коннор, также автор книги Cuss Control: The Complete Book on How to Curb Your Curses (Three Rivers Press, 2000). «Вряд ли кому сегодня наплевать, если вы говорите« черт возьми »или« черт возьми », но это больно, когда вы говорите: «Черт тебя побери» или «Иди к черту».«Когда вы нападаете на кого-то публично … вы производите у многих плохое впечатление».
Когда проклятие может быть нормально
Тем не менее, бывают случаи, когда ненормативная лексика имеет место в работе, — сказал Иегуда Барух, профессор управленческих исследований и директор по исследованиям в компании. бизнес-школа Саутгемптона при Университете Саутгемптона в Великобритании
бизнес-школа Саутгемптона при Университете Саутгемптона в Великобритании
«Есть много вариантов, где использование ненормативной лексики будет хорошо принято коллегами», — сказал Барух, который вместе со своим исследователем Стюартом Дженкинсом изучал ругань на рабочем месте.»Придется воспользоваться редким товаром, который называется здравым смыслом. Например, некоторые ругательства могут вызвать чувство командной культуры и тесной связи. [Проклятия] могут вызвать ощущение срочности и акцента, когда более старший человек разговаривает с ней или его команда.»
Для одного из исследований Баруха и Дженкинса Дженкинс собрал данные, работая временным сотрудником в британской компании по доставке почтовых отправлений, в которой работали 14 рабочих, поровну разделенных между офисом и складом. Они также использовали шесть фокус-групп — четыре на юге США и две в Англии — работников, занятых полный и неполный рабочий день.Студенты составляли большую часть от 10 до 20 человек в каждой фокус-группе.
Больше всего ругательств, которые исследовали исследователи, сообщали работники нижнего уровня организационной иерархии, и они имели место в служебных помещениях или после того, как клиенты ушли; это не происходило перед покупателями или в непосредственной близости от них.
«Если у вас есть клиенты, которые ругаются, у вас может возникнуть соблазн использовать грязные слова, чтобы связаться с ними, но лучше этого не делать», — посоветовал О’Коннор.
Challenger согласен: «Обычно использование ненормативной лексики перед клиентами или клиентами, особенно с теми, с которыми еще не установлены прочные отношения, считается неприемлемым и непрофессиональным.«
Более молодые менеджеры и профессионалы более терпимо относились к проклятиям сотрудников, в то время как руководители ругались реже, как выяснили Барух и Дженкинс.
« По моим исследованиям, даже врачи и юристы используют ненормативную лексику в разговоре между собой », — сказал Барух. помогает, например, снять стресс. Пол может быть проблемой; мы обнаружили, что женщины чаще используют ненормативную лексику, когда это полностью женская среда, но будут менее склонны делать это в смешанных командах ».
Пол может быть проблемой; мы обнаружили, что женщины чаще используют ненормативную лексику, когда это полностью женская среда, но будут менее склонны делать это в смешанных командах ».
Наконец, исследователи обнаружили, что ругань может быть ценным выпускным клапаном на рабочих местах с высоким уровнем стресса. .«Пока сотрудники ругаются, они могут быть недовольны, но они справляются», — написали они в своем исследовании.
Однако они подчеркнули, что оскорбительные и оскорбительные ругательства должны быть устранены там, где они вызывают, а не снимают стресс. Неоднократные ругательства, угрозы и словесные оскорбления «могут привести к депрессии, стрессу, снижению морального духа, прогулам, проблемам с удержанием [и] снижению производительности [и могут] повредить имидж организации», — писали они.
Правила использования ненормативной лексики на рабочем месте?
Следует ли компаниям писать правила о проклятии на работе?
О’Коннор сказал, что это было бы «излишним и практически невозможно». «
«
« Некоторые слова хуже других », — сказал он, но не все согласны с тем, что это за слова.« Вы не можете быть конкретным или составить список запрещенных слов, терпимых слов или ситуаций, в которых могут быть смешно, если сказано неожиданным или легким тоном ».
Челленджер сказал, что большинство отделов кадров могут бороться с проклятиями, просто включив в свою политику уважение к коллегам. Вместо того, чтобы писать официальную политику о ненормативной лексике, сказал он,« это, скорее всего, лучше. и более эффективно решать вопросы, связанные с грубым языком, в каждом конкретном случае.
«Если работник чувствует неуважение или угрозу из-за языка, HR должен вмешаться. Но случайная ругань, не оказывающая какого-либо неблагоприятного воздействия на условия ведения бизнеса, отношения с коллегами или обслуживание клиентов или клиентов, вероятно, не является причиной для вмешательства HR. . »
Была ли эта статья полезной? SHRM предлагает тысячи инструментов, шаблонов и других эксклюзивных преимуществ для участников, включая обновления соответствия, образцы политик, советы специалистов по кадрам, скидки на обучение, растущее онлайн-сообщество участников и многое другое.
 Присоединяйтесь / продлите сейчас и позвольте SHRM помочь вам работать эффективнее.
Присоединяйтесь / продлите сейчас и позвольте SHRM помочь вам работать эффективнее. Непристойные, непристойные и непристойные передачи
Федеральный закон запрещает трансляцию непристойного, непристойного и непристойного содержания по радио или телевидению. Это может показаться достаточно ясным, но определить, что означает непристойное, непристойное и непристойное, может быть сложно, в зависимости от того, с кем вы разговариваете.
В историческом деле Верховного суда 1964 года о непристойности и порнографии судья Поттер Стюарт написал знаменитую фразу: «Я узнаю это, когда вижу.«Этот случай по-прежнему влияет на правила Федеральной комиссии по связи и сегодня, и жалобы общественности на трансляцию нежелательного контента требуют соблюдения этих правил.
Другими словами, если вы «знаете это, когда видите» и находите это нежелательным, вы можете сообщить об этом в FCC и попросить нас проверить это.
Решить, что непристойно, неприлично или непристойно
У каждого типа контента есть свое определение:
Непристойное содержание не защищено Первой поправкой.Чтобы контент был признан непристойным, он должен соответствовать трем критериям, установленным Верховным судом: он должен апеллировать к похотливым интересам обычного человека; изображать или описывать сексуальное поведение «явно оскорбительным» образом; и в целом не имеют серьезной литературной, художественной, политической или научной ценности.
Непристойное содержание изображает сексуальные или выделительные органы или действия явно оскорбительным образом, но не отвечает трехстороннему критерию непристойности.
Нецензурное содержание включает в себя «крайне оскорбительные» выражения, которые считаются нарушением общественного порядка.
Факторы, определяющие, как применяются правила FCC, включают особый характер контента, время суток, когда он транслировался, и контекст, в котором происходила трансляция.
Трансляция непристойного содержания запрещена законом в любое время суток. Непристойный и непристойный контент запрещен в эфире телевидения и радио с 6 утра до 10 вечера, когда существует разумный риск того, что дети могут оказаться в аудитории.
А как насчет кабельного, спутникового телевидения и спутникового радио?
Поскольку непристойность не защищена Первой поправкой, она запрещена на кабельном, спутниковом и радиовещательном телевидении и радио.Однако те же правила неприличия и ненормативной лексики не применяются к кабельному, спутниковому телевидению и спутниковому радио, поскольку они являются услугами подписки.
Обеспечение соблюдения правил
Обеспечение соблюдения правил непристойности, непристойности и ненормативной лексики обычно начинается с жалоб общественности, которые сотрудники FCC рассматривают на предмет возможных нарушений. Если расследование является оправданным и FCC обнаруживает, что станция нарушает свои правила, она имеет право отозвать лицензию на станцию, наложить штраф или вынести замечание или предупреждение.
Что делать, если у меня есть комментарии или сомнения по поводу конкретной трансляции?
Все комментарии и / или опасения по поводу конкретной трансляции следует направлять участвующим станциям и сетям.
Какую информацию я должен включить в жалобу на непристойность, непристойность или ненормативную лексику в FCC?
При подаче жалобы укажите следующую информацию:
- Дата и время трансляции.
- Позывной, канал и / или частота станции.
- Подробная информация о том, что на самом деле было сказано или изображено во время трансляции.
Подробные жалобы полезны для анализа контекста ненормативной лексики, изображений или сцен и определения возможных нарушений правил. Также полезно (но не обязательно) включать запись или стенограмму трансляции, когда это возможно, хотя любая предоставленная вами документация становится частью записей FCC и не может быть возвращена.
Версия для печати
Непристойные, непристойные и непристойные передачи (pdf)
leo-ненормативная лексика — npm
Фильтр ненормативной лексики на основе словаря Shutterstock
Установка
// нпм
npm install leo-ненормативная лексика
npm install leo-profanity --no-optional # установить только английский словарь плохих слов
// пряжа
пряжа добавить лев-ненормативную лексику
yarn add leo-profanity --ignore-optional # установить только английский словарь плохих слов
// Беседка
bower install leo-ненормативная лексика
// словарь / по умолчанию. json
 json
json
Пример использования для npm
// поддержка языков
// - ru
// - fr
var filter = require ('leo-ненормативная лексика'); filter.loadDictionary (строка)
// заменяем текущий словарь французским
filter.loadDictionary ('fr');
// заменяем словарь на словарь по умолчанию (аналогично filter.reset ())
filter.loadDictionary (); filter.list ()
// вернуть все ненормативную лексику (Array.string) filter.list ();
filter.check (строка)
Узнайте больше о фильтрах.чистый
// вывод: истина
filter.check ('У меня грудь'); filter.clean (строка, [replaceKey = *])
// нет плохого слова
// вывод: у меня 2 глаза
filter.clean («У меня 2 глаза»);
// нормальный случай
// вывод: у меня **** и т. д.
filter.clean («У меня грудь и т. д.»);
// деликатный случай
// вывод: у меня есть ****
filter.clean ('У меня есть BoOb');
// через запятую и точку
// вывод: у меня ****.
filter.clean ('У меня есть BoOb.');
// многократное появление
// вывод: у меня есть ****, ****, *** и т. д.filter.clean ('У меня есть грудь, грудь, задница и т. д.');
// не должно обнаруживать слово без пробелов
// output: Купить классические часы онлайн
filter.clean ('Купить классические часы в Интернете');
// очистка с помощью специального символа замены
// вывод: у меня ++++
filter.clean ('У меня грудь', '+');
// поддерживаем "четкую букву" в начале слова
// вывод: у меня бо ++
filter.clean ('У меня грудь', '+', 2);  filter.clean ('У меня есть BoOb.');
// многократное появление
// вывод: у меня есть ****, ****, *** и т. д.filter.clean ('У меня есть грудь, грудь, задница и т. д.');
// не должно обнаруживать слово без пробелов
// output: Купить классические часы онлайн
filter.clean ('Купить классические часы в Интернете');
// очистка с помощью специального символа замены
// вывод: у меня ++++
filter.clean ('У меня грудь', '+');
// поддерживаем "четкую букву" в начале слова
// вывод: у меня бо ++
filter.clean ('У меня грудь', '+', 2);
filter.clean ('У меня есть BoOb.');
// многократное появление
// вывод: у меня есть ****, ****, *** и т. д.filter.clean ('У меня есть грудь, грудь, задница и т. д.');
// не должно обнаруживать слово без пробелов
// output: Купить классические часы онлайн
filter.clean ('Купить классические часы в Интернете');
// очистка с помощью специального символа замены
// вывод: у меня ++++
filter.clean ('У меня грудь', '+');
// поддерживаем "четкую букву" в начале слова
// вывод: у меня бо ++
filter.clean ('У меня грудь', '+', 2); filter.add (строка | Array.string)
// добавляем слово
filter.add ('b00b');
// добавляем массив слов
// автоматическая проверка дублирования
фильтр.добавить (['b00b', 'b @@ b']); filter.remove (строка | Array.string)
// удалить слово
filter.remove ('b00b');
// удаляем массив слов
filter.remove (['b00b', 'b @@ b']); filter.reset ()
Сбросить список слов с помощью словаря по умолчанию (также удалить слово, добавленное вручную)
filter.
 clearList ()
clearList ()Удалить ненормативную лексику
Алгоритм
В этом проекте решено разделить его на 2 части: Sanitize и Filter .
а вот эти ниже интересные алгоритмы.
Продезинфицировать
Попытка 1 (1.1): преобразовать все в нижнюю строку
Преимущество:
- просто
Недостаток:
- никто
Попытка 2 (1.2): преобразовать символ «подобное подобное» в алфавит
например преобразовать `@` в `a`,` 5` и `$` в `s`
Преимущество:
- простой + определить какое-нибудь хитрое слово (например, @ss, b00b)
Недостаток:
- "ложно положительный"
- ограничить воображение пользователя (пользователь не может играть словами)
например [email protected]
например пользователь хочет попробовать что-нибудь забавное, например "a $$ a $$ in"
Попытка 3 (1.3): заменить `.`и`, `с пробелом для разделения слов
в некоторых предложениях люди обычно используют `.` и`, `для соединения / завершения предложения
Преимущество:
- увеличить возможность основания
например Мне нравится a55, b00b
Недостаток:
- никто
Фильтр
Попытка 1 (2. 1): разбить на массив (или каким-то образом с использованием регулярного выражения)
используя пробел, чтобы разбить его на массив, затем проверьте список ненормативной лексики
Преимущество:
- просто
Недостаток:
- нужен правильный список
- некоторые «ложные срабатывания»
например Большая синица (https: // en.wikipedia.org/wiki/Great_tit)
Попытка 2 (2.2): отфильтровать слово внутри (с пробелом или без)
определить весь алфавит, содержащий «ненормативную лексику» (например, `thistextisfunnyboobsanda55`)
Преимущество:
- просто
- может обнаружить ненормативную лексику без пробелов
Недостаток:
- много «ложных срабатываний»
например http://www.morewords.com/contains/ass/
например Ошибка Clbuttic (ошибка фильтра)
 1): разбить на массив (или каким-то образом с использованием регулярного выражения)
используя пробел, чтобы разбить его на массив, затем проверьте список ненормативной лексики
Преимущество:
- просто
Недостаток:
- нужен правильный список
- некоторые «ложные срабатывания»
например Большая синица (https: // en.wikipedia.org/wiki/Great_tit)
Попытка 2 (2.2): отфильтровать слово внутри (с пробелом или без)
определить весь алфавит, содержащий «ненормативную лексику» (например, `thistextisfunnyboobsanda55`)
Преимущество:
- просто
- может обнаружить ненормативную лексику без пробелов
Недостаток:
- много «ложных срабатываний»
например http://www.morewords.com/contains/ass/
например Ошибка Clbuttic (ошибка фильтра)
1): разбить на массив (или каким-то образом с использованием регулярного выражения)
используя пробел, чтобы разбить его на массив, затем проверьте список ненормативной лексики
Преимущество:
- просто
Недостаток:
- нужен правильный список
- некоторые «ложные срабатывания»
например Большая синица (https: // en.wikipedia.org/wiki/Great_tit)
Попытка 2 (2.2): отфильтровать слово внутри (с пробелом или без)
определить весь алфавит, содержащий «ненормативную лексику» (например, `thistextisfunnyboobsanda55`)
Преимущество:
- просто
- может обнаружить ненормативную лексику без пробелов
Недостаток:
- много «ложных срабатываний»
например http://www.morewords.com/contains/ass/
например Ошибка Clbuttic (ошибка фильтра)
Сводка
- Мы не знаем всех методов, с помощью которых можно произвести ненормативную лексику (например, сколькими способами можно ввести a55?)
- Для этого есть подход, не основанный на алгоритмах (пока)
- Люди всегда найдут способ связаться друг с другом
(е. грамм. Leet)
 грамм. Leet)
грамм. Leet)Итак, этот проект решил использовать версии 1.1, 1.3 и 2.1. (* примечание — другие попытки вы можете найти в разделе «Справочная информация»)
TODO
- [x]
добавитьметод - [] Фильтр синтаксиса html
- [] Поддержка нескольких языков
- [x] Complete
cleanAPI - [x] Увеличить процент покрытия кода
- [x] Исправить ESLint
- [] Демонстрационная страница
- [] Больше словарный словарь
- []
setDictionaryфункция - [] Инкапсулировать частную функцию
- [] По алфавиту
- [] Сортировать по длине
- [] Выпустить новую версию в соответствии с
loadDictionary+ французские слова - [] Выпуск API завершен,
getDictionary - [] Модульный тест
продолжитьметод - [] Модульный тест
badWordsUsedметод - [x] Сделать другие словари необязательными (только английский язык является обязательным)
Другие языки
Внесите
- Вилка репо
- Установите Node. js и зависимости
- Создайте ветку для своего изменения и внесите свои изменения
- Запустите
git add -A, чтобы добавить свои изменения - Выполнить
npm run commit(не использоватьgit commit) - Отправьте свои изменения с помощью
git push, затем создайте запрос на слияние
 js и зависимости
js и зависимостиПожертвовать собственнику
$ npm install -g semantic-release-cli
Настройка $ semantic-release-cli
Используя указанную выше команду для настройки "семантического релиза"
Статистика
Номер ссылки
A Long и #% @ & $ История: NPR
Иногда нужно следить за маленьким правительством.Возьмем, к примеру, Миддлборо, штат Массачусетс, городское собрание которого недавно наложило штраф в размере 20 долларов за публичные ругательства. По словам начальника полиции, постановление было направлено против толпы неуправляемых подростков, которые собирались в центре города по ночам и выкрикивали ненормативную лексику в адрес людей, а не только против тех, кто хлопает пальцем в дверце машины. Но какой бы ни была точная идея, никто не считал ее хорошей. Это постановление было осуждено комментаторами Fox News, редакционными авторами The Washington Post, и директором Массачусетского ACLU.Есть некоторые люди, которые хотят, чтобы правительство не появлялось на рынке, и некоторые люди, которые хотят, чтобы оно не попадало в спальню, но почти все напуганы тем, что оно контролирует то, что мы говорим соседу, который запускает свою воздуходувку для листьев в 7:15 в воскресенье утром.
Но какой бы ни была точная идея, никто не считал ее хорошей. Это постановление было осуждено комментаторами Fox News, редакционными авторами The Washington Post, и директором Массачусетского ACLU.Есть некоторые люди, которые хотят, чтобы правительство не появлялось на рынке, и некоторые люди, которые хотят, чтобы оно не попадало в спальню, но почти все напуганы тем, что оно контролирует то, что мы говорим соседу, который запускает свою воздуходувку для листьев в 7:15 в воскресенье утром.
Но на этом консенсус и закончился, поскольку комментарии перешли к противостоянию культурной войны между моралистами и модернистами. Для моралистов повсеместное распространение ругани — явный симптом крушения вежливости и огрубления американской культуры.По их словам, распад начался с сквернословящих демонстрантов и хиппи 60-х и был усилен Голливудом, рок-музыкой и хип-хопом, превратив нас в общество, утратившее всякое чувство стыда и стигмы.
Это старая мелодия. Социальные критики в 1940-х осуждали неконтролируемую ненормативную лексику вернувшихся солдат. В 20-х годах они критиковали моду на четырехбуквенные слова среди светских трущоб, которых называли ублюдками, благовоспитанными молодыми людьми, которые, как выразился один критик, чувствовали необходимость «подражать манерам и языку грузчика».И так далее, вплоть до викторианцев, чьи проповеди и уставы были полны ссылок на публичную ненормативную лексику. Но, как заметил философ Монтескье, люди жаловались на упадок нравов и морали со времен Горация и Аристотеля. Он сказал, что они не все были правы, иначе сегодня медведями были бы люди.
В 20-х годах они критиковали моду на четырехбуквенные слова среди светских трущоб, которых называли ублюдками, благовоспитанными молодыми людьми, которые, как выразился один критик, чувствовали необходимость «подражать манерам и языку грузчика».И так далее, вплоть до викторианцев, чьи проповеди и уставы были полны ссылок на публичную ненормативную лексику. Но, как заметил философ Монтескье, люди жаловались на упадок нравов и морали со времен Горация и Аристотеля. Он сказал, что они не все были правы, иначе сегодня медведями были бы люди.
Моралисты правы в одном: этот язык стал более распространенным и более слышимым, чем когда-либо с начала 19 века.Я бы положил поворотный момент в 70-е, когда стили и взгляды, возникшие в 60-е, были приручены и лишены какого-либо подрывного значения — момент, когда джинсы, длинные волосы и повседневная пошлость стали универсальными признаками демократической неформальности.
Но модернист может возразить, что повсеместное распространение четырехбуквенной болтовни на самом деле делает ее менее серьезной. В статье, критикующей постановление Миддлборо, лингвист Джон Маквортер сказал, что пора привести наше чувство «грязного» в соответствие с нашим современным американским духом.Правда, есть одно-два действительно запретных слова. Но остальная часть этого языка стала настолько обыденной, что она не профана, а просто красочна. Просто убедитесь, что дети учатся не использовать его в неподходящее время, точно так же, как они должны научиться не отрыгивать на публике.
В статье, критикующей постановление Миддлборо, лингвист Джон Маквортер сказал, что пора привести наше чувство «грязного» в соответствие с нашим современным американским духом.Правда, есть одно-два действительно запретных слова. Но остальная часть этого языка стала настолько обыденной, что она не профана, а просто красочна. Просто убедитесь, что дети учатся не использовать его в неподходящее время, точно так же, как они должны научиться не отрыгивать на публике.
Это модернистская точка зрения: горшки похожи на выбоины, просто еще одно небольшое неудобство жизни. Они там, ругаются, привыкните. Эта бескомпромиссная рациональность может показаться далекой от пылкой филиппики моралистов.Тем не менее, большинство из нас легко переключаются с одной позиции на другую. Просто обратите внимание на реакцию, когда политический деятель ловится на падении F-бомбы. Для оппозиции бессмысленные разговоры показывают его бесклассовую принадлежность. Для его собственных сторонников это «демонстрация земной подлинности». А когда через неделю кто-то с другой стороны использует то же слово, обе стороны просто обмениваются своими копиями.
А когда через неделю кто-то с другой стороны использует то же слово, обе стороны просто обмениваются своими копиями.
Но каждая точка зрения имеет свою привлекательность. Моралисты правы. Вульгарный язык может быть фактом современной жизни, но он вызывает больше беспокойства, чем ухабы.Приятно слышать, как кто-то позади вас в очереди фильма энергично ругается, даже если у вас нет шестилетнего ребенка на буксире. В одном из недавних опросов три четверти респондентов заявили, что родители должны учить своих детей тому, что «ругать всегда неправильно». Но не многие родители преподают этот урок своим примером. Доля американцев, утверждающих, что никогда не ругает, колеблется от 5 до 15 процентов, и вы полагаете, что некоторые из них, должно быть, говорят правду. Но в то время как остальные из нас могут официально не одобрять ругань, мы также занимаемся этим с энтузиазмом — и даже, к сожалению, за семейным обеденным столом devant les enfants .
У вас не может быть ненормативной лексики, если не осталось ханжей, которых она шокировала бы.
Ну, ненормативная лексика делает всех нас лицемерами. Но как может существовать ненормативная лексика без лицемерия? Чтобы узнать, что значит ругаться, ребенок должен услышать сказанные слова и услышать, что их произносить неправильно, в идеале от одних и тех же людей. В конце концов, основной смысл ругани — продемонстрировать, что ваши эмоции взяли верх над вами и превзошли все ваши запреты.Вот почему слова следует рассматривать как плохие, а не просто неуместные, поэтому их использование имеет большой вес. Нецензурные слова не описывают ваши чувства; они их проявляют. Подбрасывание слова на букву «F» — это не просто особенно красочный и выразительный способ сказать: «Я ужасно зол на тебя прямо сейчас», не больше, чем «Ой!» это просто выразительный способ сказать: «Господи, больно».
В конце концов, ни модернисты, ни моралисты никогда не смогут выиграть спор. Каждый слишком сильно нуждается в другом.Конкретные словарные элементы могут со временем меняться, но ругань никогда не станет настолько обычным явлением, чтобы мы перестали считать ее непослушной.![]() У вас не может быть ненормативной лексики, если не осталось ханжей, которых она могла бы шокировать. Давайте воздадим должное добрым людям из Мидлборо, штат Массачусетс, за то, что они помогли сохранить старые традиции.
У вас не может быть ненормативной лексики, если не осталось ханжей, которых она могла бы шокировать. Давайте воздадим должное добрым людям из Мидлборо, штат Массачусетс, за то, что они помогли сохранить старые традиции.
Метод обнаружения ненормативной лексики с использованием встраивания слов и LSTM
С ростом числа пользователей Интернета наблюдается быстрый рост киберзапугивания.Среди видов киберзапугивания словесные оскорбления становятся наиболее серьезной проблемой, для предотвращения которой нецензурная лексика выявляется и блокируется. Однако пользователи ловко используют слова, чтобы избежать блокировки. Существующие методы распознавания ненормативной лексики позволяют с высокой точностью распознавать умышленные опечатки и ненормативную лексику с использованием специальных символов. Однако, поскольку они не могут понять значение слов и последовательность предложений, стандартные слова, такие как «Sibaljeom» (отправная точка, корейское слово, которое звучит похоже на ругательство) »и« Saekkibalgalag »(мизинец, корейское слово, которое звуки, похожие на другое нецензурное слово) »распознаются менее точно. Поэтому для решения этой проблемы в этом исследовании предлагается метод распознавания ненормативной лексики с использованием модели глубокого обучения, которая может уловить значение и контекст слов после разделения хангыль на начало, ядро и код.
Поэтому для решения этой проблемы в этом исследовании предлагается метод распознавания ненормативной лексики с использованием модели глубокого обучения, которая может уловить значение и контекст слов после разделения хангыль на начало, ядро и код.
1. Введение
Киберзапугивание означает преступное деяние, которое причиняет моральный и материальный вред другим путем многократного использования враждебных выражений, таких как текст, изображения и голоса, в сети через ИТ-устройства, включая компьютеры [1]. В последнее время возраст преступников киберзапугивания постепенно снижается из-за распространения умных устройств.Такие преступники не осознают, что киберзапугивание является преступлением, и проявляют безрассудство, считая это простой игрой [2]. Кроме того, известны случаи самоубийств жертв киберзапугивания, что превращает их в серьезную социальную проблему [3]. Согласно представленной Комиссией по коммуникациям презентации результатов расследования киберзапугивания за 2019 год, типичные типы кибербуллинга включают кибер словесные оскорбления, кибер-клевету, киберпреследование, кибер-сексуальные домогательства, утечку личной информации, социальную изоляцию в Интернете, кибер-вымогательство и киберпреступление [4]. Среди них самый высокий процент кибер-словесных оскорблений — 36,7% [5–7]. Чтобы предотвратить кибер-словесные оскорбления, правительство заблокировало некоторые приговоры, связанные с ненормативной лексикой [8]. Однако пользователи Интернета изменяют ядро слова, чтобы избежать блокировки или использования новой ненормативной лексики [9], даже если ненормативная лексика изменяется соответствующим образом. Для точного определения ненормативной лексики проводится множество исследований. В настоящее время можно распознавать умышленные опечатки и ненормативную лексику с использованием специальных символов. Однако, если значение слов и последовательность предложений не понятны, стандартные слова, такие как «Sibaljeom (отправная точка, корейское слово, которое звучит похоже на ругательство)» и «Saekkibalgalag» (мизинец, корейское слово, которое звучит похоже на другое нецензурное слово) »менее точно определены как нечестивые.Таким образом, в этом исследовании мы пытаемся точно идентифицировать ненормативную лексику в следующих двух случаях: (1) когда пользователи Интернета используют ненормативную лексику, изменяя ядро слова, чтобы его не блокировали как ненормативную лексику, и (2) когда морфология слова является ненормативной.
Среди них самый высокий процент кибер-словесных оскорблений — 36,7% [5–7]. Чтобы предотвратить кибер-словесные оскорбления, правительство заблокировало некоторые приговоры, связанные с ненормативной лексикой [8]. Однако пользователи Интернета изменяют ядро слова, чтобы избежать блокировки или использования новой ненормативной лексики [9], даже если ненормативная лексика изменяется соответствующим образом. Для точного определения ненормативной лексики проводится множество исследований. В настоящее время можно распознавать умышленные опечатки и ненормативную лексику с использованием специальных символов. Однако, если значение слов и последовательность предложений не понятны, стандартные слова, такие как «Sibaljeom (отправная точка, корейское слово, которое звучит похоже на ругательство)» и «Saekkibalgalag» (мизинец, корейское слово, которое звучит похоже на другое нецензурное слово) »менее точно определены как нечестивые.Таким образом, в этом исследовании мы пытаемся точно идентифицировать ненормативную лексику в следующих двух случаях: (1) когда пользователи Интернета используют ненормативную лексику, изменяя ядро слова, чтобы его не блокировали как ненормативную лексику, и (2) когда морфология слова является ненормативной. похож на ненормативную лексику, но является стандартным языком, который не является непристойным в контексте. Чтобы повысить точность распознавания ненормативной лексики, мы предлагаем метод распознавания ненормативной лексики с использованием модели FastText для встраивания слов путем изучения информации о значении и форме слов и модели LSTM для изучения потока контекста.
похож на ненормативную лексику, но является стандартным языком, который не является непристойным в контексте. Чтобы повысить точность распознавания ненормативной лексики, мы предлагаем метод распознавания ненормативной лексики с использованием модели FastText для встраивания слов путем изучения информации о значении и форме слов и модели LSTM для изучения потока контекста.
2. Сопутствующие работы
2.1. Обработка естественного языка
Естественным языком называется язык, который формировался и развивался естественным образом в течение длительного периода, например корейский и английский, на котором обычно говорят и используют [10]. Обработка естественного языка анализирует значение естественного языка, чтобы компьютеры могли его обрабатывать. Обработка естественного языка применяется в таких областях, как классификация текста, анализ тональности, обобщение и кластеризация текста [11, 12].Эта обработка включает четыре этапа: сбор текста, предварительная обработка текста, встраивание слов и моделирование машинного обучения [13, 14].
На первом этапе (сбор текста) собираются тексты для обработки. Второй шаг (предварительная обработка текста) включает стандартизацию неструктурированных текстов для повышения точности обработки естественного языка. Текст, собранный из социальных сетей, содержит множество элементов, которые сложно анализировать, например опечатки, смайлики, сокращения и недавно придуманные слова.Большинство выражается так, будто говорит беззаботно, в терминах словарного запаса или структурного порядка предложения. Поэтому после обработки текста, включая изменение верхнего регистра на нижний, удаление специальных символов и смайликов, а также нормализацию текста, такую как токенизация слова и удаление стоп-слова, предварительная обработка выполняется в соответствии с требованиями. На третьем этапе (встраивание слов) слова преобразуются в векторы, чтобы компьютеры могли эффективно понимать и обрабатывать естественный язык.В этом исследовании мы используем модель FastText, в которой встраивание слов выполняется путем обучения с использованием информации о морфологии корейских букв среди нескольких моделей. Наконец, на этапе моделирования машинного обучения устанавливается модель обучения с учителем, а обучение и прогнозирование выполняются с использованием векторизованных данных числового типа. В этом исследовании мы используем модель LSTM для обучения и прогнозирования, а также для обнаружения ненормативной лексики.
2.2. Алгоритм внедрения
Чтобы компьютер мог эффективно понимать и обрабатывать естественный язык, язык должен быть преобразован в числа, которые могут обрабатываться компьютером.Поскольку производительность обработки естественного языка значительно варьируется в зависимости от представления слов, преобразование слов в числовые типы широко изучается. Среди них обычно используется метод встраивания слов, который представляет слово как плотный вектор [15]. Способы представления слова вектором включают разреженное представление и плотное представление. Одноразовое кодирование — это метод представления вектора с разреженным представлением. Значение вектора, выраженное в резервном представлении, в основном включает число «0», а количество измерений равно количеству слов, которые нужно обучить.Однако, поскольку разреженное представление включает в себя столько же измерений, сколько количество слов для обучения, значительное пространство тратится впустую, и значение слов не может быть надлежащим образом представлено. В последнее время появилось несколько алгоритмов, которые представляют векторы посредством плотного представления, улучшая указанные выше недостатки [16]. При плотном представлении размерность вектора может быть сопоставлена с числами, установленными пользователем, а векторы, называемые плотными векторами, имеют действительные значения [16]. Как указано в концепции, вложение слов относится к способу представления слов в виде плотных векторов [17].Типичные модели алгоритмов, которые могут принимать встраивание слов, включают Word2Vec [15], GloVe [18] и FastText. Модель Word2Vec представляет слова в векторном пространстве посредством распределенного представления с использованием их семантики и синтаксических характеристик. Однако эта модель невыгодна, потому что векторные значения не могут быть получены для OOV, и обучение невозможно для нечастых слов [19–21]. В модели FastText обучение выполняется путем разделения слов на уровни символов, чтобы дополнить такие ограничения.Как и в случае с моделью Word2Vec, модель FastText исследует предыдущий и последующий контексты со ссылкой на целевое слово и выполняет обучение на словах; однако, поскольку она также изучает слова, разделяя их на уровень символов, модель также может быть обучена на информации о морфологии слова. Обучение модели FastText выполняется путем представления слов с помощью модели «мешок слов» (BoW) или модели n-грамм. В начале и в конце слов, которые нужно выучить, в качестве разделителей вставляется «<», «>», и все слово также содержится в BoW с разделителем, чтобы модель могла усвоить общее значение [22].Новая функция оценки, использующая BoW, определяется следующим образом: где — вектор словообразовательного контекста, а — вектор, соответствующий 1 BoW.
С указанным выше изменением модели он может изучать информацию о семантике, синтаксисе и морфологии целевых слов [23]. В этом исследовании для более эффективного обучения модели FastText на морфологической информации, соответствующей характеристикам корейских букв, каждое слово делится на начало, ядро и код для анализа. В случае отсутствия кода добавляется символ «-».
2.3. Модель LSTM
Модель LSTM — это модель, разработанная для решения проблемы долгосрочной зависимости RNN. LSTM использует коммутационное устройство, предназначенное для того, чтобы вы могли забыть предыдущую информацию или хранить информацию в течение длительного периода времени через ячейку памяти, которая является внутренним узлом:
Комбинация входного значения () в тот же момент времени и скрытого узла value () в предыдущий момент времени используется для вычисления кандидата внутреннего хранилища (), а кандидат узла хранения объединяется со значением узла хранения () в предыдущий момент времени и вычисляет текущее значение () внутреннего хранилища узел.В это время входной вентиль () и вентиль забывания () действуют как веса, чтобы настроить, как передается новая информация и как информация передается в значение в предыдущем состоянии. Наконец, используя функцию tanh valid, значение скрытого узла выводится путем настройки того, как передать значение текущего внутреннего узла хранения с помощью output gate (). Значение каждого входного элемента, выходного элемента и элемента забывания представлено комбинацией линейной функции входного значения в текущий момент времени и значения секретного узла в предыдущий момент времени [24].
3. Обнаружение ненормативной лексики с помощью встраивания слов и LSTM
3.1. Системная архитектура
На рисунке 1 показана системная архитектура предлагаемого метода обнаружения ненормативной лексики, который разделен на процесс обучающих данных, который обучает данные, и процесс данных тестирования, который обнаруживает ненормативную лексику в текстах, написанных пользователями.
В процессе обучения данных модель обучается обнаружению ненормативной лексики. Этот процесс включает в себя предварительную обработку, обучение модели FastText и обучение модели LSTM.На этапе предварительной обработки текста выполняется нормализация собранных текстов, и для того, чтобы включить информацию о морфологии хангыля в обучение модели FastText, каждый символ делится на начало, ядро и код. Следовательно, модель FastText обучается с использованием таких разделенных текстовых данных. Обученная модель FastText содержит векторную информацию текстовых данных, а встраивание слов выполняется в текстовые данные с использованием векторной информации. На этапе обучения модели LSTM выполняется контролируемое обучение двоичной классификации, чтобы определить, содержит ли предложение ненормативную лексику.При обучении модели LSTM сначала проверяется наличие ненормативной лексики в предложении и выполняется разметка, где «1» присваивается предложению с ненормативной лексикой, а «0» — предложению без ненормативной лексики. Далее обучение выполняется по числовым данным с встраиванием слов.
В процессе тестирования данных, когда вводится предложение, модель определяет наличие ненормативной лексики и выдает результат. Для прогнозирования результатов с помощью обученной модели формат данных должен быть таким же, как и при обучении.Следовательно, тот же этап предварительной обработки текста, который выполняется в процессе обучающих данных, повторяется, и на этапе внедрения слова прогнозируется ненормативная лексика с использованием модели LSTM. В прогнозируемом результате «0» указывает предложение без ненормативной лексики, а «1» указывает на предложение с ненормативной лексикой.
3.2. Предварительная обработка и встраивание слов
В этом разделе подробно описывается (1) этап предварительной обработки, который облегчает компьютерный анализ текстов, собранных из обзоров фильмов Twitter и Naver, и (2) этап встраивания слов с использованием модели FastText.
3.2.1. Предварительная обработка текста
Сначала удалите специальные символы и смайлики. Текстовые данные были собраны из сообщений в Twitter и обзоров фильмов Naver. Многие из собранных данных начинались со специальных символов, смайлов, «kieukkieukkieukkieuk (LOL)» и «@», и такие тексты были удалены, поскольку они препятствуют обнаружению ненормативной лексики.
Во-вторых, удалите один слог. Что касается межсловного интервала, собранные предложения содержали множество односложных слов, таких как «геос (вещь)», «а (ах)», «геу (то)», «тто (снова)» и «я (это ).«При изучении этих односложных слов было установлено, что во многих случаях эти слова были набраны из-за ошибок в межсловном интервале, когда пользователь писал сообщения; кроме того, не было односложной ненормативной лексики. Учитывая эти аспекты, из анализа были исключены односложные слова.
В-третьих, удалите предложения, содержащие менее пяти слов. Тексты, собранные в Твиттере, содержали много предложений, в которых не было должного интервала между словами, например, предложение «nunapaije lenjeuppaenda (я вынимаю линзу, потому что у меня болят глаза, написано без интервала).«Предварительная обработка может быть выполнена, только зная правила предложений, в которых нет правильного интервала. Исследование правил составления предложений показало, что в этих предложениях было меньше слов по сравнению с обычными предложениями, когда количество слов подсчитывалось с учетом интервалов. Кроме того, для обучения модели LSTM необходимо настроить количество слов во всех предложениях; предложения с меньшим количеством слов должны быть заполнены «0», в результате чего в предложениях будет много «0».Поэтому предложения, содержащие менее пяти слов, были удалены путем предварительной обработки. Тем самым была реализована высокая точность обнаружения ненормативной лексики.
В-четвертых, начало, ядро и код разделены. В этом исследовании модель FastText была обучена после разделения хангыль на начало, ядро и код, чтобы обеспечить обнаружение ненормативной лексики, даже когда пользователь намеренно делает опечатку и изменяет морфологию ненормативной лексики. Здесь отсутствие кода обозначено добавлением «-». В таблице 1 представлен исходный код, который разделяет начало, ядро и код.
|
3.2.2. Встраивание слов с использованием модели FastText
Предварительно обработанные текстовые данные использовались для обучения модели FastText.Это обучение проводилось со скип-граммом, скорость обучения 0,05, размерность (векторное пространство) 100, размер окна 5, эпоха 50 и n-грамм 1–6. Как показано в таблице 2, в результате обучения подстроки символьных векторов формируются с помощью n-граммы, а строки символьных векторов формируются путем добавления подстрок символьных векторов.
| |||||||||||||||||||
В модели FastText строки символьных векторов формируются путем добавления подстрок символьных векторов; аналогично морфологическая информация используется для обучения. Модель FastText, обученная на основе этого метода, генерирует вектор, похожий на слово до его изменения, даже если изменяется ядро слова.
3.3. Обнаружение ненормативной лексики с помощью LSTM
3.3.1.Конфигурация набора данных для обучения LSTM
Для проведения контролируемого обучения с моделью LSTM необходимо выполнить встраивание слов, в котором данные отображаются в векторы, для чего можно использовать обученную модель FastText. Как показано в таблице 3, предложение состоит из нескольких слов в зависимости от интервала, и слово становится одномерным вектором при векторизации с использованием обученной модели FastText.
| ||||||||||||||||||
В этом случае количество векторов для одного слова устанавливается как значение измерения, когда обучение модели FastText.Следовательно, поскольку вектор предложения представляет собой комбинацию нескольких слов, этот вектор является двумерным, а вектор всех предложений трехмерным. В алгоритме встраивания слов количество слов в предложении сопоставляется с количеством векторов. Когда количество векторов другое, «0» добавляются для заполнения количества недостающих слов для сопоставления с количеством векторов. Кроме того, для контролируемого обучения модели LSTM для каждых данных требуется метка. В этом исследовании, если предложение содержало ненормативную лексику, метка была установлена как «1», а если ненормативной лексики не было, метка была установлена как «0».
3.3.2. Метод обучения LSTM
Для обучения модели LSTM трехмерный вектор был установлен как X , а метка, содержащая «0» и «1», была установлена как y . Для гиперпараметров LSTM, как показано на рисунке 2 и в таблице 4, единицы были установлены на «1», временной шаг был установлен на 25, что является количеством слов, а функция была установлена на 100, что является числом. размеров, используемых для обучения FastText. Для гиперпараметров Dense единицы были установлены на «1», а сигмовидная функция была установлена как функция активации.
|
3.3.3. Обнаружение ненормативной лексики
Следующие таблицы демонстрируют точность результатов обнаружения ненормативной лексики. В таблице 5 показаны результаты предложений с ненормативной лексикой и без ненормативной лексики. В Таблице 6 даже для случаев, когда ядро слова «Ссибал (фк)» преобразовано в такие слова, как «Ссуибал» или «Ссуибал-намах», результаты показывают правильное определение ненормативной лексики.
| ||||||||||||
※ O : определено как нечестивое; X : определено как непристойное. | ||||||||||||
| ||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||